






基于气体色谱分析(DGA, Dissolved Gas Analysis)的变压器故障诊断流程一般包括以下几个步骤:
1. 采集油样
- 定期或在异常情况下采集变压器油样。通过气体色谱仪对油样中溶解的气体进行分析。
2. 气体分析
- 使用气体色谱仪对油样中的溶解气体(如氢气、甲烷、乙烯、乙炔等)进行定性和定量分析。
- 常见的故障气体包括:
- 氢气:轻微过热或正常运行下也可能释放。
- 甲烷和乙烯:可能表明绝缘油过热。
- 乙炔:通常指示严重故障,如电弧故障或局部放电。
3. 气体浓度分析
- 对采集到的气体浓度进行分析。不同的气体浓度变化对应不同类型的故障。常用的诊断方法包括:
- 三种气体法(TGC法):主要关注甲烷、乙烯、乙炔等气体的浓度变化。
- 比值法:根据气体浓度的比值(如C2H2/C2H4, C2H4/C2H6等)来判断故障类型。
- V/I法(Volatile and Inert):将气体浓度与油的电气特性结合分析。
4. 判断故障类型
- 根据气体分析结果,通过对比故障类型的典型气体生成模式(如过载、局部放电、电弧等)进行判断。常见的故障类型包括:
- 中低温过热
- 高温过热
- 低能放电
- 高能放电
- 局部放电
- 正常
5. 机器学习代码实现与DGA数据
数据来源于知网论文(已放入代码中),并系个人亲自使用,效果很好。
在拥有可靠的DGA数据的前提下,结合机器学习分类算法,可以实现变压器的故障诊断。将上述的六种故障类型分别用数字1-6表示,随机森林示例代码如下:
clear
close all
clc
warning off
%% 导入数据
res = xlsread('数据集.xlsx'); %在这插入数据集的名字,如需获取数据集,请至代码最后一行获取
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input );
t_train = T_train;
t_test = T_test ;
%% 转置以适应模型
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
%% 训练模型
trees = 100; % 决策树数目
leaf = 1; % 最小叶子数
OOBPrediction = 'on'; % 打开误差图
OOBPredictorImportance = 'on'; % 计算特征重要性
Method = 'classification'; % 分类还是回归
net = TreeBagger(trees, p_train, t_train, 'OOBPredictorImportance', OOBPredictorImportance, ...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
importance = net.OOBPermutedPredictorDeltaError; % 重要性
%% 仿真测试
t_sim1 = predict(net, p_train);
t_sim2 = predict(net, p_test );
%% 格式转换
T_sim1 = str2double(t_sim1);
T_sim2 = str2double(t_sim2);
%% 性能评价
error1 = sum((T_sim1' == T_train)) / M * 100 ;
error2 = sum((T_sim2' == T_test )) / N * 100 ;
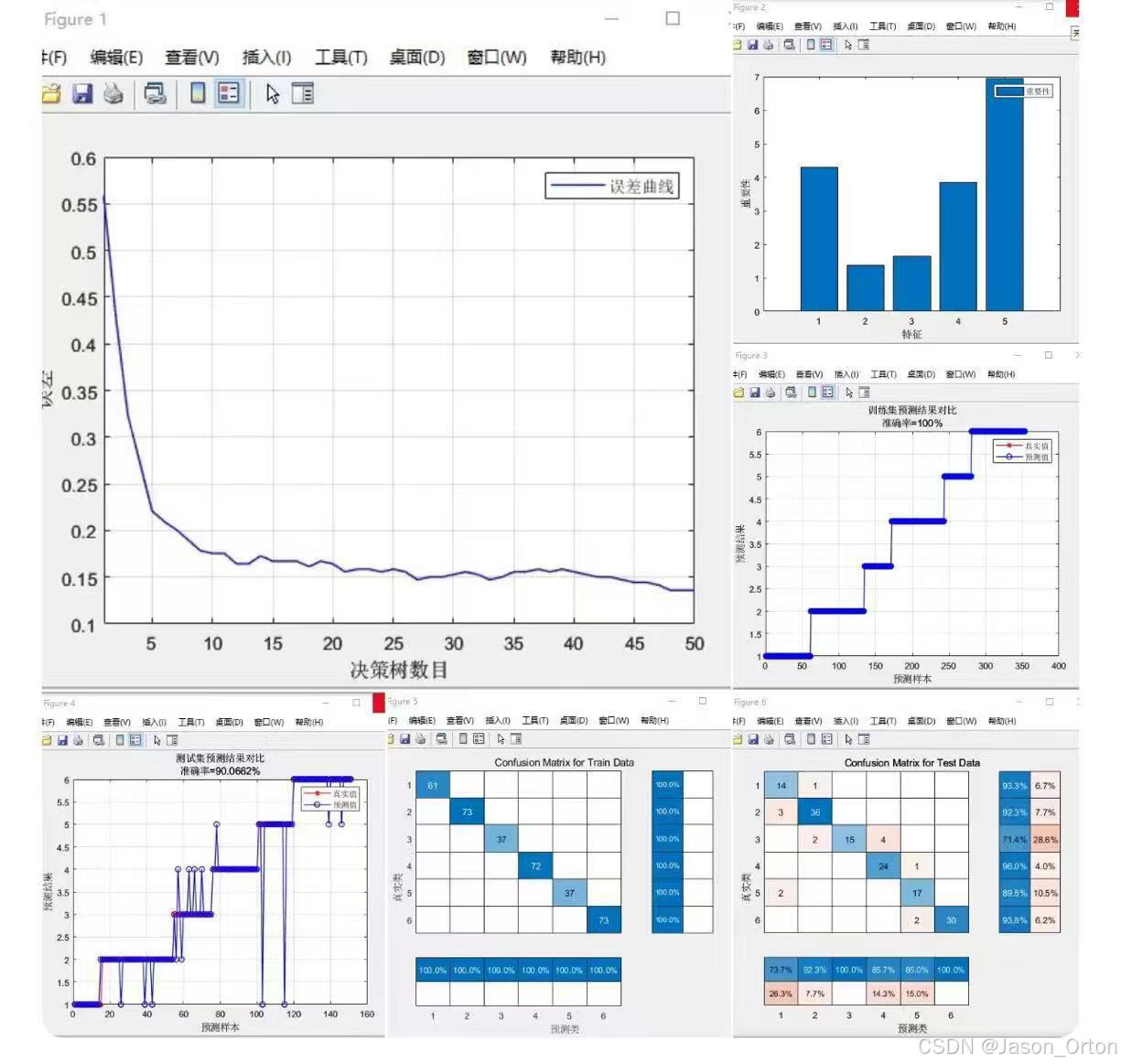
%% 绘制误差曲线
figure
plot(1: trees, oobError(net), 'b-', 'LineWidth', 1)
legend('误差曲线')
xlabel('决策树数目')
ylabel('误差')
xlim([1, trees])
grid
%% 绘制特征重要性
figure
bar(importance)
legend('重要性')
xlabel('特征')
ylabel('重要性')
%% 数据排序
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
%% 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['准确率=' num2str(error1) '%']};
title(string)
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比'; ['准确率=' num2str(error2) '%']};
title(string)
grid
%% 混淆矩阵
figure
cm = confusionchart(T_train, T_sim1);
cm.Title = 'Confusion Matrix for Train Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
figure
cm = confusionchart(T_test, T_sim2);
cm.Title = 'Confusion Matrix for Test Data';
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
disp(['训练集最终预测准确率:',num2str(error1) '%)' ])
disp(['测试集最终预测准确率:',num2str(error2) '%)' ])
%获取数据集:https://mbd.pub/o/bread/mbd-ZpWbmJts6. 故障诊断结果
在此数据集的基础上,用随机森林跑出的结果如图。

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









