







--->更多内容,请移步“鲁班秘笈”!!<---

并行策略
正如和分布式一样,如何利用多设备和多硬件也是很重要的一个环节。大模型训练也是如此,如今训练大模型离不开各种分布式并行策略,常用的并行策略包括:
-
数据并行(data parallelism, DP):假设有N张显卡,每张显卡都加载完整的模型,每一次迭代(iteration/step)都将一个批次的训练数据据分割成N份系统大小的小批次(micro-batch),每张显卡按照自身拿到的小批次数据进行独立的计算梯度,然后调用AllReduce计算梯度均值,进而达到所有的卡的参数更新后始终保持一致。
下图为其中一种算法,将所有的梯度分为五份,然后按照圆圈的方式传播(而不是广播数据)累加,直到每个GPU都完成一个部分的累加,然后再批量同步数据。
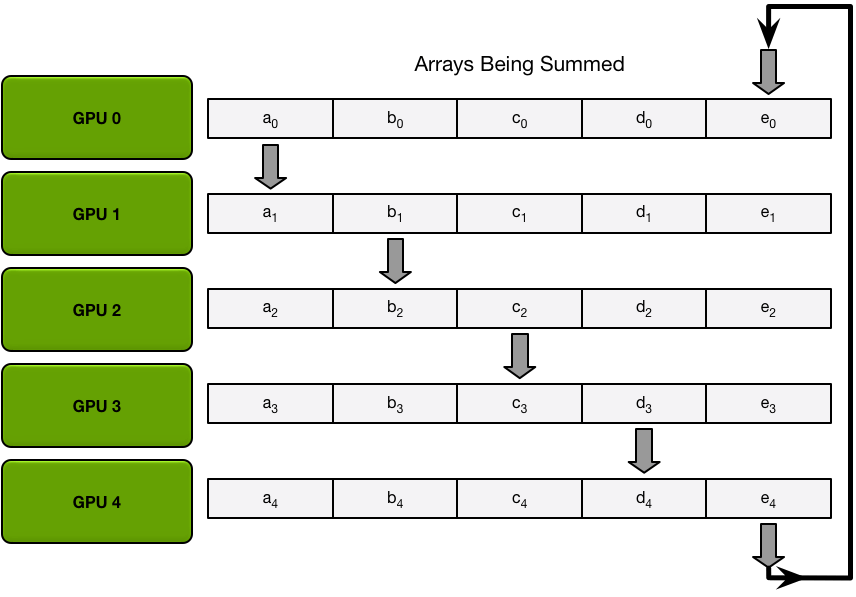
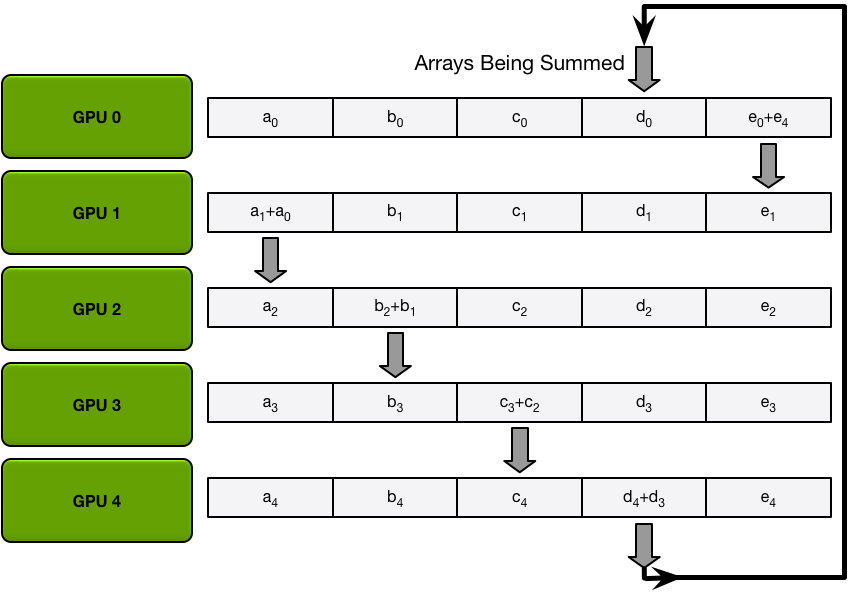
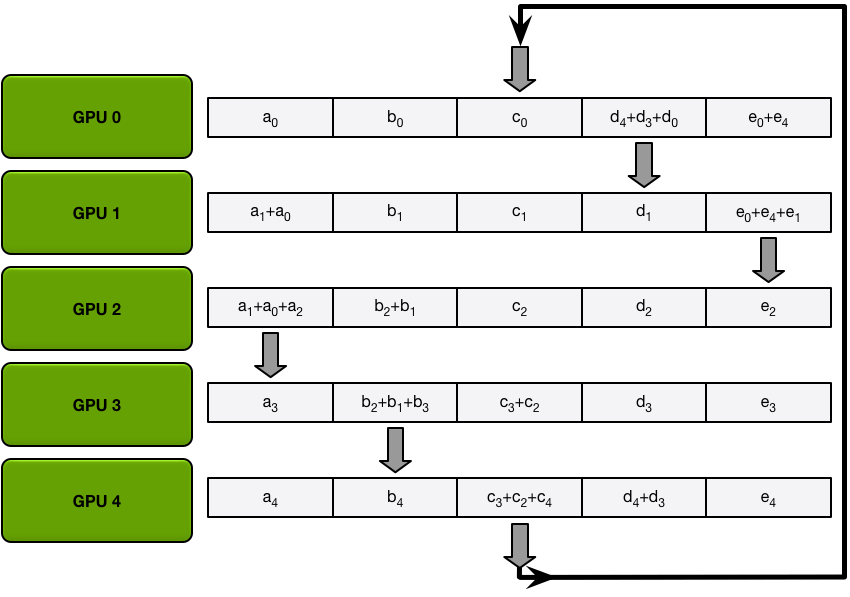
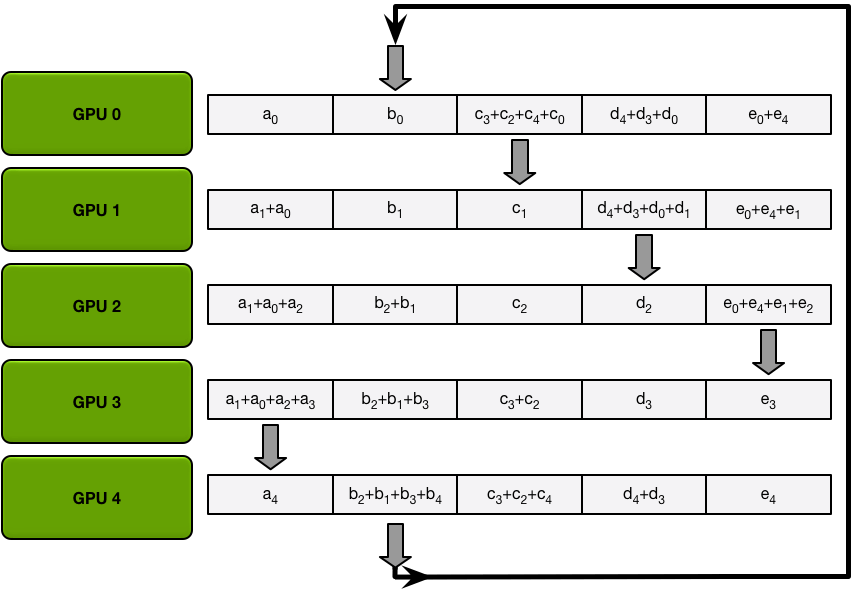
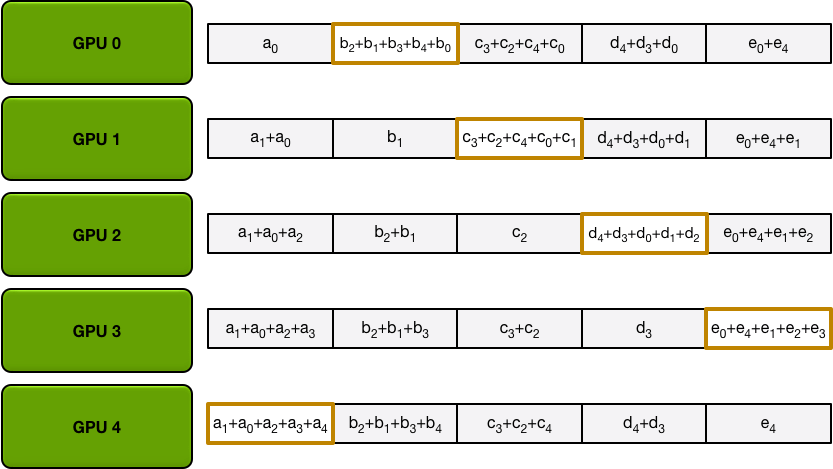
经过五次循环之后,每个GPU再将各自负责的那部分数据直接同步给其他显卡,避免多次广播运算。
-
模型并行(model parallelism/tensor parallelism, MP/TP):有的模型tensor/layer很大,单张卡无法加载,因此将tensor切分多块,一张显卡存其中一块。
-
流水并行(pipeline parallelism, PP):按照神经网络按层进行切割,划分成多个小组,一张显卡存放一组。
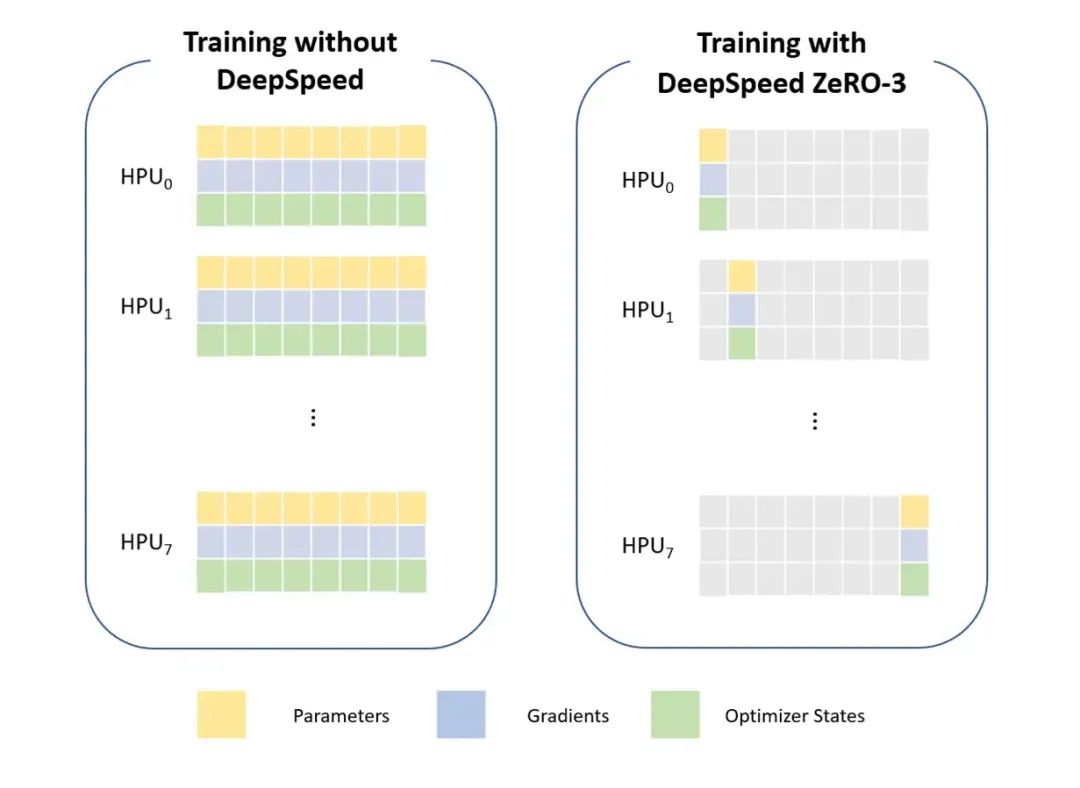
由于数据并行简单易实现,应用最为广泛。然而每张显卡都存储完整的模型,此时显存大小成为了瓶颈。例如若存在2张显卡,那么系统中就存在2份模型参数,如果有4张卡,那么系统中就存在4份模型参数,如果有N张卡,系统中就存在N份模型参数,而其中N-1份其实都是冗余。那么有新的办法来解决这个问题没有,ZeRO就是其中的一种方法。

初识ZeRO
零冗余优化器(Zero Redundancy Optimizer,简称ZeRO)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO可以在当前一代GPU集群上训练具有100B参数的深度学习模型,吞吐量是当前最佳系统的吞吐量的三到五倍。它还为训练具有数万亿个参数的模型提供了一条清晰的路径,展示了深度学习系统技术的前所未有的飞跃。同时ZeRO也被集成到了DeepSpeed,它是用于加速分布式深度学习训练的高性能类库。
在搞清楚ZeRO之前需要先明白在模型训练时候,显卡的占用情况。一般而言,模型在训练的时候会不断地更新参数,目前采用的都是梯度下降法。而混合精度训练(mixed precision training)和Adam优化器基本上已经是目前训练模型的标配。
Adam在SGD基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)1。混合精度训练,字如其名,同时存在fp16和fp32两种格式的数值,其中模型参数、模型梯度都是fp16,此外还有fp32的模型参数,如果优化器是Adam,则还有fp32的momentum和variance。
<大白话, Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重!!>
回过头来看看显卡中的数据分类,一般而言可以分为两类:
-
模型状态(Model States)由模型参数(fp16)、模型梯度(fp16)和Adam状态(FP32的模型参数副本,FP32的Momentum和FP32的Variance)。
假设模型参数量为Φ ,则共需要2Φ+2Φ+(4Φ+4Φ+4Φ)=4Φ+12Φ=16Φ 字节存储空间。从这个统计中可以发现,其实Adam优化器占据了75%的空间。<若读者要微调3B的模型,那么则需要48B的空间!!!>
-
剩余状态(Residual States): 除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
ZeRO是为了克服数据并行性和模型并行性的局限性,同时实现两者的优点。它通过在数据并行进程中对模型状态(参数、梯度和优化器状态)进行分区,而不是复制它们,从而消除了数据并行进程之间的内存冗余。同时采用动态通信计划在分布式训练设备之间共享必要的状态,以保持数据并行性的计算粒度和通信量。

如何来解读上图,蓝色就代表模型参数数Φ(若每个参数类型是FP16,则为2Φ字节),橙色代表模型梯度数Φ,K为优化器Adam的参数量系数,即KΦ。
-
第一行是没有任何优化的情况下,假如训练的模型规模为7.5B,则单卡需要120G的内存。
-
ZeRO首先进行分区的是模型状态中的Adam优化器,也就是上图第二行的Pos ,这里os指的是optimizer states。模型参数(parameters)和梯度(gradients)仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是4Φ+12Φ/N字节,当N比较大时,趋向于4Φ,也就是原来16Φ的1/4 。这个时候单卡内存需求量降低到31.5G。
-
若继续对模型梯度进行分区,也就是第三行的Pos+g ,模型参数仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是2Φ+(2Φ+12Φ)/N,当N比较大时,趋向于2Φ ,也即是原来16Φ的1/8。这个时候单卡内存需求量再次降低到16.66G。
-
最后若继续对模型参数进行分区,也就是最后一行的Pos+g+p ,此时每张卡的模型状态所需显存是16Φ/N,当 N比较大时,趋向于0。这个时候单卡需要的内存量仅仅需要1.9G。
在DeepSpeed的训练框架中, Pos对应ZeRO-1, Pos+g对应ZeRO-2, Pos+g+p对应ZeRO-3,而一般在生产中ZeRO-1就足够使用。















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









