







线性模型:通过属性的线性组合来进行预测的函数:

线性回归:通过一个或者多个自变量与因变量之间之间进行建模的回归分析。其中特点为一个或多个称为回归系数的模型参数的线性组合
一元线性回归:涉及到的变量只有一个
多元线性回归:涉及到的变量两个或两个以上
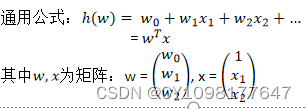
损失函数(误差大小)有被成为最小二乘法
是很亮误差大小使用,方便记忆为误差平方和
损失函数的作用是:求模型当中的W,使得损失最小? (目的是找到最小损失对应的W值)
进行损失函数后优化的方法有
1.正规方程(不建议使用)
2.梯度下降法
梳理的逻辑:
线性回归:是模型的基本算法
损失函数:是一种策略来进行损失W值的计算
正规方程和梯度下降:类似于对损失函数结果的优化
均方误差(MSE) 评价机制:查看预测值与训练值的差值大小
python操作的步骤
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor # 导入机器学习库中的线性回归模块
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error #导入均方误差MSE
def mylinear():
"""
线性回归直接预测房子价格
:return: None
"""
#获取数据
lb =load_boston()
#分割数据集到训练集和测试集
x_train, x_test, y_train, y_test= train_test_split(lb.data, lb.targrt, test_size=0.25)
print(y_train, y_test)
#进行标准化处理 特征值和目标值都进行标准化处理 ,实例量标准化API
std_x =StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y =StandardScaler()
y_train = std_x.fit_transform(y_train)
y_test = std_x.transform(y_test)
#estimator预测
#正规方程
#lr = LinearRegression()
#lr.fit(x_train,y_train)
#print(lr.coef_) ## 回归系数
#梯度下降
lr = SGDRegressor()
lr.fit(x_train,y_train)
print(lr.coef_)
#预测测试集的房子价格
lr.predict(x_test)
y_predict = std_y.inverse_transform(lr.predict(x_test)) #将标准化后的数组转换为正常数组
print("测试集里每个房子的预测价格:",y_predict)
print("均方误差:",mean_squared_error(std_y.inverse_transform(y_test),y_predict))
if __name__ == "__Mia__":
mylinear()
在estimate预测地方:是使用正规方程和梯度下降法的地方。
问题:训练数据很好,MSE不大,但是测试集有问题?
这是出现过拟合或者欠拟合现象
欠拟合:训练数据不能获得好的拟合,在训练集以外的数据也不能很好的拟合,模型过于简单
原因是学习到的数据特征过少
解决方法:增加数据的特征数量
过拟合:训练数据能能获得好的拟合,在训练数据以外的数据不能很到的拟合,模型过于复杂
原因:复杂运用是因为特征和目标值的关系不仅仅是线性关系,或者原始特征过多
解决方法:1. 进行特征选择,消除关联性大的特征(很难)
2.交叉验证(让所有数据都有过训练)
3. 正则化
















 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









