






Joint Prostate Cancer Detection and Gleason Score Prediction in mp-MRI via FocalNet
基于mp-MRI的用于前列腺癌检测和Gleason评分预测的FocalNet网络
0 储备知识
0.1 Gleason分级
Gleason分级是一种被广泛采用的 前列腺癌组织学分级 的方法。
介绍Gleason分级系统之前,需要先了解肿瘤的分化。分化是指从胚胎时的幼稚细胞逐步向成熟的正常细胞发育的过程,所谓肿瘤细胞分化程度就是指肿瘤细胞接近于正常细胞的程度。一般情况下,癌组织分化越高,形态上就与正常组织越接近。

0.1.1 肿瘤组织的分化
- 肿瘤组织分化可分为高、中、低分化和未分化几种。
① 瘤体中的癌细胞分化越接近其来源组织的形态,则越成熟,通常称为高分化。
② 瘤体中的瘤细胞分化太差,极不成熟,或看上去明显异常于正常细胞,但仍保留某些来源组织的痕迹,则称为低分化。
③ 界于两者之间的称为中分化。
④ 还有一类特例的癌细胞,有些癌细胞分化太差,根本找不到来源组织的征象,则称为未分化。 - 不同分化程度所预示的肿瘤危害程度:
高分化肿瘤,恶性程度低,生长慢,转移率低,预后较好;
低分化肿瘤,恶性程度高,生长快,转移率高,预后较差;
未分化肿瘤,恶性程度极高,预后最差。
分化程度较低,恶性程度高,生长速度快的恶性肿瘤前五位分别为:胰腺癌、脑肿瘤、食管癌,肝癌和黑色素瘤。这五类恶性肿瘤增殖速度极快,危险性较高。 - 根据肿瘤组织的分化程度,确定了 癌症分级体系 :
多数的分级系统将肿瘤分化程度分为3至4级。分级 Grade 定义 I级 (G1) 即高分化,细胞分化程度较好。一般来说,G1的肿瘤细胞分裂速度较慢。 II级 (G2) 即中分化,细胞分化程度居中。 III级 (G3) 即低分化,细胞分化程度较差。 IV级 (G4) 未分化

0.1.2 Gleason分级与积分体系
-
Gleason分级体系采用与预后密切相关的五级法。
分级 特征 leason 1级(很少见) 一致性规则的大腺体,背靠背密集,形成小结节。(高分化) leason 2级 较不规则的大腺体,背靠背密集,形成小结节,结节内腺体不融合。 leason 3级 浸润性生长的小腺体或腺泡,或小型筛状结构腺体。 leason 4级 融合腺体,大型筛状腺体,或呈肾透明细胞癌样。 leason 5级 实性癌巢(无腺样结构),单个癌细胞浸润,或呈粉刺样癌(癌细胞坏死)。(未分化) -
评分体系
由于前列腺癌在组织病理学上不均一现象普遍存在,即同一标本内常见 1 种以上的组织结构形式,表现为不同的分级区域,即在 1 种主要结构类型之外,还有 1 种次要结构类型。主要结构类型是癌区内最常见的类型;次要结构类型是癌区内第二常见的类型且占检查标本的 5% 以上。具有 2 种结构类型的前列腺腺癌 Gleason 评分=主要结构类型(级别)+次要结构类型(级别); 而对于只有 1 种 Gleason 结构类型的前列腺腺癌,一般将其主要结构类型和次要结构类型视为完全一致。前列腺癌主要和次要区域分级(亚评分)相加,即得到这一标本的 Gleason 评分(总分)。
① 根据腺体分化程度,按5级评分(第1级1分,分化好;每递升1级增加1分;第5级5分,为未分化)。
② Gleason评分=主要结构类型分级+次要结构类型分级。
对于同一肿瘤不同区域腺癌结构的变异,按其主要和次要分化程度分别评分,以该两项评分相加的总分作为判断预后的标准(例如腺癌主要结构评为2分,次要结构评为4分,则积分为2+4=6分;只有1个结构类型,评分为3分,则积分为3+3=6分;穿刺活检见3个结构类型以上且最高级别结构数量少时,一般将最高级别作为次要结构类型)。
③ 积分为2、3、4分者相当于高分化腺癌;5、6、7分者相当于中分化腺癌;8、9、10分者相当于低/未分化癌。
④ Gleason分级适用于前列腺腺癌,不适用于腺鳞癌、尿路上皮癌。
====== 文献阅读记录 ======
Abstract
——
多参数磁共振成像(Multi-parametric MRI, mp-MRI)被认为是诊断前列腺癌(prostate cancer, PCa)的最佳无创性影像检查方法。然而,mp-MRI用于前列腺癌诊断目前受到定性或半定量解释标准的限制,导致读者之间的差异性和评估病变侵袭性的次优能力。卷积神经网络(CNNs)是自动学习各种任务的鉴别特征的有效方法,包括癌症检测。我们提出了一种新的多分类卷积神经网络FocalNet ,用于联合检测PCa病变并使用 Gleason score (GS) 预测其侵袭性。 FocalNet能够表征病变侵袭性,并充分利用mp-MRI的独特知识。
我们收集了 417 名进行了机器人辅助腹腔镜前列腺切除术(robotic-assisted laparoscopic prostatectomy, RALP)患者的术前3T mp-MRI前列腺检查数据。FocalNet在这个研究组中接受了 5 次交叉验证的训练和验证。
① 在病灶检测的自由响应受试者工作特征 (FROC) 分析中,FocalNet对于index lesions和clinically significant lesions的灵敏度分别为89.7%和87.9%。
② 在 GS 分类的接受者操作特性 (ROC) 分析中, FocalNet received the area under the curve (AUC) of 0.81 and 0.79 for the classifications of clinically significant PCa (GS≥3+4) and PCa with GS≥4+3, respectively.
与使用当前诊断指南的放射科医生的预期表现相比, FocalNet 对指标性病变和有临床意义的病变表现出类似的检测灵敏度,仅比经验丰富的放射科医生低3.4%和1.5%,但无统计学意义。
关键字:前列腺癌;MRI;计算机辅助检测与诊断(CAD);CNN
I. INTRODUCTION
——
前列腺癌诊断面临的挑战是如何检测和区分惰性前列腺癌和潜在的有临床意义的前列腺癌。目前对病变侵袭性的最佳评估是使用Gleason score(GS)。目前,医疗实践中对PCa的诊断仍然依赖于非靶向模板驱动的经直肠超声引导(TRUS)活检,这导致了clinically significant PCa的漏检。3T mp-MRI结合了解剖学和功能信息,在PCa的诊断中发挥着关键作用,因为它减少了不必要的活检,增加了主动监测和局部治疗的治疗选择。mp-MRI的核心部分包括T2加权成像(T2W)、扩散加权成像(DWI)和动态对比增强成像(DCE-MRI),每种成像都能提供不同的信息。目前mp-MRI的诊断实践遵循前列腺成像报告和数据系统(PI-RADS v2),它以定性或半定量的方式评估放射学发现。然而,PI-RADS v2检测和区分惰性和临床有意义的PCA的能力仍然有限,敏感性和特异性范围广,主要是由于读者间差异和次优分析。
研究现状:
基于mp-MRI的计算机辅助诊断(CAD)技术正被积极研究用于PCa病变的检测和分类。病变检测方法通常从mp-MRI中提取体素级和区域级特征,并预测PCa定位点或病变分割掩码。卷积神经网络(CNNs)是图像分类和分割的有力工具。最近的研究显示了训练CNN从mp-MRI中检测癌症的可行性。Zhang等人设计了从粗到精的分层CNN来分割体素水平的肿瘤掩膜,并从DCE-MRI中建议乳腺癌的活检位置。Song等人建立了一个基于补丁的CNN,对活检证实的PCA病变和非病变感兴趣区(ROI)进行分类。Kiraly等人提出使用双输出通道的CNN来预测clinically significant PCa(GS>6)和non-clinically-significant PCa(GS≤6)的体素水平标签,以便能够同时进行检测和分类。
解释前列腺mp-MRI通常需要高水平的专业知识,因为放射学结果是定性的,依赖于T2形态学与扩散限制和病变增强的非定量评估。因此,MP-MRI的一个部分的放射学表现比其他部分更容易观察到。在CNN中利用mp-MRI的多个分量的常见方法是将它们作为不同的成像通道叠加(e.g., RGB channels for a color image)。这使得CNN能够从groundtruth注释中学习跨MP-MRI组件的共同知识,但是可能无法从MP-MRI的每个组件学习不同的信息。因此,一些只出现在mp-MRI的一个或某些成分中的特征很难训练,特别是在训练数据数量有限的情况下。受前列腺MP-MRI临床解释的启发,我们设计了相互发现损失(MFL)来针对MP-MRI的不同成像成分进行选择性训练。MFL识别哪个组件子集将包含给定PCA发现的更多可观察信息,并且定义损伤特定的训练目标,以仅从成像组件子集观察PCA发现。
临床上有意义的PCa的分层变得很重要,因为区分低级别和中/高级别的PCa与临床结果高度相关。已有研究证明mp-MRI与GS的相关性,但据我们所知,还没有研究利用mp-MRI通过CNNs预测细粒度的GS组。
① 尽管使用多分类CNN通过one-hot编码得到了广泛的应用,但通常假设不同的类别距离是相等的,这忽略了GS组的进步性。例如,假设低级和中级PCA之间的差异与低级和高级PCA之间的差异相同。
② 取而代之的是,我们为不同的GS组开发了顺序编码,将病变侵袭性关系引入到编码的向量中。与单热点编码矢量不同,有序编码矢量不是相互正交的,并且可以暗示不同GS组之间的相似和不同。
两种不同的编码防方式如下图所示:

目前用于PCa检测的CAD系统一般是使用mp-MRI检查和活检证实的病变来进行训练和验证的。然而,由于活检核心大多基于磁共振阳性发现(PI-RADS≥3),活检证实的病变注释偏向于MRI阳性病变。由于PI-RADSCAD≥3对所有病变的检测能力有限,mp-MRI可能会漏掉临床上有意义的病变,并可能严重低估多灶性病变,从而导致高估了CAD系统的性能。此外,由于前列腺活检和根治性前列腺切除术标本之间的GS有时不一致,因此存在病变注释不准确的显著风险。Epstein等人报道,超过三分之一患有GS≤6的活检病例在切除术后升级为GS≥7,四分之一的GS 3+4活检病例在与整体组织病理学检查后被降级。为了克服这些限制,我们在接受机器人辅助腹腔镜前列腺切除术(RALP)之前进行了术前mp-MRI检查,以进行训练和验证。RALP后的整体组织病理学分析将提供GS组的最佳定义,并最大限度地减少对多灶性病变的低估。
我们提出了一种新的多分类CNN——FocalNet,它联合检测PCA病变并预测它们的GS。 我们将GS分为5个细粒度GS组,即GS3+3、GS3+4、GS4+3、GS=8和GS≥9。FocalNet将以上5个GS组+正常组织共6个类别编码成顺序编码向量,并使用MP-MRI预测每个像素的标签。FocalNet还被设计成利用训练期间的相互发现损失(MFL)来选择性地训练mp-MRI的一个或某些成像组件中的独特特征。
本文贡献:
① 我们提出了一种改进的多类CNN——FocalNet,用于联合检测PCa病变并从mp-MRI中预测其Gleason score组。
② 在FocalNet中,我们设计了顺序编码来表征病变的侵袭性和相互发现损失(MFL),以充分利用多参数成像中的知识。
③ 据我们所知,这是第一项在大规模研究队列中训练或验证基于CNN的PCa检测和诊断系统的研究,该系统使用整体组织病理学证实的病变结果。
本文组织如下:
Section II:我们描述了MRI数据和注释过程,FocalNet的技术框架,以及预处理、训练和验证的实验设置。
Section III:介绍了PCA病变检测和GS预测结果。
Section IV:我们讨论了FocalNet的潜在含义和扩展,随后是结束语。
II. MATERIALS AND METHODS
A. MRI data
——
这项研究使用了包括了417名接受RALP的患者的术前mp-MRI检查。以前接受过放射治疗或激素治疗的患者不包括在内。
所有成像均在四种不同的3T扫描仪(Trio上126例,Skyra上255例,Prisma上17例,V Erio上19例;德国Erlangen的西门子医疗公司)中的一台上进行,采用标准化的临床MP-MRI方案,包括T2W和DWI参数。由于DCE-MRI在当前诊断实践中的作用有限,所以在我们的研究中将其排除。我们使用轴位(axial)T2w快速自旋回波(turbo spin-echo, TSE)成像和使用回波平面成像(echo-planar imaging , EPI)DWI序列的表观扩散系数(apparent diffusion coefficient, ADC)图。对于T2w,T2w TSE的重复时间(repetition time, TR)为3800~5040 ms,回声时间(echo time, TE)为101ms。在视野(FOV)为14 cm,矩阵尺寸为256×205的条件下,以0.55 mm×0.68 mm的面内分辨率和3 mm的通面分辨率采集并重建了无间隙的T2w TSE图像。对于DWI,我们使用的TR和TE分别为4800ms和80ms。重建图像FOV为21 cm×26 cm,矩阵为94×160,面内分辨率为
1.6
m
m
2
1.6 mm^2
1.6mm2,层厚为3.6 mm。将四幅扩散加权图像中的像素(对数尺度)与其相应的b值(
0
/
100
/
400
/
800
s
/
m
m
2
0/100/400/800s/mm^2
0/100/400/800s/mm2)进行线性最小二乘曲线拟合,得到ADC图。
作为标准临床护理的一部分,mp-MRI检查由三位泌尿生殖(GU)放射科医生(具有10年以上的前列腺MRI临床阅读经验)进行审查。报告PI-RADS≥3分的检查结果,认为为MRI阳性发现。在这项研究中,PI-RADSMRI≤2被认为是阴性。
B. Whole-mount histopathology matching & annotation
Whole-mount histopathology matching & annotation 整体组织病理学匹配及注释
如图1所示,这项研究的基本事实是RALP后整体组织病理学上的病变确认。切除的前列腺在MP-MRI的大致方向上,从顶端到底端以4~5 mm的距离进行切片。 整架标本的组织病理学检查由GU病理学家进行,所有MRI信息都是不可见的。
后来,至少有一名GU放射科医生和一名GU病理学家在每月预定的多学科会议上一起重新审查了mp-MRI和组织病理学检查。通过视觉配准,将MRI中的每个ROI与样本上的相应位置进行匹配。如果它们在mp-MRI和组织病理学切片上位于同一象限(左、右、前和后),并且在适当的节段(底端、中腺和顶段),那么MRI Positive finding被认为是True Positive;如果在组织病理学上没有发现相应的病变,则被认为是False Positive。
在多学科会议后,GU放射科研究员在GU放射科医生的指导下,回顾了每一次MP-MRI检查,参考了整体组织病理学,并对所有MRI可见的病变进行了标注。69.5%(278/400)前瞻性漏诊(假阴性)病变,在回顾中被识别,并进行了注释。由于注释的困难,MRI上不可见的病变不包括在本研究中。
我们总共标注了728个病变,包括286个GS 3+3病变、270个GS 3+4病变、110个GS 4+3病变、30个GS=8病变和32个GS≥9病变。其中93个GS 3+3病灶,204个GS 3+4病灶,98个GS 4+3病灶,26个GS=8病灶,29个GS≥9病灶被放射科医师前瞻性识别。所有注释均在T2w上。当多个病变的组织病理学分级相同时,指标性病变(index lesion)定义为GS最高或直径最大的病变,临床上有意义的病变为GS≥7的病变
| Grade | GS 3+3 | GS 3+4 | GS 4+3 | GS=8 | GS≥9 | Sum |
|---|---|---|---|---|---|---|
| Overall | 286 | 270 | 110 | 30 | 32 | 728 |
| Prospective | 93 | 204 | 98 | 26 | 29 | 450 |
注:69.5%(278/400)前瞻性漏诊(假阴性)病变,在回顾中被识别,并进行了注释,278+450=728。
 图1 数据准备流程。在400个前瞻性遗漏的(假阴性)病灶中,有278个在mp-MRI中被回顾性识别和标注,参考整体组织病理学检查。上图所示的例子中,前瞻性遗漏了左前部病变(GS3+4,指标性病变),并对其进行了回顾性识别。
图1 数据准备流程。在400个前瞻性遗漏的(假阴性)病灶中,有278个在mp-MRI中被回顾性识别和标注,参考整体组织病理学检查。上图所示的例子中,前瞻性遗漏了左前部病变(GS3+4,指标性病变),并对其进行了回顾性识别。
C. FocalNet for PCa detection and Gleason score prediction
——
FocalNet是一个端到端的多类别CNN,用于联合检测PCA病变并预测其GS。如图2所示,FocalNet将相应的T2w和ADC图像输入两个通道中,并预测六个类别的像素级标签:无损伤、GS 3+3、GS 3+4、GS 4+3、GS=8和GS≥9。 如图3所示,首先将病灶groundtruth通过顺序编码转换为5通道的groundtruth掩码,而FocalNet通过其主干CNN架构预测groundtruth掩码。FocalNet通过 关于T2w和ADC两者的焦损(FL) 和 任一imaging components中的PCa特征的相互发现损失(MFL) 来同时训练。
 图2 FocalNet用于训练和验证的工作流程。对3D图像体积进行图像配准和强度归一化。因为FocalNet处理2D图像,使用相应的T2w和ADC切片被分组并馈送到FocalNet进行像素级预测。
图2 FocalNet用于训练和验证的工作流程。对3D图像体积进行图像配准和强度归一化。因为FocalNet处理2D图像,使用相应的T2w和ADC切片被分组并馈送到FocalNet进行像素级预测。
 图3 FocalNet基本架构。使用顺序编码将lesion groundtruth转换成5通道groundtruth掩码。CNN通过其多通道像素级输出来预测掩码。Focal Loss使用ADC和T2w输入针对
f
o
u
t
f_{out}
fout训练CNN。同时,Mutual Finding Loss在前向传播中计算
L
2
A
D
C
L2_{ADC}
L2ADC和
L
2
T
2
w
L2_{T2w}
L2T2w,并训练较小的L2。
图3 FocalNet基本架构。使用顺序编码将lesion groundtruth转换成5通道groundtruth掩码。CNN通过其多通道像素级输出来预测掩码。Focal Loss使用ADC和T2w输入针对
f
o
u
t
f_{out}
fout训练CNN。同时,Mutual Finding Loss在前向传播中计算
L
2
A
D
C
L2_{ADC}
L2ADC和
L
2
T
2
w
L2_{T2w}
L2T2w,并训练较小的L2。
-
Ordinal encoding for Gleason scores:
传统的多类CNN将每个标签编码成one-hot vector,并通过多通道输出预测one-hot vector。如表I中所示,这六个不同的标签可以被转换成6比特的单热点向量,单热点编码假设不同的标签彼此无关,因此交叉点损失同等地惩罚错误分类。如表 I 中所示,这六个不同的类别可以被转换成6位的one-hot vector。one-hot编码假设不同的标签彼此无关,因此交叉熵损失同等地惩罚错误分类。然而,不同GS之间的进展性,使得GS 4+4 PCa的治疗预后更类似于GS 4+3,而不是GS 3+3,不能用one-hot编码来解释。此外,将病变分成不同的类别,每个类别中的样本数量非常有限。
我们使用顺序编码将六个类别的标注转换为5位序数向量。如表 I 所示,顺序向量的每一位标识非互斥条件,使得第k位指示标签是否属于≥k的类别。以此方式,将groundtruth编码到5通道掩码中,例如,第一通道用于指示所有病灶(区分正常与病变),第二通道用于指示临床显著性,等等。然后,CNN使用5通道对编码掩码进行预测,并且在每个输出通道的顶部应用Sigmoid函数以将输出归一化为从0到1的预测概率。即,第一输出通道自然预测病变检测概率。
给定像素的预测序号编码矢量, y = { y ^ 1 , y ^ 2 , y ^ 3 , y ^ 4 , y ^ 5 } ∈ { 0 , 1 } y = \{\hat y_1, \hat y_2, \hat y_3, \hat y_4, \hat y_5\} ∈ \{0,1\} y={y^1,y^2,y^3,y^4,y^5}∈{0,1},预测类别为最大的k,使得 y ^ i = 1 , ∀ i ≤ k \hat y_i=1,∀i≤k y^i=1,∀i≤k;如果 y ^ i = 1 , ∀ i \hat y_i=1,∀i y^i=1,∀i,则属于non-lesion类别。预测的类别也可以表达为: m a x 1 ≤ k ≤ 5 ( ∏ i = 1 k y ^ i ) ( ∑ i = 1 k y ^ i ) max_{1≤k≤5}(\prod_{i=1}^k\hat y_i)(\sum_i=1^k\hat y_i) max1≤k≤5(∏i=1ky^i)(∑i=1ky^i)。
序号编码表征了不同标签之间的关系。例如,GS=8与GS 4+3共享4位,而与无损伤仅共享1位。标签之间的共性和差异被表示为序数向量中的共享的和不同的位。因此,序号编码使得多分类CNN可以同时学习所有病变的共性和不同GS之间的区别。此外,尽管有序编码不会直接增加样本的数量,但它对不同的标签进行了分组,因此与单热编码相比,每个通道都有更大的联合病变群体。 -
Focal loss for ordinal encoding:
在像素级的groundtruth中,PCA病变和非病变的标记是非常不平衡的。在我们的数据集中,非病变像素数与病变像素数之比为62:1。对GS进行顺序编码后,groundtruth掩码的正比特率仅为0.77%。结果,通过平均考虑病变和非病变像素,交叉熵损失被压倒性数量的非病变项占据,其中许多项来自容易预测的非病变像素。另一方面,与病变相关的元素则很少被强调。
我们使用Focal Loss(FL)来平衡病变和非病变像素之间的学习。FL将焦点权重 ( 1 − p T ) 2 (1−p_T)^2 (1−pT)2添加到二进制交叉熵损失,其中 p T p_T pT是真实类别的预测概率。这使得高置信度的真实预测对总损失的贡献要小得多。例如,清晰的非病变像素(如:具有高ADC强度或在前列腺外部)预测为非病变类别的概率为95%,其对标准交叉熵损失的贡献率为0.022,而对FL的贡献率仅为 5.6 × 1 0 − 5 5.6×10^{−5} 5.6×10−5。通过降低容易预测的像素的权重,训练可以集中在可疑或难以预测的像素上。
FL还适用于顺序编码。对于给定的像素,令 y → = ( y 1 , y 2 , y 3 , y 4 , y 5 ) ∈ { 0 , 1 } \overrightarrow{y}=(y_1, y_2, y_3, y_4, y_5)∈\{0,1\} y=(y1,y2,y3,y4,y5)∈{0,1}为groundtruth编码向量,其对应的5通道预测概率向量为 p → = ( p 1 , p 2 , p 3 , p 4 , p 5 ) ∈ [ 0 , 1 ] \overrightarrow{p}=(p_1, p_2, p_3, p_4, p_5)∈[0,1] p=(p1,p2,p3,p4,p5)∈[0,1]。然后,每个像素的Focal Loss为:
q是定义为预测概率与五个通道中的基本事实之间的最大差值的焦点权重,使得: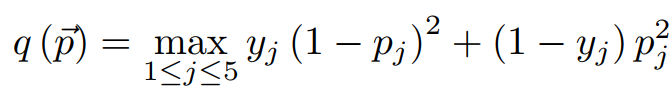
这样,如果高级别病变被遗漏或降级,它们将获得较大的焦点权重,因此高级别病变也可以得到更好的病变检测关注。此外, α \alpha α是一个常数,它控制假阴性和假阳性预测之间的惩罚。我们发现,由于良性非病变的发现,如良性前列腺增生和良性腺瘤,有时具有与PCa病变相似的外观,因此在PCa检测中对假阳性的惩罚较小是可取的。对假阳性的较大惩罚将会阻碍了真阳性PCa特征的学习。 此外,在计算FL之前,对焦点权重q应用了最大空间池化滤波器,以保持病灶边界附近阳性和阴性像素的一致权重。在我们的实践中,为了获得更好的灵敏度, α \alpha α设置为0.75,最大池化滤波器大小设置为3×3。 -
Mutual finding loss for multi-parametric imaging:
在解释前列腺mp-MRI的过程中,放射学发现最初是在单个参数确定的,后来在参考其他成像参数后巩固或拒绝。然后,PI-RADS v2评分主要基于该发现在明确描述该发现的特定成像组件中的可疑性进行评估。因此,CAD系统还需要根据单个成像参数以及mp-MRI的多个成像参数之间的对应关系来确定PCa病变。
潜在的挑战是mp-MRI的不同组件捕获不同的信息,并且只有一部分信息在所有组件之间共享。 因此,在一个组件中可观察到的结果在其他组件中可能部分/不可观察到。在端到端训练期间,具有叠加成像组件的CNN可以有效地学习跨组件的共同特征,但是没有机制来训练仅在特定成像组件中可观察到的特征。
相互发现损失(Mutual finding loss, MFL)用于识别包含不同PCA特征的特定成像分量,并在识别的分量中训练PCA特征。
首先,在给定训练切片的情况下,MFL确定单独使用T2w还是ADC可以为groundtruth病变提供更多信息。如图3所示,T2w和ADC被单独传递到同一个CNN,并带有一个全为零的空白图像来替换另一个组件。我们将来自单独使用ADC或T2w的CNN预测输出 f A D C = f ( I A D C , I b l a c k ) , f T 2 w = f ( I b l a c k , I T 2 w ) f_{ADC}=f(I_{ADC},I_{black}),f_{T2w}=f(I_{black},I_{T2w}) fADC=f(IADC,Iblack),fT2w=f(Iblack,IT2w),与使用这两个组件的输出 f o u t = f ( I A D C , I T 2 w ) f_{out}=f(I_{ADC},I_{T2w}) fout=f(IADC,IT2w)进行比较。产生与groundtruth病灶区域上的 f o u t f_{out} fout更相似的预测输出的组件被认为包含更多的PCA特征。通过这种方式,MFL为选择一个组件对 每个切片 进行训练。
然后,使用MFL训练CNN,使得病变发现可以从所选择的成像组件等效观察。具体地说,MFL使用所选组件最小化 f o u t f_{out} fout和输出之间的groundtruth掩码 y y y上的L2距离。即, L 2 A D C = ∥ y ⨂ ( f o u t − f A D C ) ∥ 2 L2_{ADC}=\lVert y\bigotimes (f_{out}−f_{ADC})\rVert^2 L2ADC=∥y⨂(fout−fADC)∥2或 L 2 T 2 w = ∥ y ⨂ ( f o u t − f T 2 w ) ∥ 2 L2_{T2w}=\lVert y\bigotimes(f_{out}−f_{T2w})\rVert^2 L2T2w=∥y⨂(fout−fT2w)∥2,其中 ⨂ \bigotimes ⨂是元素相乘。由于MFL旨在训练PCa特征,因此L2距离是在groundtruth lesion区域上计算的而不是在non-lesion区域上计算的。相比于两个组件,非病变区域从单一组件的观察中更有可能具有与病变相似的外观,因此强制 f A D C f_{ADC} fADC或 f T 2 w f_{T2w} fT2w具有与 f o u t f_{out} fout相同的non-lesion发现可能会抵消PCa特征的训练。 此外,与groundtruth y相比,Fout被用作“soft” and adaptive的事实参考来训练特定的组件。即使CNN使用两个组件也无法检测到一个几乎不可见的病变时, f o u t f_{out} fout也不希望CNN使用单一的成像组件来识别病变。相反,如果使用两个组件清楚地检测到病变,则针对单个组件中的某些PCa特征训练CNN。
如图3所示,MFL被总结为端到端学习的损失项,使得:
其中N是图像的总像素数。 -
FocalNet training:
FocalNet通过FL和MFL的组合损失进行训练,如下:
其中S是Sigmoid函数,并且 λ = 1 p o s i t i v e b i t r a t i o \lambda=\frac{1}{positive bit ratio} λ=positivebitratio1是平衡FL和MFL的权重常量。此外,如图3所示,橙色箭头表示FL的反向传播路径,红色箭头表示MFL的反向传播路径。由于 f o u t f_{out} fout在MFL中用作 f A D C f_{ADC} fADC或 f T 2 w f_{T2w} fT2w的事实参考,因此对于这两个成像分量,MFL不会将梯度传递到 f o u t f_{out} fout以进行训练。
D. Pre-processing & Training
-
Registration:
利用扫描仪坐标信息通过刚性变换将ADC图像配准到T2w图像。由于在我们的扫描方案中,ADC和T2w序列在时间上彼此接近,所以我们发现ADC和T2w之间的患者运动最小。因此,正如在[14]中所建议的,我们没有使用额外的非刚性配准。在配准之后,对于每个患者,手动识别以前列腺为中心的80 mm×80 mm区域,然后将其大小调整为128×128像素。 -
Intensity normalization & variation:
在使用和不使用直肠内线圈的mp-MRI检查之间有很大的强度差异,因此,常用的直方图归一化方法不能一致地工作。取而代之的是,我们将T2w强度值按照空气强度的下限阈值和基于膀胱强度的上限阈值进行剪裁,因为:
① 膀胱易于程序化定位;
② 膀胱强度依赖于水,在不同患者之间相对一致。
然后,我们使用下限阈值和上限阈值将限幅的T2w强度线性归一化为[0,1]。此外,由于ADC是定量成像,其强度值指示病变的检测和分类,因此我们采用患者独立的阈值来裁剪ADC的强度,并将其归一化为[0,1]。在训练过程中,应用T2w intensity variation来提高CNN在某些扫描中由直肠内线圈引起的图像强度变化的鲁棒性。在强度归一化后,T2w上限强度阈值在可以检测PCa lesion的可估计范围内随机波动,经验范围是从-15%到+20%。 -
Implementations:
FocalNet的主干CNN结构是用Deeplab实现的,在2D图像输入上使用101层深度残差网络(deep residual network)。在初步实验中,我们也测试了U-Net作为CNN的主干,但是U-Net的训练在早期阶段通常会失败,这可能是由于FL和U-Net跳跃连接之间的不兼容造成的。此外,将来自对象分类任务的预训练的CNN权重作为初始化权重。
采用动量为0.9的随机梯度下降法和权重为0.0001的L2正则化算法对总损失进行了优化。
学习速率从0.001开始,0.7 decay/2000 steps。
The CNN is trained for 200 epochs with batch size 16.

除了T2w强度变化之外,在训练期间还应用了常见的图像增强,包括图像平移、缩放和翻转。我们没有应用图像旋转,因为小角度旋转会在插值过程中产生模糊。对每批训练图像执行图像增强,而不是对验证图像执行图像增强。
图像配准是使用统计参数映射工具箱实现的,每个病例的图像预处理步骤大约需要一分钟。FocalNet使用TensorFlow机器学习框架实现。使用12 GB内存的NVIDIA Titan XP GPU,平均训练时间为 3~4 hour/per fold,由于CNN的非迭代性质,预测相对较快,每个患者约0.5-1秒。
E. Validation
- Cross-validation:
我们使用5次交叉验证来训练和验证这项研究。每个fold包括333或334个训练案例和84或83个用于验证的案例。在训练和验证中,只包括带注释的切片,以最大限度地减少丢失注释的病变的机会。每个案例包含2到7个切片,训练集和验证集的每个fold分别约有1400个和350个切片。 - Lesion localization:
对于PCA检测,我们从CNN像素级检测输出中提取病变定位点。对于每种情况,我们从切片的检测输出中找到2D局部最大值。检测灵敏度和错误检测之间的权衡通过对局部最大值的检测概率的阈值来控制。 - FROC for lesion detection:
由于PCA的多焦点特性,通过自由响应接收器操作特征(FROC)分析来评估病变检测性能。FROC测量病变检测灵敏度与每个患者的假阳性数。















 5204
5204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









