









当你深入深度学习,调参却成 “拦路虎”。学习率、权重系数等参数稍调不对,模型就 “罢工”,最优参数组合更是难寻。
花大量时间调参,模型准确率却 “原地踏步”,过拟合、欠拟合还常来捣乱,不禁让人感叹:调参咋这么难?
神经网络架构复杂,参数设置变化无穷,尝试新组合不仅耗费资源,效果还不理想,调参痛点亟待破解。
今天就和大家好好聊聊调参这件事。
本章节内容颇为丰富,我们会以多篇文章的形式,逐一展开讲述。接下来,为大家呈现关于深度学习调参指南的内容导图 。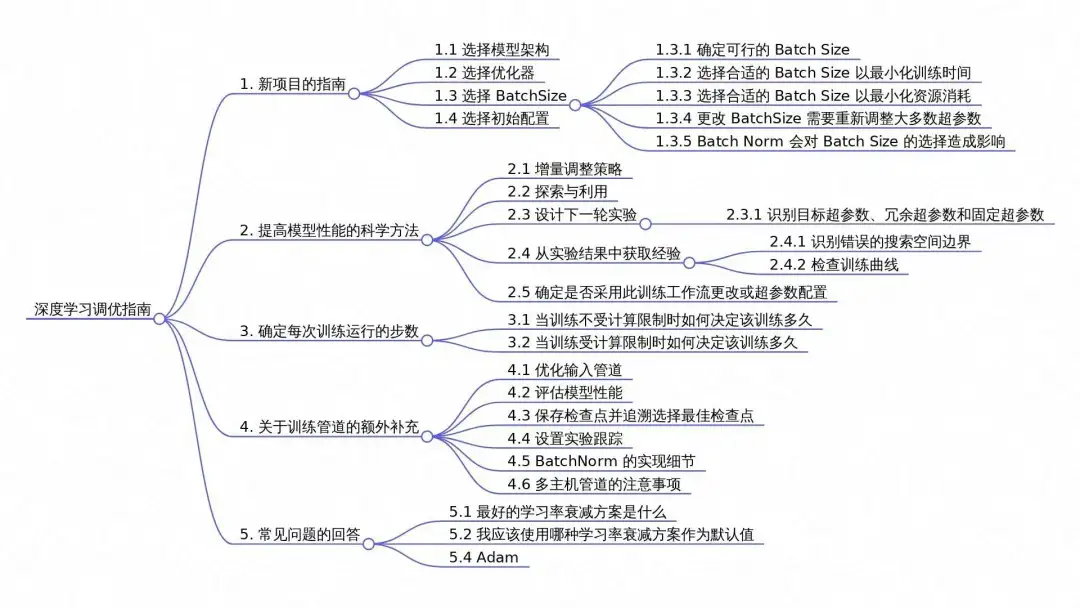
在正式开始之前,我把我们整理的《深度学习调参指南》教程分享给大家,希望对大家的学习有帮助!

在调优过程中的许多抉择,我们可以在项目开始时一次性做出决定。只有偶尔在情况发生变化时,才需要重新考虑。
在开始调优之前,请确保您满足以下假设:
-
问题制定、数据清理等基本工作已经完成,花时间在模型架构和训练配置上是有意义的。
-
已经有一个工作流设置用来进行训练和评估,并且可以很容易地为各种感兴趣的模型执行训练和预测工作。
-
已选择并实现适当的评估指标。这些指标应该尽可能地代表在部署环境中测量的内容。
一、快速开始一个新项目
1.1 选择模型架构
总结: 在开始一个新项目时,尽量重用有效的模型。
首先选择一个完善且常用的模型架构来开始工作。这样可以尽早让模型进入工作状态。
模型架构通常具有各种超参数,用于确定模型的大小和其他细节(例如层数、层宽度、激活函数类型)。因此,选择架构实际上意味着选择一整个系列的各种模型(每个模型都有不同的超参数设置)。
如果可以的话,请尝试找到一篇尽可能接近手头问题的相关论文,并将复现该论文中的模型作为起点。
1.2 选择优化器
总结: 从针对手头问题类型的最常用的优化器开始。
没有一个优化器是适用于所有类型的机器学习问题和模型架构的'最佳’优化器。即使只是比较优化器的性能也是一项艰巨的任务。我们建议坚持使用成熟、流行的优化器,尤其是在开始新项目时。常用且较为完善的优化器包括(但不限于):
-
SGD with momentum(Nesterov 变体)
-
Adam and NAdam,它们比具有动量的 SGD更通用。请注意,Adam有4个可调超参数,他们都很重要!
1.3 选择 BatchSize
总结: Batch Size 决定训练速度,并且不应该被直接用于调整验证集性能。通常来说,可用硬件支持的最大Batch Size 是较为理想的数值。
BatchSize是决定训练时间和计算资源消耗的关键因素
但是只要调整好所有超参数(尤其是学习率和正则化超参数)并且训练步数足够,理论上任意的Batch Size都能获得相同的最终性能。
1.3.1 确定可行的 Batch Size 并估计训练吞吐量
对于给定的模型和优化器,可用硬件通常能够支持一系列 Batch Size。限制因素通常是加速器(GPU/TPU等)的内存。
不幸的是,如果不运行或者编译完整的训练程序,就很难计算出适合内存的 Batch Size。
最简单的解决方案通常是以不同的批次大小(例如,用 2的幂来尝试)运行少量的训练实验,直到其中一个实验超过可用内存。

当加速器内存未饱和时,如果Batch Size加倍,训练吞吐量也应该加倍(或至少接近加倍)。等效地,随着Batch Size的增加,每步的时间应该是恒定的(或至少接近恒定的)。
如果与上述情况不符,那么训练工作流可能存在瓶颈,例如 I/O或计算节点间的同步。有必要在开始下一步前对此进行诊断和矫正。
如果训练吞吐量到某个 Batch Size 之后就不再增加,那么我们只考虑使用该 Batch Size (即使硬件支持更大的 Batch Size)
使用更大 Batch Size的前提是训练吞吐量也增加。如果没有,请修复瓶颈或使用较小的 Batch Size。
使用梯度积累技术可以支持的更大的 Batch Size。但其不提供任何训练吞吐量优势,故在应用工作中通常应避免使用它。
每次更改模型或优化器时,可能都需要重复这些步骤(例如,不同的模型架构可能允许更大的 Batch Size)。
1.3.2 选择合适的 Batch Size 以最小化训练时间

对于所有可行的 Batch Size,我们通常可以认为每步的时间近似恒定 (实际上,增加 Batch Size 通常会产生一些开销)。
Batch Size 越大,达到某一性能目标所需的步数通常会减少(前提是在更改 Batch Size 时重新调整所有相关超参数)。
例如,将 Batch Size 翻倍可能会使训练步数减半。这称为完美缩放。
完美缩放适用于 Batch Size 在临界值之前,超过该临界总步数的减少效果将会下降。
最终,增加 Batch Size 不会再使训练步数减少(永远不会增加)。
通常,可用硬件支持的最大 Batch Size 将小于临界 Batch Size。因此,一个好的经验法则(不运行任何实验)是使用尽可能大的 Batch Size。
如果最终增加了训练时间,那么使用更大的 Batch Size 就没有意义了。
1.3.3 选择合适的 Batch Size 以最小化资源消耗
有两种类型的资源成本与增加 batch size 有关:
-
前期成本,例如购买新硬件或重写训练工作流以实现多 GPU/多 TPU 训练。
-
使用成本,例如,根据团队的资源预算计费,从云供应商处计费,电力/维护成本。
如果增加 batch size 有很大的前期成本,那么直到项目成熟且容易权衡成本效益前,推迟增加可能更好。
实施多机并行训练程序可能会引入错误和一些棘手的细节,所以无论如何,一开始最好是用一个比较简单的工作流。(另一方面,当需要进行大量的调优实验时,训练时间的大幅加速可能会在过程的早期非常有利)。
增加 batch size 通常可以减少总步骤数。资源消耗是增加还是减少,将取决于每步的消耗如何变化。
-
增加 batch size 可能会减少资源消耗。
例如,如果大 batch size 的每一步都可以在与小 batch size 相同的硬件上运行(每一步只增加少量时间),那么每一步资源消耗的增加可能被步骤数的减少所抵消。
-
增加 batch size 可能不会改变资源消耗。
例如,如果将 batch size 增加一倍,所需的步骤数减少一半,所使用的 GPU 数量增加一倍,总消耗量(以 GPU 小时计)将不会改变。
-
增加 batch size 可能会增加资源消耗。
例如,如果增加 batch size 需要升级硬件,那么每步消耗的增加可能超过训练所需步数的减少。
1.3.4 更改 BatchSize 需要重新调整大多数超参数
大多数超参数的最佳值对 Batch Size 敏感。因此,更改 Batch Size 通常需要重新开始调整过程。
与 Batch Size 交互最强烈的超参数是优化器超参数(学习率、动量等)和正则化超参数,所以有必要对于针对每个 Batch Size 单独调整它们。
在项目开始时选择 Batch Size 时请记住,如果您以后需要切换到不同的 Batch Size,则为新的 Batch Size 重新调整所有内容可能会很困难、耗时且成本高昂。
1.4 选择初始配置
在开始超参数调整之前,我们必须确定起点,包括指定模型配置(例如层数),优化器超参数(例如学习率),以及训练步数。
小结
本篇围绕快速开启新项目,核心观点有:
-
选完善常用模型架构,可复现相关论文模型起步;
-
用成熟流行优化器,如SGD with momentum、Adam等 ;
-
依硬件确定BatchSize,兼顾训练吞吐量、时间和资源消耗,且更改需重调超参数;
-
确定模型、优化器超参数等初始配置。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









