







1. 基于规则的风险分类
风险分类是网络安全系统的核心能力之一,它将访问请求和命令映射到其风险级别/类别:高(High)、中(Medium)、低(Low)。目前,即便是在大规模环境中,风险分类器仍主要采用基于规则的系统实现。基于规则的分类器易于以符合人类直觉的方式定义——这也使得它们具备较好的可解释性。
在其最简单的形式下[1],基于规则的分类器可以被视为if-then-else规则,明确规定哪些访问请求应被阻止(黑名单)或允许(白名单)。在规则的编写语法中,正则表达式被广泛使用,以便单条规则可以适用于多个请求/命令。这些规则被存储在规则数据库(rules DB)中。而输入请求的执行历史及其确定的风险级别会被汇总存储在日志数据库(logs DB)中,以供离线审查/审计。此类基于规则的分类器的参考架构如图1所示。
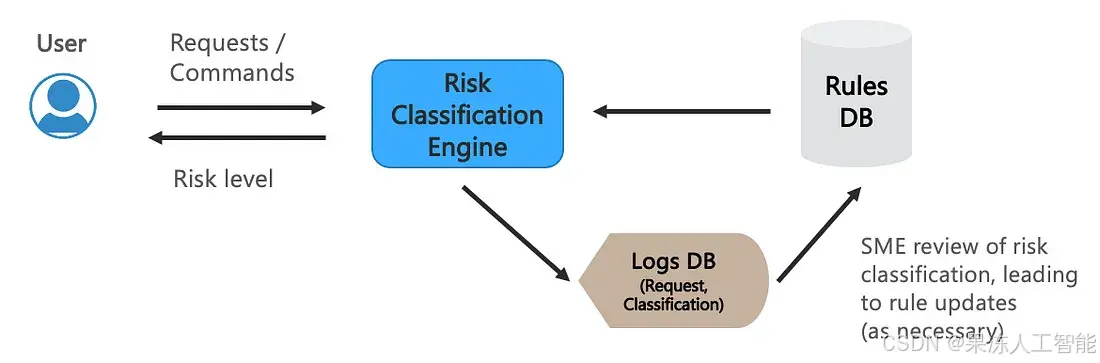
图1:基于规则的风险分类架构(作者绘制)
这些规则通常由领域专家(SMEs)基于他们对底层系统的专业知识和经验定义。他们还会定期审查执行历史,以确保规则的正确性,并据此在规则数据库中添加/更新规则。由于这一点,基于规则的分类器的覆盖范围和有效性取决于个人的经验/历史,这可能会与真正的风险级别存在偏差。
此外,基于规则的分类器需要定期维护和手动修订,以适应不断演变的系统环境、新的访问控制策略和命令。而正则表达式也无法有效处理复杂(或冗长的)策略、命令和程序。
从基于规则的方法转换为基于机器学习(ML)的方法[2],能够减少对SME的依赖,同时具备自学习能力,能够扩展到新的流程和规则。近些年来,大型语言模型(LLMs)在这一方面展现出极大的潜力。我们将介绍一种方法,利用现有规则来提升分类准确性,并迁移到基于Transformer的安全风险分类器。
2. 企业级大型语言模型(LLMs)
LLMs属于基础模型(充当解码器)的一类,需要进行微调,以完成诸如以下任务:
• 问答(QA)——例如聊天机器人
• 文本抽取
• 摘要生成
• 自动更正
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









