






Nvidia 发布 Parakeet V2,一款新的开源自动语音识别 AI,核心亮点:一秒钟转录一小时的音频;Open ASR 上的顶级模型,击败了 ElevenLabs 的 Scribe 和 OpenAI 的 Whisper;6.05% 的单词错误率;CC-BY-4.0 许可下可用。
添加图片注释,不超过 140 字(可选)
基本信息:基于 FastConformer-TDT 架构,有 6 亿参数,用于高质量英语转录,支持标点、大小写和时间戳预测,遵循 CC-BY-4.0 许可,可全球部署。适用于需要语音转文本功能的开发者、研究人员、学者和行业。
添加图片注释,不超过 140 字(可选)
输入输出:输入为 16kHz 单声道音频,支持.wav 和.flac 格式;输出为包含标点和大小写的文本字符串。
使用方法:需安装 NVIDIA NeMo,可在 NeMo 工具包中使用,也能作为预训练检查点进行推理或微调。示例代码展示了如何自动实例化模型、转录音频以及获取带时间戳的转录结果。
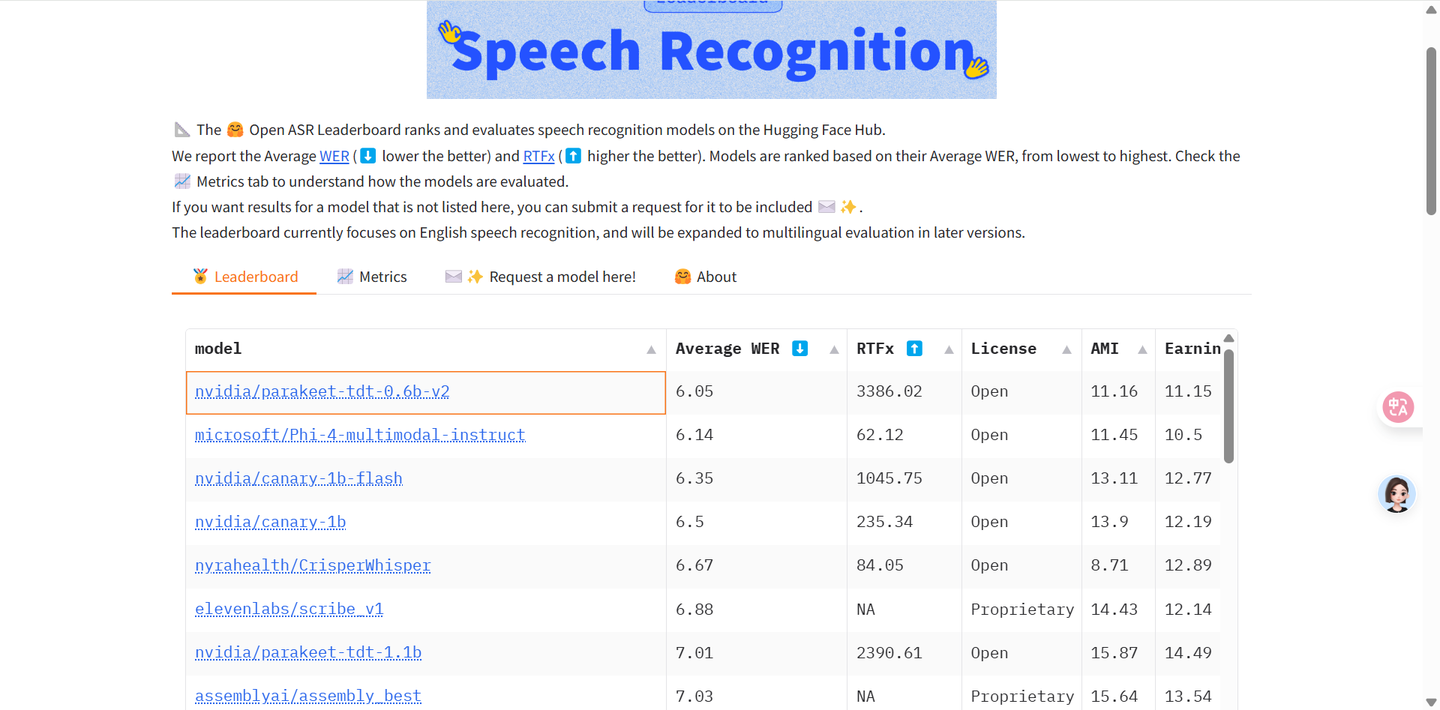
训练与评估:使用 NeMo 工具包训练,从 LibriLight 数据集预训练的 wav2vec SSL 检查点初始化,在多种数据集上训练,包括 10000 小时人工转录数据和 110000 小时伪标记数据,训练数据包含多种噪声源。评估使用 Huggingface Open ASR Leaderboard 数据集,性能指标为词错误率(WER)。模型在不同数据集上的平均 WER 为 6.05%,在噪声鲁棒性和电话音频性能方面也有相应测试结果。
添加图片注释,不超过 140 字(可选)
性能表现
-
基础性能:在多个数据集上进行测试,平均词错误率(WER)为 6.05% 。
-
噪声鲁棒性:随着信噪比降低,WER 有所上升。
-
电话音频性能:相比标准 16kHz 音频,μ-law 8kHz 音频的 WER 略高。
推理:使用 NVIDIA NeMo 引擎,支持多种 NVIDIA 硬件进行推理测试。
伦理考量:开发者应确保模型符合行业和用例要求,避免产品滥用。在偏差、可解释性、隐私和安全方面有相关说明,如未采取缓解偏差措施、模型输出可能不准确、训练数据有来源证明、数据标注符合隐私法但无法满足外部数据主体的修改或删除请求等。


















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











