







MM2022 | 在特征空间中的多模态数据增强方法
【写在前面】
每小时,社交媒体和用户生成的内容平台上都会发布大量的视觉内容。为了通过自然语言查询查找相关视频,文本视频检索方法在过去几年中受到了越来越多的关注。引入了数据增强技术,以通过使用语义保留技术 (例如图像上的颜色空间或几何变换) 创建新的训练样本来提高看不见的测试示例的性能。然而,这些技术通常应用于原始数据,导致更多资源需求的解决方案,并且还要求原始数据的可共享性,这可能并不总是正确的,例如电影或电视连续剧剪辑的版权问题。为了解决此缺点,作者提出了一种多模态数据增强技术,该技术可在特征空间中工作,并通过混合语义相似的样本来创建新的视频和字幕。作者在大规模的公共数据集,EPIC-Kitchens-100上实验本文的解决方案,并在基线方法上实现了相当大的改进,改善了最先进的性能,同时进行了多次消融研究。
1. 论文和代码地址

A Feature-space Multimodal Data Augmentation Technique for Text-video Retrieval
论文地址:https://arxiv.org/abs/2208.02080
代码地址:https://github.com/aranciokov/FSMMDA_VideoRetrieval
2. Motivation
每分钟上传到互联网的用户生成的视频内容数量不断增加,导致每分钟上传到YouTube的内容超过500小时,截至2020年2月。查找给定查询的相关视频需要计算机视觉和自然语言处理技术的结合,将此问题置于两个社区的交汇处。特别是,文本到视频检索任务通过要求基于其与输入查询的语义接近度对所有视频进行排序来涵盖此目标。
最近,深度学习技术被用来从多模态数据中自动提取特征,并学习如何解决此任务,展示其潜力并取得令人印象深刻的结果。但是,执行深度学习模型训练所需的大量注释数据代表了这些技术成功的重大限制。为此,通过众包平台收集了大量数据,在这些平台中,需要人工努力来仔细注释数据,从而导致标注者的繁琐任务和数据集收集器的巨额成本。使用这种方法获得的大规模数据集的示例包括msr-vtt 和VATEX 。为了降低收集成本,科学界主要研究了两种自动解决方案: web抓取和数据增强。在前者中,从Internet和相关注释中提取视觉内容是自动执行的,例如使用语音识别 ,替代文本或利用标签。尽管这种方法可能会导致巨大而丰富的数据集,但标注通常是嘈杂的,并且很难保证标注的质量。另一方面,数据增强技术通常用于通过利用已经可用的标注样本来人为地增加数据集的大小: 可以通过应用标签保留技术来获得新样本,从而提供语义上一致的数据并避免噪声。事实上,这些技术在许多领域都显示了巨大的潜力,无论是视觉社区,如分类和检测,还是语言处理社区,如文本摘要和文本分类。尽管增强已应用于视觉问答和图像字幕,但对于文本视频检索而言,这些技术的探索较少。为了解决这一缺点,作者研究了增强技术的应用,并提出了一种利用多模态信息 (视觉和文本) 进行文本视频检索的增强技术。特别是,本文的视频增强策略通过混合来自同一类的两个样本的视觉特征创建了一个新的增强视频,因此利用了从基于CNN的骨干的更深层自动提取的高级概念。这是通过在特征空间中执行增强来实现的,而不是常见的变换,例如用于图像的几何和颜色空间变换,这些变换应用于原始数据。实际上,在特征空间中工作会带来三个额外的优势: 相同的技术可以应用于来自不同模态的数据,例如作者在本文中展示的视频和文本数据,而无需进行大量更改; 它不依赖于原始视频或帧的可用性,由于隐私或版权问题,它们更难分享,也不总是可以分享的,例如,据报道,超过20% 的msr-vtt原始视频已从YouTube中删除,而MovieQA 的所有视频都面临版权问题; 最后,它可以应用于预先提取的特征,从而使其总体上不需要时间和资源。
3. 方法
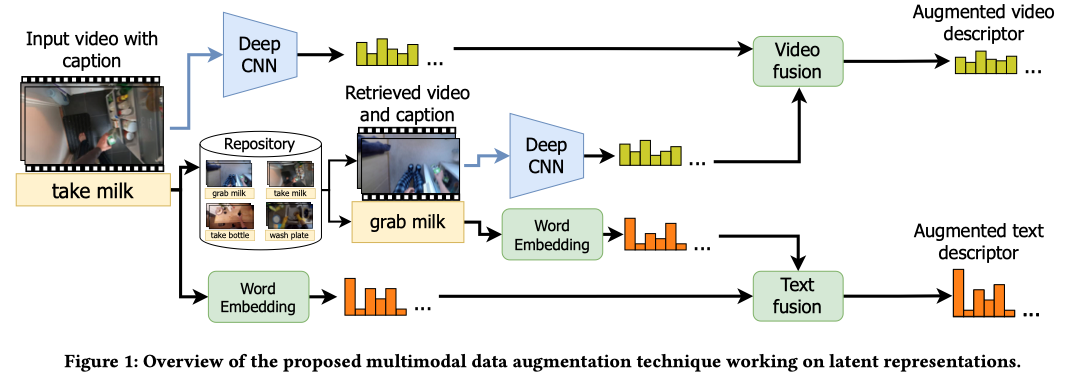
学习文本视频检索任务的模型通常涉及两个神经网络,以计算输入视频和相关字幕的两种表示形式。然后,要求前面的网络调整它们的权重,以便计算视频和字幕两者的相似表示。通过这样做,输入字幕可以在给定其视频的排名列表的顶部,反之亦然。然而,多个字幕 (和视频) 可能同样相关,因此理应位于同一等级。因此,作者提出了一种多模态数据增强技术,该技术通过混合共享相似语义的视频和字幕来创建新的表示形式。增强是在特征空间中进行的,从而带来了多种优势: 通过处理从骨干的更深层中提取的特征,增强的表示包含高级概念,而不是技术使用的低级特征处理原始数据;该技术很容易扩展到不同模态,因为它适用于潜在的表示; 通过仅要求共享预先提取的特征,对原始原始数据的可共享性和可用性的担忧较少; 执行增强所需的计算资源较少,由于从原始数据中提取特征可以离线执行。
假设 v 1 v_{1} v1和 v 2 v_{2} v2是两个视频,展示了用自来水冲洗叉子时不同的人。为了描述这一行为,可以使用“清洁”、“洗涤”或“漂洗”等动词,而叉子也可以指向更一般的(“餐具”或“银器”)或更具体的术语(“三尖叉”或“不锈钢叉”)。所有这些字幕都有相似的语义,只有很小的变化,这些变化可以通过从深度神经网络中自动提取的高级特征来捕获。因此,这些特征可以被重用和混合,以获得与原始字幕具有相似语义的字幕的新表示。同样,可以将 v 1 v_{1} v1和 v 2 v_{2} v2视为可互换的,甚至更有趣的是,可能是可混合的。
3.1 Generating a new clip from same-class samples interpolation
首先,定义了两个选择标准, ϕ V \phi_{V} ϕV和 ϕ N \phi_{N} ϕN,它们标识与执行的操作或与其发生交互的对象相关的兼容视频。这意味着,如果𝑎是动作,𝑜是对象,那么 ϕ V ( a ) \phi_{V}(a) ϕV(a)和 ϕ N ( 0 ) \phi_{N}(0) ϕN(0)是代表𝑎和𝑜的视频集合。请注意,这一标准可能会导致太大的差异:例如,𝜙𝑉(Take)可能包含从橱柜中拿起叉子或从桌子上拿起叉子的视频,但显示某人拿着一片披萨的视频也会被识别为兼容。虽然这可能会收集更多的视频,无论是关联度高的还是关联度最低的,并有助于将它们都推到排行榜的首位,但这也可能会带来额外的困惑和更低的精确度。因此,作者通过将𝜙𝑉和𝜙𝑁绑定到视频的实体和动作来约束它们:
ϕ V ( a , v ) = { w ∣ a ∈ act ( w ) ∧ ent ( v ) ∩ ent ( w ) ≠ ∅ } ϕ N ( o , v ) = { w ∣ o ∈ ent ( w ) ∧ act ( v ) ∩ act ( w ) ≠ ∅ } \phi_{V}(a, v)=\{w \mid a \in \operatorname{act}(w) \wedge \operatorname{ent}(v) \cap \operatorname{ent}(w) \neq \emptyset\}\\\phi_{N}(o, v)=\{w \mid o \in \operatorname{ent}(w) \wedge \operatorname{act}(v) \cap \operatorname{act}(w) \neq \emptyset\} ϕV(a,v)={w∣a∈act(w)∧ent(v)∩ent(w)=∅}ϕN(o,v)={w∣o∈ent(w)∧act(v)∩act(w)=∅}
这里,act和ent是用于提取相应标题中的动作和实体的语义类的函数。例如,act(pick a slice of pizza)将是一个集合,其中包含‘Pick’的类标识符,而ent(pick a slice of pizza)将包含‘a slice of pizza’的标识符。为了获得函数act和ent,可以使用由词性标记器和词法数据库(例如WordNet)组成的管道。如果每个视频与多个字幕配对,则其语义类可以包括在多个字幕之间共享的那些。

如上买呢算法所示,基于概率𝜒,决定是否使用对给定样本进行扩充(步骤4-5),因此在训练期间使用原始样本和扩充样本。然后,以均匀的机会在动作和实体之间进行选择(步骤6),并选择相应的标准(步骤7-11)。为了创建扩展的样本,还需要对两个变量进行采样:将用于查找兼容𝑤的语义类(动作或实体)和来自通过𝑤找到的所有可能候选对象的𝜙的实际采样(步骤12-13)。最后,通过利用函数 f f f(步骤3和14)提取它们的矢量表示 v ˉ \bar{v} vˉ和 w ‾ \overline{\mathcal{w}} w,并用 μ ( v ˉ , w ˉ ) \mu(\bar{v}, \bar{w}) μ(vˉ,wˉ)融合他们。在本文的方法中,作者将𝜇定义为𝑣和𝑤的线性内插,实现为:
μ ( v ˉ , w ˉ ) = λ ⋅ v ˉ + ( 1 − λ ) ⋅ w ˉ \mu(\bar{v}, \bar{w})=\lambda \cdot \bar{v}+(1-\lambda) \cdot \bar{w} μ(vˉ,wˉ)=λ⋅vˉ+(1−λ)⋅wˉ
通过在两个参数都设置为1的贝塔分布中采样𝜆,即𝜆∼𝛽(1,1),灵感来自MIXUP。通过这样做, μ ( v ˉ , w ˉ ) \mu(\bar{v}, \bar{w}) μ(vˉ,wˉ)将共享𝑣和𝑤的高级特征,因此它可能是从描述与它们相似的动作和实体的视频中提取的表示。
3.2 Textual side of the proposed multimodal augmentation
与视频的情况一样,作者在特征空间中设计了文本增强技术。定义了两个标准, ψ V ( a , q ) \psi_{V}(a, q) ψV(a,q)和 ψ N ( o , q ) \psi_{N}(o, q) ψN(o,q),以基于其动作a或实例 o之一来识别可以成为给定q的有效替代的字幕。比如, ψ V ( a , q ) = { d ∣ a ∈ act ( d ) ∧ ent ( q ) ∩ ent ( d ) ≠ ∅ } \psi_{V}(a, q)=\{d \mid a \in \operatorname{act}(d) \wedge \operatorname{ent}(q) \cap \operatorname{ent}(d) \neq \emptyset\} ψV(a,q)={d∣a∈act(d)∧ent(q)∩ent(d)=∅}。
在给定这些运算符和字幕𝑞的情况下,利用Chance 𝜒执行扩充,并且以均匀的机会在动作和实体之间做出决定。在选择有效候选𝑑之后(步骤16),利用函数𝑞和𝑑两者的潜在表示被提取(步骤3和18),然后与函数𝑔混合(步骤19)。对于视频,将𝜌定义为处理从语言模型𝑔中提取的高级概念的混合函数,即 ρ ( q ˉ , d ˉ ) = λ ⋅ q ˉ + ( 1 − λ ) ⋅ d ˉ \rho(\bar{q}, \bar{d})=\lambda \cdot \bar{q}+(1-\lambda) \cdot \bar{d} ρ(qˉ,dˉ)=λ⋅qˉ+(1−λ)⋅dˉ。
4.实验

EPIC-Kitchens-100中使用的数据示例。动词和名词被分组到包含具有相似语义的标记的语义类中。
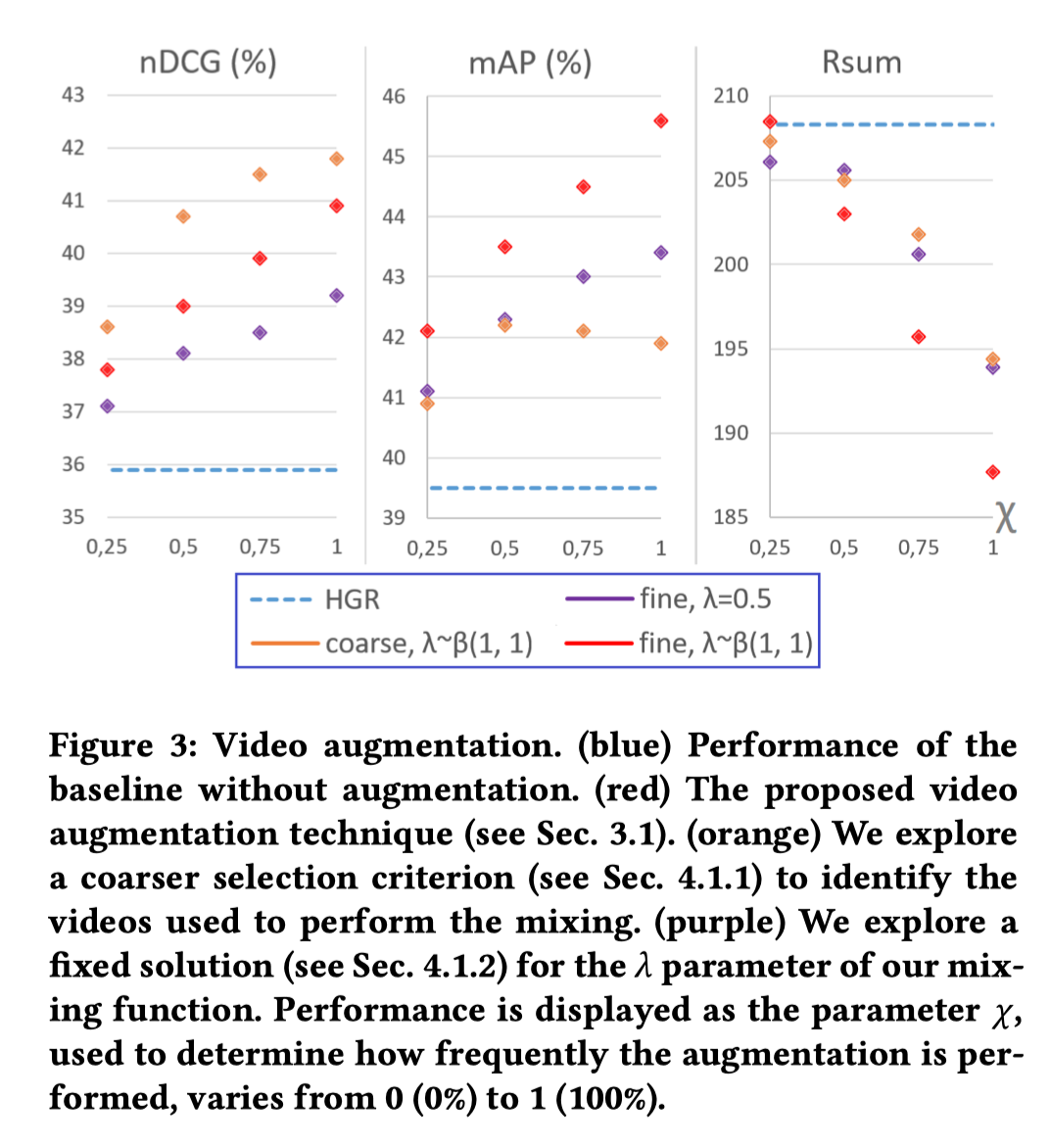
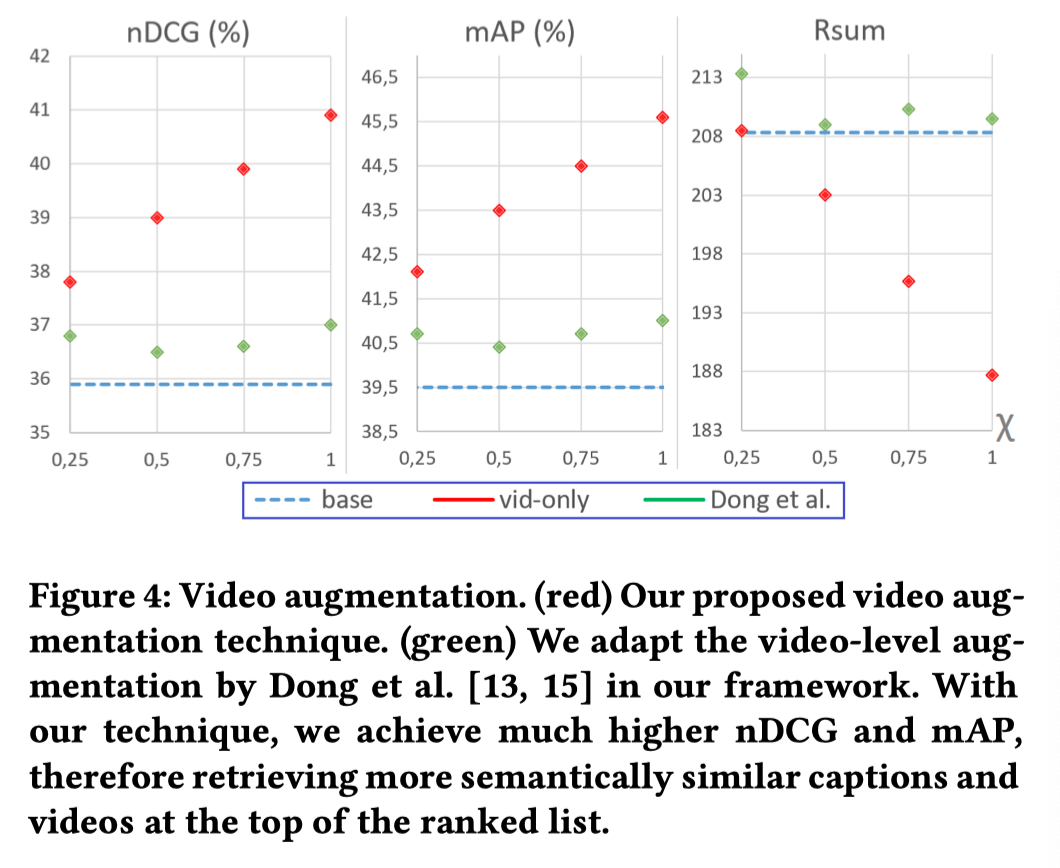
不同图像和文本数据增强方法的实验结果。
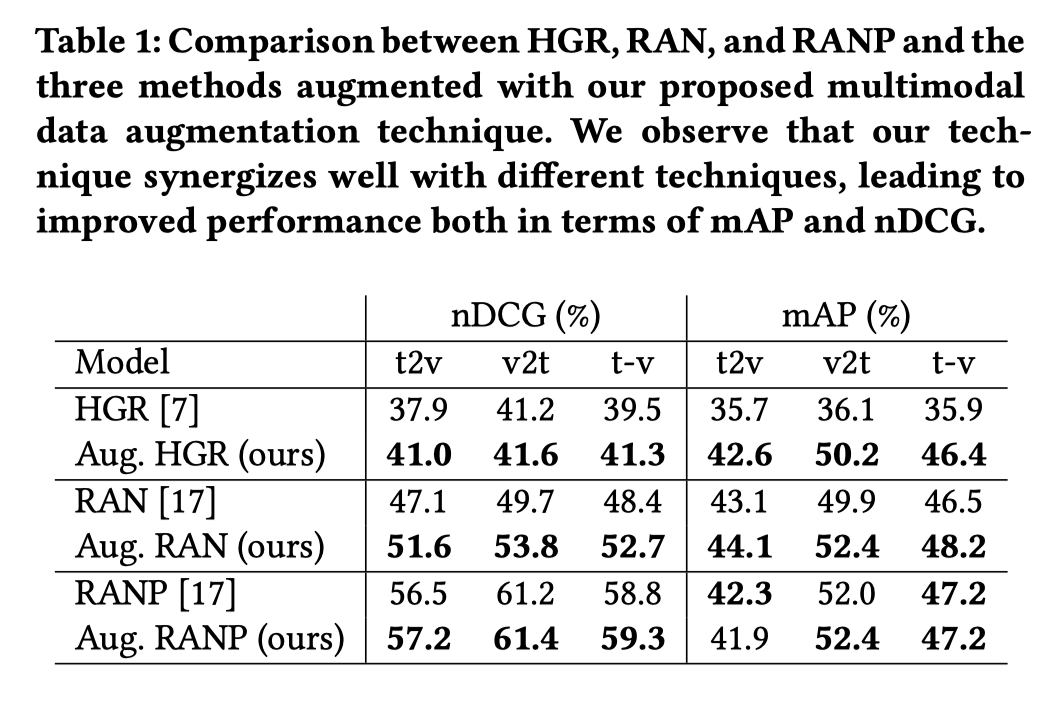
在三种方法加入本文数据增强的实验结果。
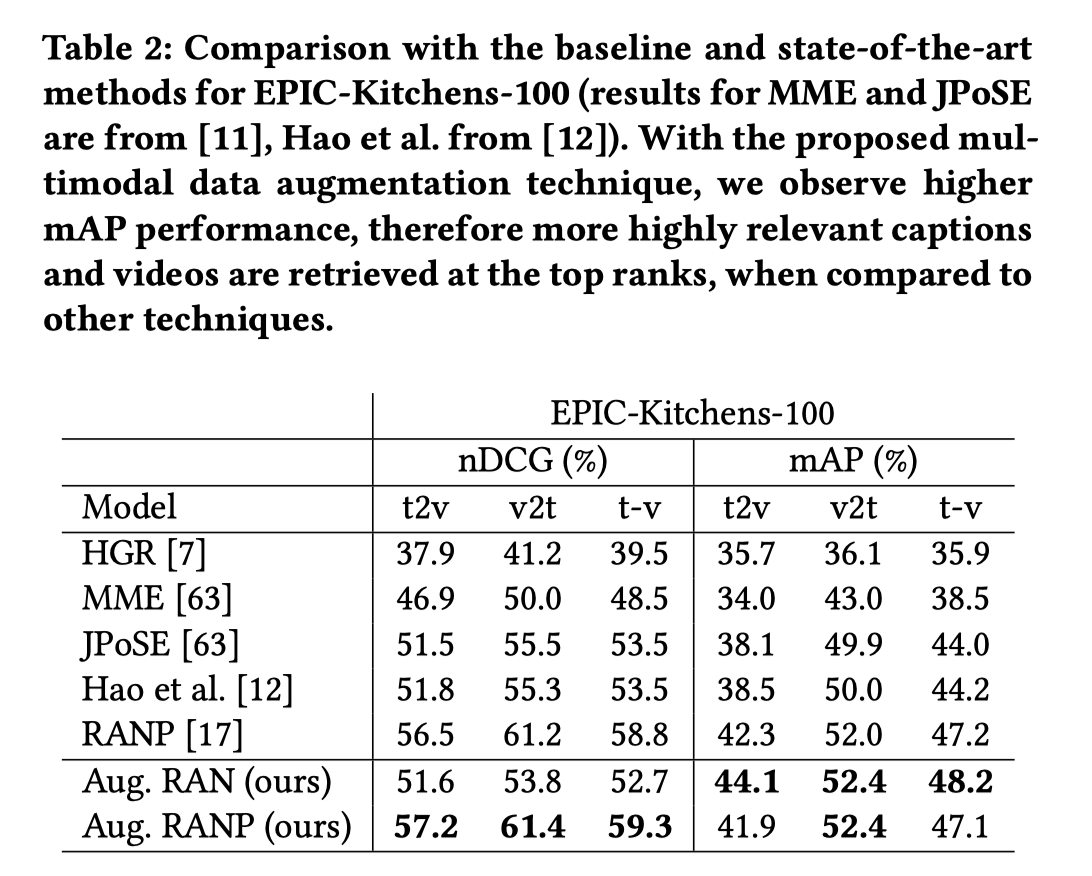
本文方法和SOTA方法的对比结果。
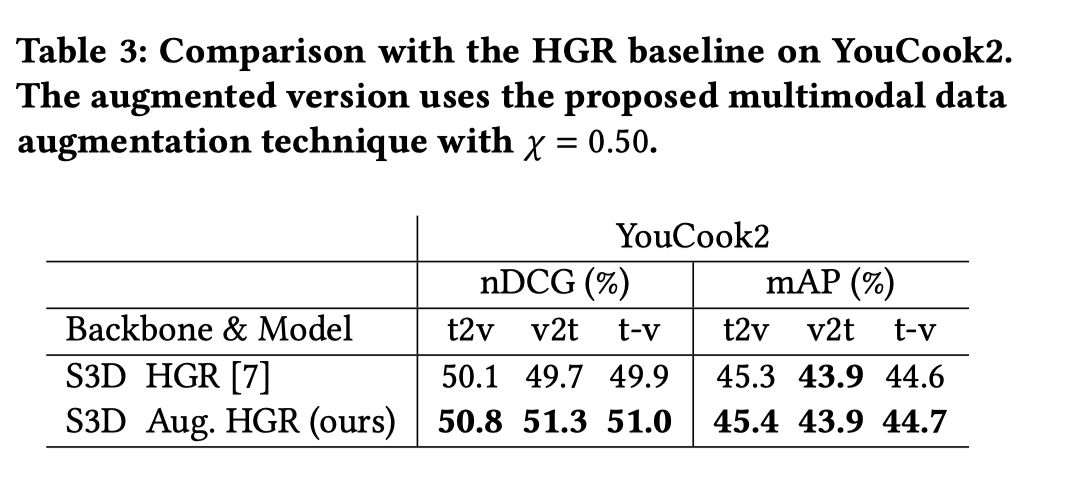
YouCook2上和baseline的对比结果。
5. 总结
本文介绍了一种工作在特征空间的多模态数据增强技术。通过这种方式,可以利用几个优势,包括处理从基于CNN的主干的更深层提取的高级概念的可能性,以及更容易的适用性,因为原始视频不需要共享,避免版权和隐私问题。为了验证本文的解决方案,作者在大规模公共数据集EPIC-Kitchens-100上进行了多次实验,并在YouCook2上进行了比较。作者在三种不同的方法上测试了本文的技术,包括最近在EPIC-Kitchens-100上使用的最先进的方法,并取得了进一步的改进。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









