







1、场景业务问题
现实业务问题中,时常会遇到一些业务模型【如信贷风控a/b/c卡模型、广告领域的CTR等模型】,我们一般的处理逻辑是: 梳理抽象业务问题为数据问题 -> 整理样本数据 -> 训练模型 -> 模型测试验证 -> 模型上线部署。如果我们用的模型是逻辑回归模型,则无需进行模型校验,而如果我们使用数模型 或者 深度学习模型,实际predict出来的概率并不是真正的“好人”或“坏人”概率,需要进行模型校准。
在执行分类时,我们通常不仅希望预测类标签,而且还希望获得相应标签的概率。这个概率让我们对预测更有信心。有些模型对类概率的估计很差,有些甚至不支持概率预测(例如,SGDClassifier的一些实例)。校准模块可以更好地校准给定模型的概率,或添加对概率预测的支持。经过良好校准的分类器是概率分类器,对于这种分类器,predict_proba方法的输出可以直接解释为置信水平。例如,一个校准良好的(二元)分类器应该对样本进行分类,在它给出的predict_proba值接近0.8的样本,大约有80%(的置信度)实际上属于阳性类别。
备注: 数值在0与1之间不代表它就是概率!当预测的概率反映了真实情况的潜在概率时,这些预测概率被称为“已校准”
2、模型校准前奏:偏差可视化
reliability diagram,这是一种相对简单而且常用的可视化方法,用它能大致评估出当前模型的输出结果与真实结果有多大偏差。如下面这段介绍,如果能得到斜率为45度的线,那么意味着模型输出的结果是有效的估计。
On real problems where the true conditional probabilities are not known, model calibration can be visualized with reliability diagrams (DeGroot & Fienberg, 1982). First, the prediction space is discretized into ten bins. Cases with predicted value between 0 and 0.1 fall in the first bin, between 0.1 and 0.2 in the second bin, etc. For each bin, the mean predicted value is plotted against the true fraction of positive cases. If the model is well calibrated the points will fall near the diagonal line.
样例如下:(一般而言,如果模型是一条斜45直线,则校准可以考虑忽略,加持) 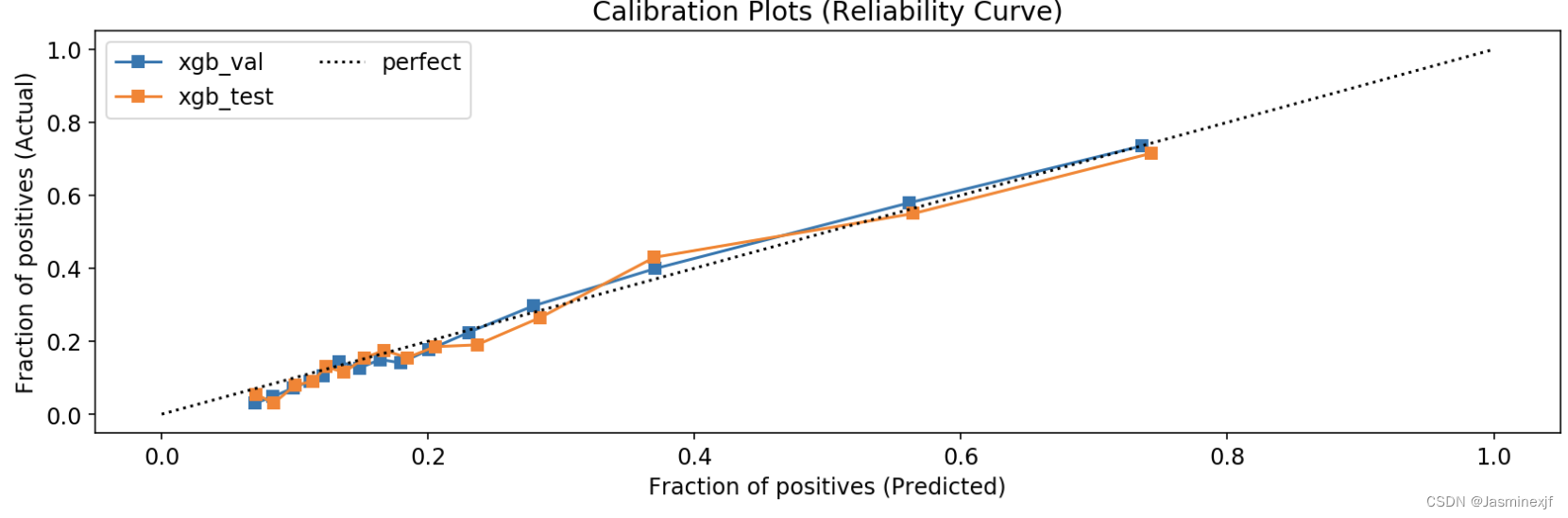
【】
3、模型校准方法
现在主流的模型校准算法有:Platt scaling[1] 和 Isotonic regression[2]。Platt scaling使用LR模型对模型输出的值做拟合(并不是对reliability diagram中的数据做拟合),适用于样本量少的情形。Isotonic regression则是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2951
2951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









