






本代码实现了对高维数据通过PCA进行降维后,再输入到RF模型中去,从而提高模型精度的目的。代码中都有详细的注释,直接替换数据就可以使用。
一. 概述
1. 主成分分析(PCA)
目的:降维,减少数据的维度,同时保留尽可能多的原始数据的方差。
步骤:
- 标准化数据:为了使每个特征对总的方差贡献相似,通常需要对数据进行标准化处理。
- 计算协方差矩阵:确定数据集中特征之间的协方差。
- 计算特征值和特征向量:从协方差矩阵中提取特征值和特征向量。
- 选择主成分:选择前k个特征向量(主成分),对应的特征值最大,这些主成分解释了数据中最多的方差。
- 转换数据:将原始数据投影到选定的主成分上,得到降维后的数据。
2. 随机森林(RF)
目的:分类或回归,构建多个决策树并通过集成学习的方法提高模型的预测性能和稳定性。
步骤:
- 构建多个决策树:通过对原始数据集进行有放回的抽样(即Bootstrap抽样)生成多个子数据集,并在这些子数据集上训练决策树。
- 每个节点的随机特征选择:在构建每棵树时,每个节点仅从一个随机选择的特征子集进行分裂,从而增加多样性。
- 集成决策:通过多数投票(分类任务)或平均(回归任务)来结合所有树的预测结果。
3. PCA+RF 结合的分类模型
目的:使用PCA进行降维以减少数据的维度和噪声,然后使用随机森林进行分类。
步骤:
- 数据预处理:对数据进行标准化处理。
- PCA降维:对标准化后的数据应用PCA,选择主成分,将数据降维。
- 训练随机森林模型:使用降维后的数据训练随机森林分类器。
- 预测和评估:用训练好的模型进行预测,并评估其分类性能。
优点
- 降维:PCA有效地减少了数据的维度,降低了计算复杂度,同时保留了数据的大部分信息。
- 处理高维数据:RF在处理高维数据时表现出色,能够处理大量特征并自动进行特征选择。
- 稳健性和准确性:RF通过集成多棵决策树,提高了分类模型的稳健性和准确性。
适用场景
- 高维数据集(例如基因表达数据、图像数据)的分类任务。
- 数据存在噪声,希望通过降维来提升分类性能。
结合PCA和RF的方法能够在高维数据集上表现出色,同时保留数据的主要特征和提高分类准确性。
二. Matlab代码
完整代码及函数跳转最后一行
clear
clc
%% 导入数据
X = xlsread('input');
Y = xlsread('output');
flag_conusion = 1; % 标志位为1,打开混淆矩阵
%% PCA主成分降维
[Z,MU,SIGMA]=zscore(X);
%% 计算相关系数矩阵
Sx=cov(Z); % 相关系数矩阵计算
%% 计算相关系数矩阵的特征值特征向量
[V,D] = eig(Sx); %计算相关系数矩阵的特征向量及特征值
eigValue = diag(D); %将特征值提取为列向量
[eigValue,IX]=sort(eigValue,'descend');%特征值降序排序
eigVector=V(:,IX); %根据排序结果,特征向量排序
C=sort(eigValue,'descend'); %特征值进行降序排序
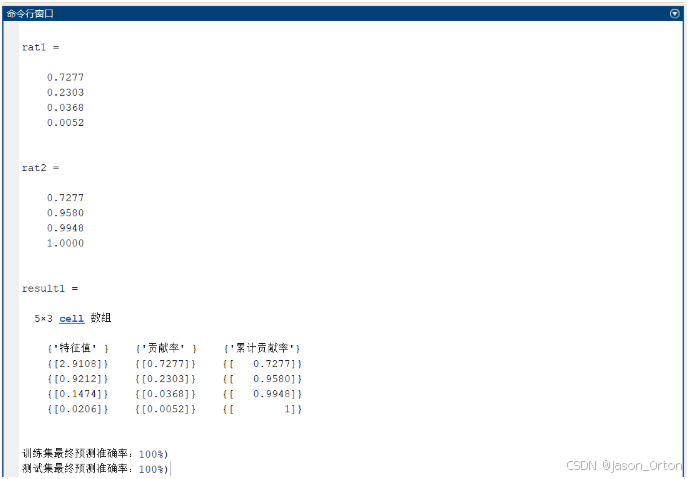
rat1=C./sum(C) %求出排序后的特征值贡献率
rat2=cumsum(C)./sum(C) %求出排序后的累计贡献率
result1(1,:) = {'特征值','贡献率','累计贡献率'}; %细胞矩阵1第一行标题
result1(2:(length(D)+1),1) = num2cell(C); %将特征值放到第一列
result1(2:(length(D)+1),2) = num2cell(rat1); %将贡献率放到第二列
result1(2:(length(D)+1),3) = num2cell(rat2) %将累计贡放到第三列
%% 特征向量的归一化处理
norm_eigVector=sqrt(sum(eigVector.^2));%特征向量进行归一化处理
eigVector=eigVector./repmat(norm_eigVector,size(eigVector,1),1);
%% 判断贡献率
%根据贡献率达到85%故选择
d=2;% 这块根据实际情况修改
%%完整代码获取:https://mbd.pub/o/bread/mbd-ZpaTk5dx三. 运行结果
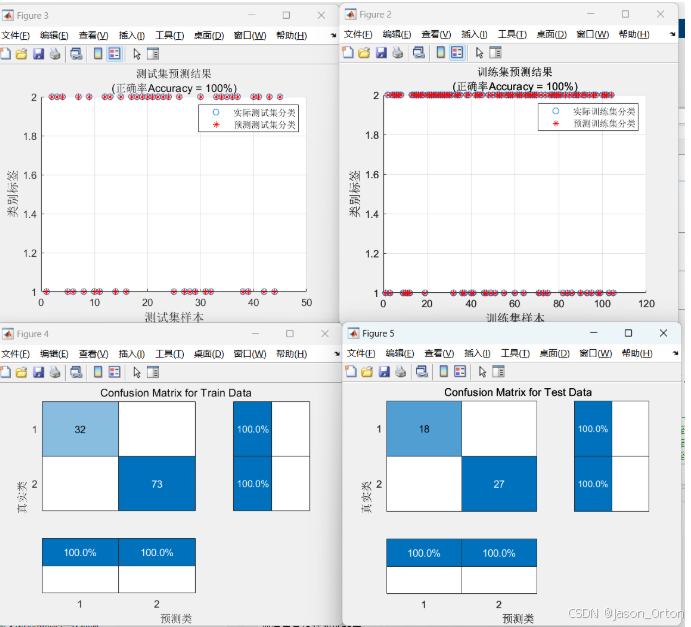

















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









