








--->更多内容,请移步“鲁班秘笈”!!<---
“继用于图像的Meta Segment Anything Model (SAM)取得成功之后,我们发布了SAM 2,这是一种用于在图像和视频中实时进行对象分割的统一模型,已经达到最先进的性能。” 模型适用于增强现实(AR)、虚拟现实(VR)、机器人、自动驾驶车辆和视频编辑等需要时间定位的应用。

SAM
分割是计算机视觉的重要组成部分,用于识别哪些图像像素属于物体。它在各种现实世界场景中都有应用,从分析科学图像到编辑照片。最早在2023年,Meta宣布了Segment Anything项目,发布了Segment Anything模型 (SAM) 和Segment Anything 1B的MaskLet数据集 SA-1B,以加速该领域的研究。
Meta发布的Segment Anything Model 2 (SAM 2)比原来的SAM更准确,速度快六倍。目前支持视频和图像中的对象分割。它专为图像和视频中的对象分割而设计,通过支持实时处理和zero-shot的泛化、可提示的模型架构,在处理复杂的视觉数据方面表现出色。

SAM 2的主要特点:
-
SAM 2可以分割以前从未遇到过的物体,表现出强大的零样本泛化能力。它在17个零样本视频数据集的交互式视频分割方面明显优于以前的方法,并且需要的人工交互大约减少三倍。
-
SAM 2在其23个数据集的零样本基准测试套件上优于SAM,同时速度快 6倍。
-
与之前最先进的模型相比,SAM 2在现有的视频对象分割基准测试(DAVIS、MOSE、LVOS、YouTube-VOS)方面表现出色。
-
模型实现了实时推理速度,每秒处理大约44帧。这使得SAM 2适用于需要即时反馈的应用,例如视频编辑和增强现实。
-
用于视频分割注释的SAM 2比使用SAM进行手动每帧注释快 8.4倍。
SAM 2在Apache 2.0许可下可用,因此任何人都可以在SAM 2模型之上构建自己的体验。目前Meta已经开放如下资料:
-
SAM 2代码和权重在宽松的Apache 2.0许可证下。
-
BSD-3许可证下的 SAM 2评估代码。
-
SA-V数据集,包括 ~51k真实世界视频和超过600k个Masklet,采用 CC BY 4.0许可。
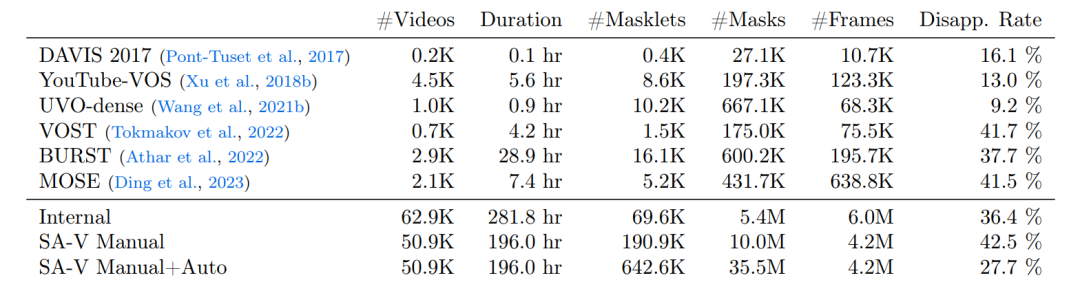
上面的表格为本次使用的数据集和开源VOS数据集的对比,比较的维度又视频数量、持续时间、掩码数量、掩码、帧数和消失率。SA-V Manual仅包含手动注释的标签。SA-V Manual+Auto将手动注释的标签与自动生成的掩码相结合。

模型架构
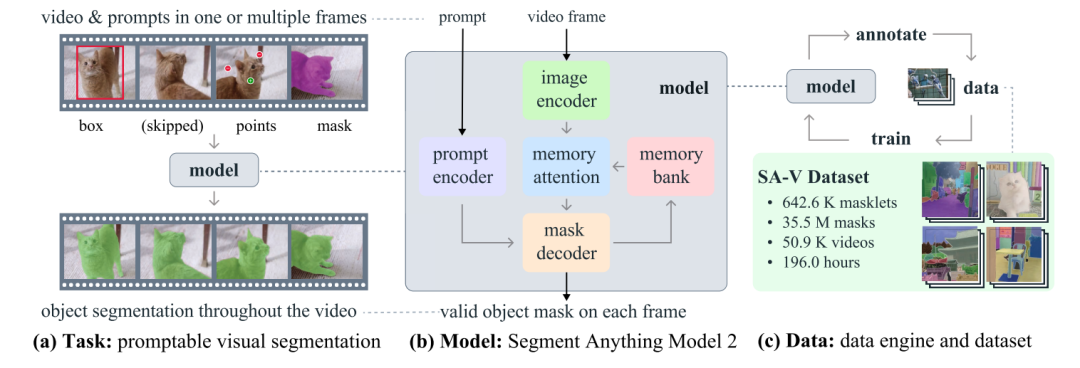
下图为SAM2的框架,希望通过使用基础模型 (b) 解决交互式的视觉分割任务 (a),这个模型是在数据引擎 (c) 上面采集到的大规模SA-V的数据集上训练而成。SAM 2通过流式存储存储先前的Prompt和预测结果,进而达到能够通过一个或多个视频帧上的Prompt(点击、框或蒙版)的方式分割区域<形成遮罩!>。
下图为一个具体的例子,先在视频的第一帧中对目标对象进行Prompt以获得该对象的分割结果。绿色点表示正提示(正向提示,表示对象的一部分),红色点表示负提示(负向提示,表示不是对象的一部分)。SAM 2 会自动将分割结果传播到后续帧(用蓝色箭头表示),形成一个MaskLet(绿色部分)。如果SAM 2在某一帧后(例如第 2 帧之后)失去了对对象的跟踪,可以在新帧中提供额外提示(红色箭头),以纠正MaskLet。
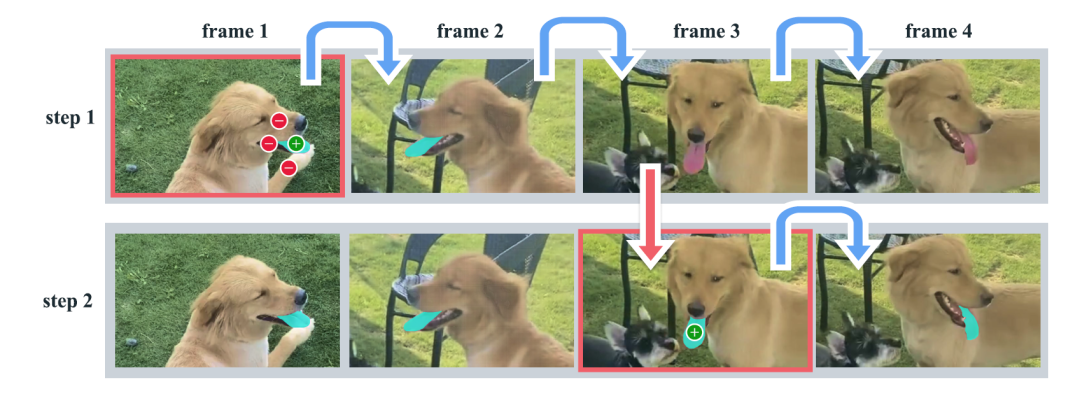
第3帧中只需一次点击即可恢复对象,并将其传播以获得正确的 MaskLet。与独立的SAM +视频跟踪器方法相比这种方法更高效。传统方法在第3帧中需要多次点击以重新注释对象。SAM 2的记忆功能使得仅需一次点击即可恢复对象(如舌头)的分割结果。这种能力在处理视频中的对象不仅减少了用户的操作次数,还能在对象跟踪失效时快速精校。

若从模型架构上来解释的话,对于给定帧分割预测取决于当前提示和/或先前观察到的记忆。视频以流式方式处理,图像编码器(绿色)一次消耗一个帧,并与先前帧中的目标对象的记忆(粉色)交叉关注<蓝色部分,Cross-Attention,其本质上也是利用了多层的Transformer堆叠>。掩码解码器(橙色)(也可以选择接受输入提示)进行当前帧的分割遮罩预测。
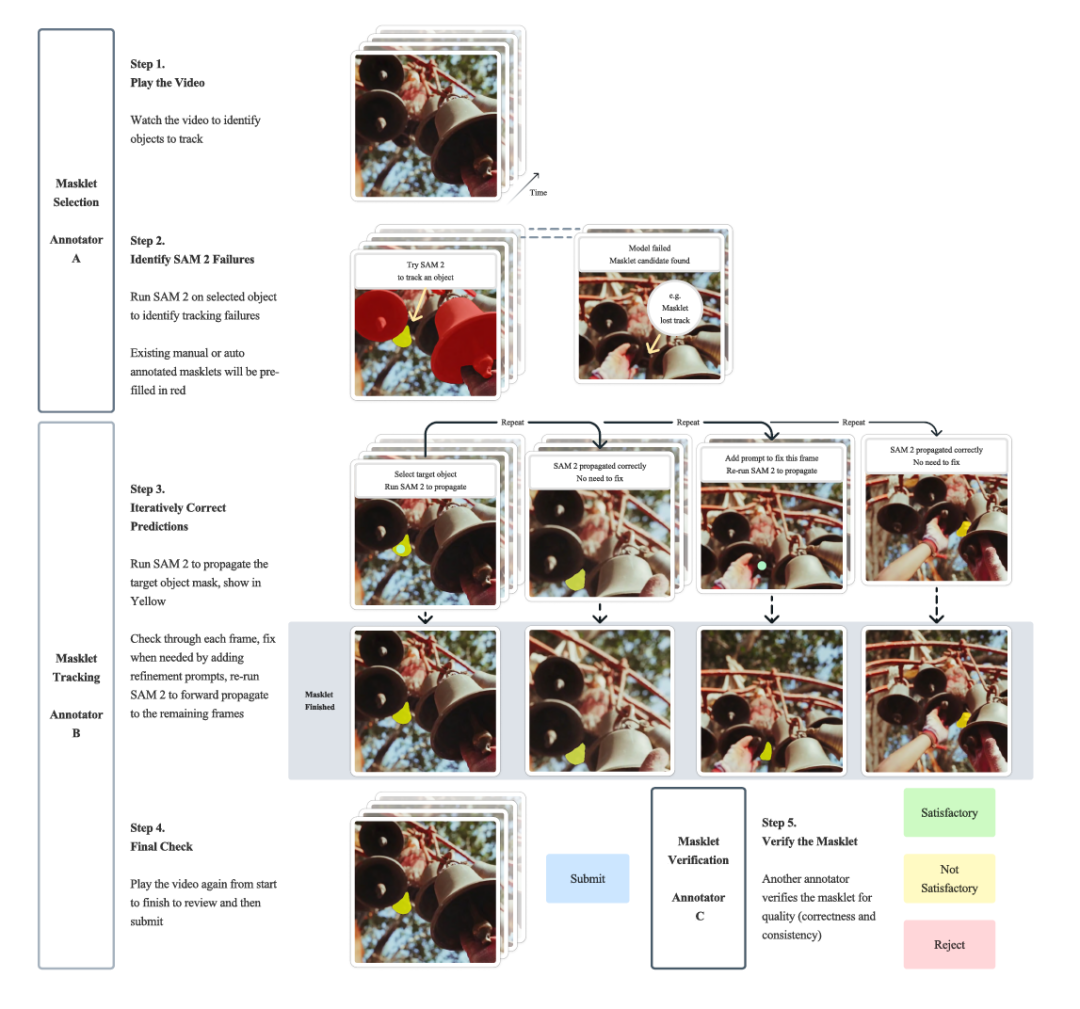
上图为标注过程,每个过程都有自己的标注器,跟踪,识别错误,持续校正
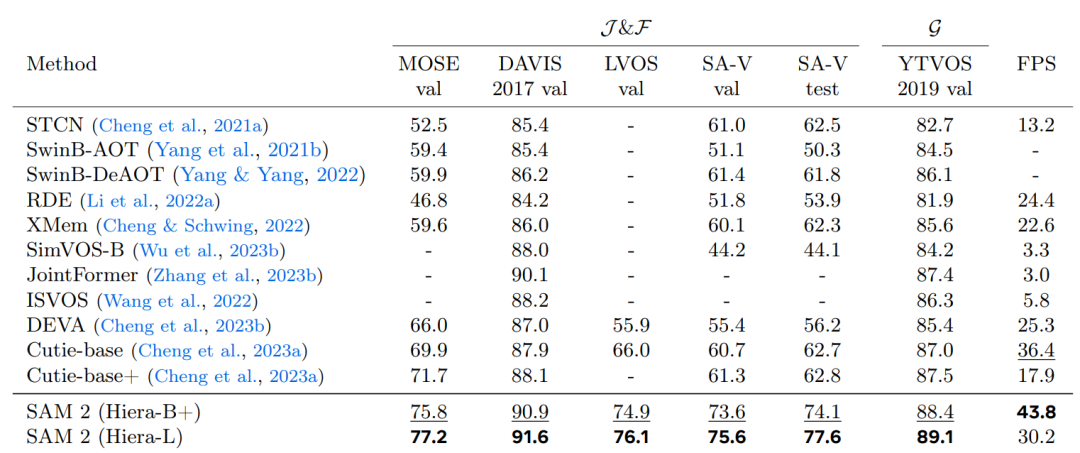
与之前的工作进行比较,SAM 2在给出第1帧的真实遮罩之后进行的视频分割方面表现良好,尤其在准确度(J &F、G)和速度(FPS)方面。所有 FPS 估计值均基于A100 GPU。















 2235
2235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









