








代码:https://github.com/omriav/blended-latent-diffusion/tree/master
服务:简历修改、面试辅导可以私戳~
在本文中,我们提出了一种加速解决方案,用于通用图像的局部文本驱动编辑任务,其中所需的编辑仅限于用户提供的掩码。我们的解决方案利用了文本到图像的潜在扩散模型(LDM),该模型通过在低维潜在空间中操作来加速扩散,并消除了在每个扩散步骤进行资源密集型CLIP梯度计算的需要。我们首先使LDM能够通过在每个步骤blend latent来执行局部图像编辑,类似于Blended Diffusion。接下来,我们提出了一种基于优化的解决方案,以解决LDM固有的无法准确重建图像的问题。最后,我们讨论了使用mask执行局部编辑的场景。
一、Background
绝大多数text-guidance文本引导方法都侧重于从头开始生成图像或在全局范围内操纵现有图像。尽管这种用例在实践中无处不在,但艺术家只对修改通用图像的一部分感兴趣,同时保留其余部分的本地编辑场景并没有得到那么多的关注。迄今为止,我们只知道三种明确解决局部编辑问题的方法:Blend Diffusion、GLIDE和DALL·E 2。其中,只有Blend Diffusion是完整公开的。
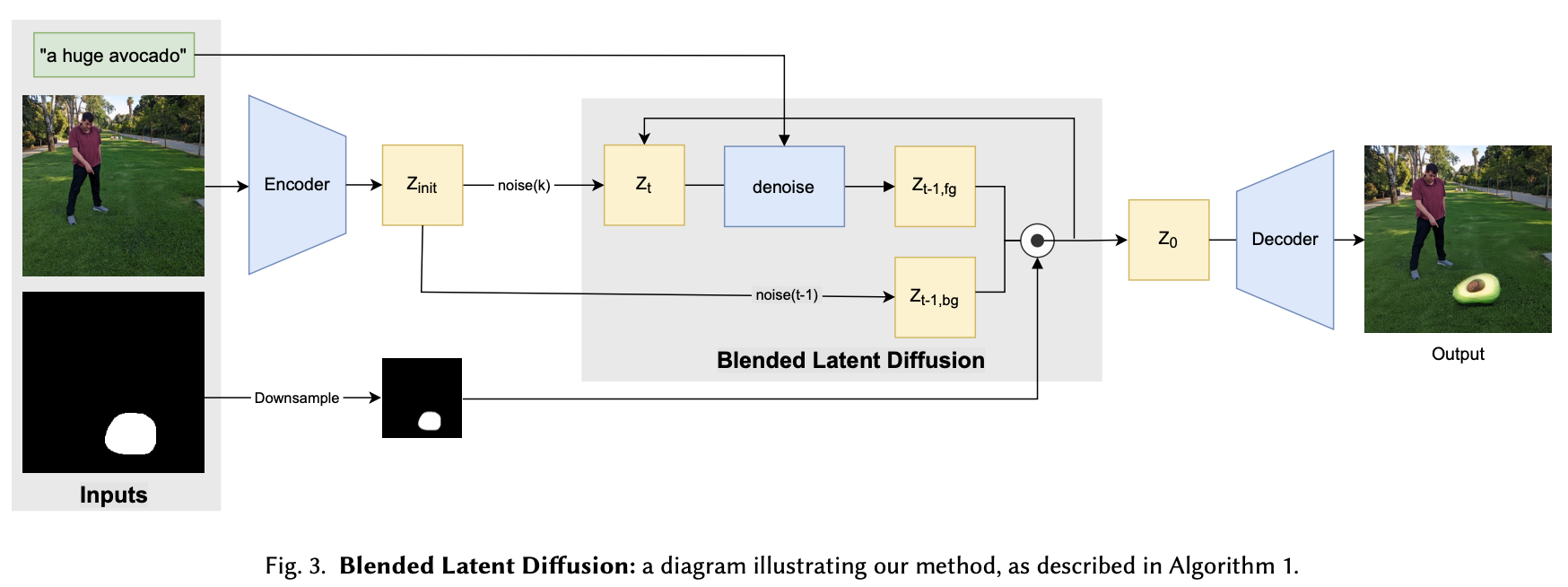
在这项工作中,我们利用LDM的优点进行local text-guidance的自然图像编辑,用户提供要编辑的图像、自然语言文本提示和指示编辑应限制区域的掩码。我们的方法是“zero-shot”,因为它依赖于可用的预训练模型,不需要进一步的训练。我们首先展示了如何将Avrahami等人[2022b]的混合扩散方法应用于LDM的潜在空间,而不是像素级。
接下来,我们将解决LDM固有的不完美重建问题,这是由于使用了基于VAE的有损潜在编码。当原始图像包含人类感知特别敏感的区域(例如面部或文本)或其他非随机高频细节时,这尤其成问题。我们提出了一种利用潜在优化来有效缓解这一问题的方法。
最后,我们使用我们提出的文本驱动编辑方法的新指标:精度和多样性,对基线进行定性和定量评估。
综上所述,本文的主要贡献是:(1)将文本到图像LDM应用于局部文本引导的图像编辑任务。(2) 解决了LDM中重建不准确的固有问题,这严重限制了该方法的适用性。(4) 提出新的评估指标,用于对局部文本驱动的编辑方法进行定量比较。

二、Method
DALL·E提出了一种两阶段方法:首先,训练一个离散的VAE来学习丰富的语义上下文,然后训练一个Transformer模型来对文本和图像token的联合分布进行自回归建模。
DALL·E 2通过将文本提示映射到CLIP图像嵌入中,然后将这些嵌入解码为图像,来执行文本到图像的合成。
混合扩散(Blended Diffusion)解决了零样本文本引导的局部图像编辑问题。该方法利用在ImageNet上训练的扩散模型,作为自然图像流形的先验,以及CLIP模型,将扩散模型引导至所需的文本指定结果。为了创建仅修改mask区域以符合引导文本提示的无缝结果,CLIP引导过程逐步生成的每个噪声图像都与输入图像的相应噪声版本在空间上混合。这种方法的主要局限性是推理时间慢(使用GPU约25分钟)和像素级噪声伪影(见图2)。
2.1 Blended Latent Diffusion
2.2 Background Reconstruction
VAE编码存在导致背景重建不精确,处理此问题的一种天真方法是使用输入掩码m在像素级别缝合原始图像和编辑结果。然而,由于未mask区域不是由decoder生成,无法保证生成的部分将与周围背景无缝融合。潜在空间优化无法捕捉高频细节,这表明解码器的表现力是有限的。受这种方法的启发,我们可以通过在每个图像的基础上微调解码器的权重来实现无缝克隆:
![]()
2.3 Progressive Mask Shrinking
当输入掩码𝑚较小的时候,在其缩小的m-lantent潜在版本中可能会变得更小,以至于通过文本驱动的扩散过程改变潜在值无法在重建结果中产生明显的变化。为了查明根本原因,我们将扩散过程可视化:给定一个有噪声的潜在时间步长𝑡, 我们可以使用Song等人[2020]推导的闭式公式,通过单个扩散步骤来估计𝑧0。然后使用VAE解码器𝐷(𝑧0)推断出相应的图像。
这种理解表明了渐进式mask缩小的想法:因为早期的noisy latents只对应于粗糙的颜色和形状,所以我们从一个粗糙的、膨胀的m-lantent,然后逐渐缩小,只有最后的去噪步骤将fg与bg混合时使用小的mask-latent。
2.4 Prediction Ranking
由于扩散过程的随机性,我们可以对相同的输入生成多个预测,这是可取的,因为我们的问题具有一对多的性质。我们根据其CLIP嵌入与引导提示的CLIP嵌入d之间的正态余弦距离对预测进行排序。

三、使用场景&不足
Text-driven object editing; Scribble-guided editing; Background replacement.
缺点:(1)我们观察到LDM生成文本的惊人能力是一把双刃剑:指导文本可能被模型解释为文本生成任务;(2)与混合扩散一样,基于CLIP的排名只考虑生成的mask区域。如果没有更全面的图像视图,这种排名会忽略输出图像的整体真实感,这可能会导致图像中的每个区域都是真实的,但图像整体看起来并不真实。
目标:给定图像𝑥,一个引导文本提示𝑑和一个标记图像中感兴趣区域的二进制掩码𝑚,我们的目标是生成一个修改后的图像𝑥ˆ,内容𝑥ˆ⊙𝑚与文本描述𝑑一致,当互补区域保持靠近源图像时。𝑥 ⊙ (1−𝑚) ≈ 𝑥ˆ ⊙ (1−𝑚), 其中⊙是元素乘法。此外,𝑥ˆ两个区域之间的过渡在理想情况下应该是无缝的。
去噪扩散过程如下:在每一步中,我们首先执行一个潜在的去噪步骤,直接以引导文本提示d为条件,以获得一个噪声较小的前景潜在信号,记为z-fg,同时将原始潜在的z-init噪声化到当前噪声水平,以获得噪声较大的背景潜在信号z-bg。然后使用调整大小的掩模将这两个潜在信号混合,即z-fg⊙m-latent+z-bg⊙(1-mlatent),以产生下一个潜在扩散步骤的潜在信号。
我们解决了由于使用基于VAE的有损潜在编码而导致的LDM固有的不完美重建问题:潜在空间优化无法捕获高频细节,这表明解码器D(z)的表现力是有限的。受这种方法的启发,微调每幅图像的GAN生成器权重可以获得更好的重建,我们可以通过在每幅图像上微调解码器的权重来实现无缝克隆。
我们解决了在thin mask内执行局部编辑的挑战:渐进式mask缩小,因为早期的noisy lantent只对应于粗糙的颜色和形状,我们从一个粗糙的、扩张的m-latent版本开始,并随着扩散过程的进展逐渐缩小它。只有最后一个去噪步骤使用了薄m-latent掩模。


https://zhuanlan.zhihu.com/p/730832262
整体来说,基于 Diffusion 的 inpating 方法可以分为无需训练和需要训练两个大类。其中无需训练的方法主要是根据 mask 来调整采样策略,将掩码区域的去噪生成结果与掩码外区域的加噪结果进行混合(blend)。而需要训练的方法又可分为微调模型本身和添加额外的网路分支两类。核心就是更精细的像素级控制。PowerPaint 则通过设置可学习的 prompt,进一步实现了多功能的 inpainting 模型。
无需训练
- 调整采样策略
- Blended Diffusion:DDPM + CLIP Classifier Guidance
- Blended Latent Diffusion:LDM + Classifier-free Guidance
- Repaint
需要训练
- 微调
- GLIDE/Kolors inpainting
- Smart Brush
- PowerPaint:多功能
- 额外的网络分支
- ControlNet inpainting
- BrushNet
- PowerPaint-v2:PowerPaint + BrushNet


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











