






 本文介绍了一种名为FocalNet的新型图像恢复框架,通过双域选择机制关注重建关键区域,如边缘和困难区域,结合多尺度特征和U型主干结构,实现在多个图像恢复任务中的先进性能。
本文介绍了一种名为FocalNet的新型图像恢复框架,通过双域选择机制关注重建关键区域,如边缘和困难区域,结合多尺度特征和U型主干结构,实现在多个图像恢复任务中的先进性能。
摘要:图像恢复旨在从其受损对应物中重建清晰图像,这在许多领域中起着重要作用。最近,Transformer模型在各种图像恢复任务上取得了令人期待的性能。然而,它们的二次复杂度仍然是实际应用中难以处理的问题。本研究旨在开发一种高效且有效的图像恢复框架。受到一个事实的启发,即受损图像中的不同区域总是以不同程度经历退化,我们提出更加关注重建的重要区域。为此,我们引入了一种双域选择机制,以强调恢复所需的关键信息,如边缘信号和困难区域。此外,我们将高分辨率特征分割成多尺度感知场,插入到网络中,从而提高了效率和性能。最后,我们提出的网络,称为FocalNet,通过将这些设计融入到U型主干中来构建。大量实验表明,我们的模型在三个任务(包括单图像虚焦去模糊、图像去雾和图像去雪)的十个数据集上均实现了最先进的性能。我们的代码可在https://github.com/c-yn/FocalNet 获取。
如何有效地简洁地捕获关键信息一直以来都是计算机视觉和模式识别领域的一个关键问题。成功的例子包括注意机制 [53]、焦点损失 [34],以及最近的部分AUC优化 [58]。在受此启发的基础上,在这项研究中,我们不追求大的感受野或对Transformer架构进行修改,而是通过更多地关注用于重建的信息信号(如边缘信息或难以恢复的区域)来开发一个高效且有效的基于CNN的框架。在这个方向上,现有的方法可以大致分为两类:辅助训练和基于注意力的方法。前者主要利用辅助技术或数据,例如语义分割 [12]、深度估计 [29] 和光流估计 [60],来定位退化或边缘信息。然而,这些算法总是需要额外的复杂分支和精心设计的训练策略来生成监督信息。关于此主题的另一条线路是设计注意力机制,以关注信息丰富的区域或控制信息传递 [8, 41, 62]。这些方法主要位于空间域,忽略了光谱信息的使用,而光谱信息也可以为重建提供有用的信息。
为了促使模型更多地关注关键区域,我们提出了一种新颖的双域选择机制(DSM),充分利用了空间和光谱域中锐化/退化图像对之间的差异。具体而言,我们的机制包括两个组件:空间选择模块(SSM)和频率选择模块(FSM)。 SSM将特征作为输入,并通过部署深度卷积层来确定每个通道的退化的一般位置。然后FSM用于通过从特征中去除低频信号来放大高频信号或难以处理的区域。提出的网络FocalNet是通过将DSM纳入U型CNN主干中而建立的。为了节省计算开销,我们只将DSM插入到FocalNet的瓶颈模块中,其中包括最低分辨率的特征。此外,我们将高分辨率特征在通道维度上分为两部分。一半的特征被降采样到较低的分辨率,这不仅可以降低复杂性,还可以通过为不同尺寸的退化提供多尺度感知场来提高性能。
基于以上设计,我们的FocalNet在三个图像恢复任务上展现出了最先进的性能。对于去雾,FocalNet在合成和真实世界基准数据集上的计算复杂性更低,胜过了PMNet [59],如图1所示。对于去雪任务,FocalNet优于基于Transformer的框架TransWeather [50],在三个常用的去雪数据集上表现出色。我们的网络还在虚焦去模糊问题上表现出潜力,与Restormer [61] 相比,在DPDD [1] 数据集的综合类别上获得了0.2 dB PSNR的性能提升。
总的来说,本研究的主要贡献总结如下:
• 我们提出了一种新颖的双域选择机制(DSM),通过放大重要区域的响应来帮助恢复清晰特征。
• 我们开发了一个高效且有效的焦点网络,为图像恢复提供多尺度表示学习。
• 在十个数据集上进行的大量实验表明,所提出的网络FocalNet在三个代表性图像恢复任务上表现优异,胜过了最先进的算法。
模型构建
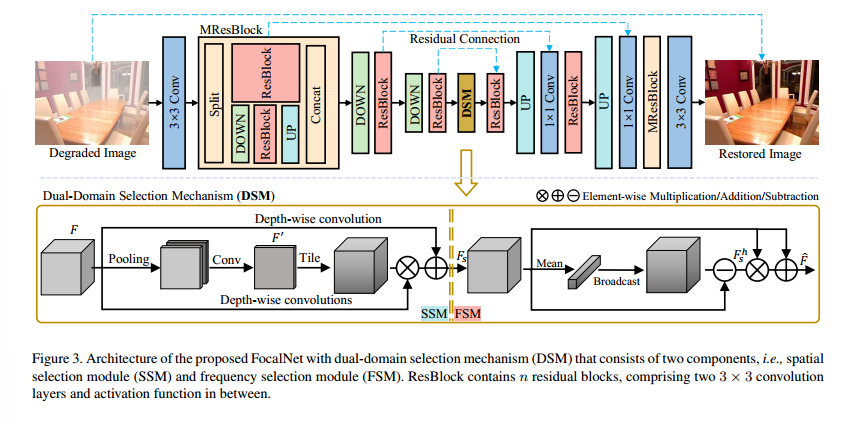
如图3所示,提出的FocalNet采用了常见的编码器-解码器架构,以高效地学习分层表示。编码器和解码器网络都包括三个尺度。在本文中,我们将第一个尺度称为涉及最高分辨率特征的子网络。MResBlock构成了第一个尺度的主要部分。另外两个尺度主要由ResBlock组成,其中包括n个残差块。给定大小为H×W×3的降质图像,其中H×W和C分别表示空间位置和通道数,使用3×3卷积层来提取大小为H×W×C的浅层特征。然后,浅层特征通过三尺度对称编码器-解码器传递,并转换为恢复特征,即解码器的第一个尺度中的MResBlock的输出特征。从最高分辨率输入开始,编码器逐渐减小空间尺寸并扩展通道数。解码器则相反,从最深层特征中恢复出干净特征。在这个过程中,解码器特征与编码器特征串联在一起以帮助恢复,并进行1×1卷积以调整通道维度。最后,通过最后的3×3卷积层和图像级残差连接生成预测的干净图像。上采样(UP)和下采样(DOWN)操作通过转置卷积和步幅卷积来实现,除了MResBlock中的上采样层采用双线性插值。提出的DSM注入到瓶颈位置以选择最重要的特征。
Multi-scale ResBlock (MResBlock)
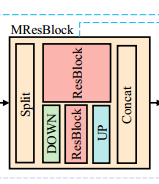
最近,追求多尺度感受野在计算机视觉领域是一个热门话题 [5, 20, 42, 55],特别是对于基于Transformer的模型 [33, 42]。受到 [11, 40, 46] 的启发,我们采用多尺度机制在ResBlock中进行分割和下采样操作,形成我们的MResBlock,如图3所示。具体来说,对于给定的输入特征,我们首先沿通道维度将它们均等地分成两个组件。接下来,一半的特征使用步幅卷积降低到原始分辨率的四分之一。得到的特征被馈送到ResBlock中,然后上采样到原始尺寸。另一半直接由ResBlock处理。MResBlock的最终输出是通过连接两个分支的结果特征来获得的。MResBlock具有两个主要优点。首先,它通过实现不同尺寸降质的多尺度表示学习,增强了不同频率的谱学习,从而提高了性能 [40]。其次,通过降低特征分辨率,它提高了效率。
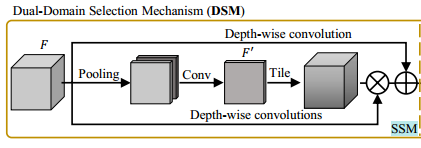
Dual-domain Selection Mechanism (DSM)
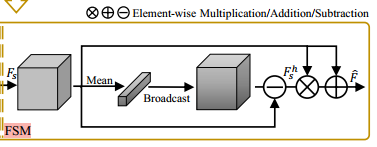
本研究的主要目标是通过聚焦在更重要的区域上,开发一种用于图像恢复的高效网络。这个目标是通过提出的DSM(Dynamic Selection Module)来实现的,它在两个领域中增强了信息的响应(见图2)。如图3底部所示,DSM由两个组件组成:空间选择模块(SSM)和频率选择模块(FSM)。给定输入特征F ∈ R
H×W×C,SSM和FSM被依次使用,可以表示为:
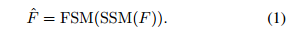
空间选择模块(Spatial Selection Module,SSM)有助于网络在空间域中关注重要区域,提供了严重降质的初始位置,供后续的频率选择模块(FSM)使用。我们的SSM有三个分支。主路径建立在CBAM [53] 的基础上,用于生成重点关注降质位置的通用特征表示。具体而言,给定一个中间特征图F,首先沿着通道维度通过两种池化技术(最大池化和平均池化)对F进行压缩,然后通过卷积层生成通用特征图,形式上表示为:
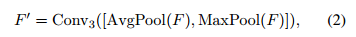
其中,[·, ·] 表示连接操作;AvgPool、MaxPool 和 Conv3 分别表示平均池化、最大池化和3×3卷积核大小的卷积层。通过这样做,F' ∈ RH×W×1 包含了要关注的降质位置 [53]。
由于每个通道在降质模式上有所不同,我们通过对输入特征F进行通道分离变换,进一步生成通道-wise 表示,并使用F'来调制生成的特征。这个过程表示如下:
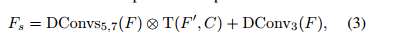
其中,DConvs5,7 表示5×5和7×7卷积核大小的级联深度卷积层;DConv3 表示3×3卷积核大小的深度卷积; ⊗ 表示逐元素乘法;T(F', C) 是复制F'C次沿通道维度的平铺函数,将其扩展到RH×W×C。然后,我们将空间选择的特征Fs ∈ RH×W×C 输入到频率选择模块FSM中进行频率选择。
频率选择模块(Frequency Selection Module,FSM)。我们可以直接利用Fs来帮助恢复过程。受到这样一个事实的启发,即降质/清晰图像对具有相似的低频分量,但在高频方面有所不同,我们通过提出的FSM来进一步强调包含输入/清晰图像对之间真正差异的区域,通过移除最低频率。为此,我们首先对Fs应用均值滤波器来生成低频特征,然后通过从输入中减去生成的低频信号来获得互补的高频特征,表示如下:
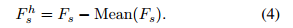
在我们的情况下,均值滤波器是通过通道维度的全局平均池化来实现的。FSM/DSM的最终输出是通过F
h
s和Fs之间的逐元素乘法以及残差连接生成的,表示如下:
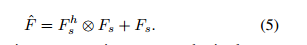
经过DSM后,重要区域得到了强调,例如图2中的边缘信号,用于去除虚焦模糊。
Loss Function
为了方便空间域和频域的选择过程,我们采用如下的双域l1损失函数[13,15]。对于相同分辨率的每个输出/目标图像对,损失函数为:
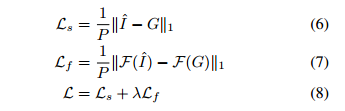
其中,I和G分别表示输出图像和真地图像;P表示归一化总元素;F表示快速傅里叶变换;并且λ被经验地设置为0.1以平衡双域训练。
结论:在本研究中,我们提出了一种有效且计算效率高的图像恢复焦点网络,称为FocalNet。我们工作的核心思路是聚焦重点重建区域。为此,我们提出两个模块:SSM和FSM。SSM是建立在空间注意的基础上,用于检测退化区域,以便进行后续的频率选择。FSM进一步强调难以恢复的边缘信号或区域。通过连续部署两个模块,网络能够更多地关注对重建真正重要的区域。此外,我们通过降低一半输入特征通道的分辨率,将多尺度机制插入到网络中。这种设计不仅提高了性能,而且降低了复杂性。在10个数据集上的实验表明,我们的模型在几个图像恢复任务中达到了最先进的性能。
注释:
(1)
双线性插值是一种用于图像处理和计算机图形学的插值技术,用于估算两个已知点之间的值。它通常用于图像缩放和旋转等操作,以平滑地生成图像的新像素值。
双线性插值的基本思想是,在一个二维网格上,由四个最近的已知点的值进行加权组合来估算新点的值。这四个已知点通常位于新点的周围,形成一个矩形区域。插值过程如下:
1. 首先,确定新点在已知点网格中的位置,并找到距离新点最近的四个已知点,通常是左上、右上、左下和右下四个点。
2. 然后,计算新点与这四个已知点之间的水平和垂直距离(权重)。通常,距离越接近的点,其权重越大。
3. 使用这些距离权重,对四个已知点的值进行加权平均,以生成新点的值。这就是双线性插值的名称,因为它同时在水平和垂直方向上进行线性插值。
这种插值方法可以有效地生成平滑的图像缩放效果,避免了锯齿状边缘和像素化。它在许多图像处理和计算机图形学应用中都有广泛的应用,包括图像缩放、纹理映射、图像旋转和变形等。
(2)
转置卷积(Transpose Convolution)和步幅卷积(Strided Convolution)都是卷积神经网络中的卷积操作的不同变种,用于不同的目的。
1. 转置卷积(Transpose Convolution):
转置卷积也被称为反卷积(Deconvolution)或上采样卷积(Upsampling Convolution)。它的主要目的是将输入的特征图的尺寸增加,通常用于实现上采样或反卷积操作。转置卷积通过在输入特征图之间插入一些新的值(通常是零)来实现尺寸的扩展。它在图像分割、图像生成(如生成对抗网络中的生成器部分)、语义分割等任务中经常用于将低分辨率特征图还原为高分辨率特征图。
2. 步幅卷积(Strided Convolution):
步幅卷积是正常卷积操作的一个变种,它在处理输入特征图时跳过一定数量的像素或步幅,从而减小输出特征图的空间尺寸。步幅卷积的主要作用是控制输出特征图的分辨率,以实现特征的降维或下采样。步幅卷积通常用于在卷积操作中控制感受野的大小或在池化层之前减小特征图的尺寸。
总之,转置卷积用于尺寸扩展和上采样,而步幅卷积用于控制特征图的分辨率和下采样。这两种卷积操作在深度学习中的图像处理任务中发挥着重要作用,通常用于不同类型的任务和网络架构中。

















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









