







1、机器学习的基本概念
- 监督学习:一个机器学习中的方法,可以由训练资料中学到或建立一个模式( learning model),并依此模式推测新的实例。训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)。
- 监督式学习:输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
- 泛化能力:指由该方法学习到的模型对未知数据的预测能力, 是学习方法本质上重要的性质。
- 过拟合与欠拟合可以用一张图来说明:

注释:左一为欠拟合,右一为过拟合。 - 欠拟合:因为对于给定数据集,欠拟合的成因大多是模型不够复杂、拟合函数的能力不够。 为此可以增加迭代次数继续训练、尝试换用其他算法、增加模型的参数数量和复杂程度,或者采用Boosting等集成方法。
- 过拟合:过拟合成因是给定的数据集相对过于简单,使得模型在拟合函数时过分地考虑了噪声等不必要的数据间的关联。或者说相对于给定数据集,模型过于复杂、拟合能力过强。
- 线性回归的原理
1、线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性
模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真
实值之间的误差最小化。
假设有数据集 ( x 1 ( 0 ) , x 2 ( 0 ) , . . . , x n ( 0 ) , y 0 ) , ( x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , y 1 ) , . . . ( x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , y m ) (x_1^{(0)},x_2^{(0)},...,x_n^{(0)},y_0),(x_1^{(1)},x_2^{(1)},...,x_n^{(1)},y_1),...(x_1^{(m)},x_2^{(m)},...,x_n^{(m)},y_m) (x1(0),x2(0),...,xn(0),y0),(x1(1),x2(1),...,xn(1),y1),...(x1(m),x2(m),...,xn(m),ym)
根据以上m个观测,怎么推出下一组的 y n y_n yn,线性回归的模型拟合如下:
h
v
(
x
1
,
x
2
,
.
.
.
,
x
n
)
=
v
0
+
v
1
∗
x
1
+
v
2
∗
x
2
.
.
.
+
v
n
∗
x
n
=
∑
i
=
1
n
v
i
x
i
h_v(x_1,x_2,...,x_n)=v_0+v_1*x_1+v_2*x_2...+v_n*x_n=\sum_{i=1}^nv_ix_i
hv(x1,x2,...,xn)=v0+v1∗x1+v2∗x2...+vn∗xn=∑i=1nvixi。
矩阵形式为
h
v
(
X
)
=
X
V
h_v(X)=XV
hv(X)=XV
假设函数
h
v
(
X
)
h_v(X)
hv(X)为mX1的向量,V为nx1的向量,里面有n个代数法的模型参数。X
为mxn维的矩阵。m代表样本的个数,n代表样本的特征数。
损失函数、代价函数、目标函数的定义见下:
损失函数:计算的是一个样本的误差
代价函数:是整个训练集上所有样本误差的平均
目标函数:代价函数 + 正则化项
- 线性回归的损失函数
一般线性回归我们用均方误差作为损失函数。损失函数的代数法表示如下:
J ( v 0 , v 1 , . . . , v n ) = ∑ i = 0 m ( h v ( x 0 , x 1 , . . . , x n ) − y i ) 2 J(v_0,v_1,...,v_n)=\sum_{i=0}^m(h_v(x_0,x_1,...,x_n)-y_i)^2 J(v0,v1,...,vn)=∑i=0m(hv(x0,x1,...,xn)−yi)2
矩阵表达方式: J ( v ) = 1 2 ( X V − Y ) T ( X V − T ) J(v)=\frac{1}{2}(XV-Y)^T(XV-T) J(v)=21(XV−Y)T(XV−T)
- 线性回归的代价函数
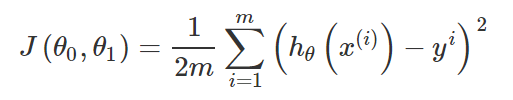
回归函数的目标函数一般使用均方误差,同上损失函数。
线性回归参数估计的方法有二:最小二乘法与梯度下降法
最小二乘法:
一元回归:

多元线性回归:



梯度下降法训练参数法:

- 线性回归模型的性能评价指标
残差估计:总体思想是计算实际值与预测值间的差值简称残差。从而实现对回归模型的评估,一般可以画出残差图,进行分析评估、估计模型的异常值、同时还可以检查模型是否是线性的、以及误差是否随机分布。
均方误差:最小化误差平方和(SSE)代价函数的平均值。
决定系数
转载学习自:
基本概念:https://www.cnblogs.com/pinard/p/6004041.html
参数推导:https://blog.csdn.net/zengfanj7041/article/details/78047159















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









