







论文:A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
代码:PowerPaint
其他:支持CV算法resume修改、面试fudao

PowerPaint是第一个在各种修复任务中同时实现最先进结果的通用图像绘制模型,包括文本引导的对象修复、对象移除、具有可控形状拟合的形状引导对象修复、外涂等。【新增物体、移除物体、图像扩展、形状可控】
一、背景
图像修复旨在用合理的内容填充图像中用户指定的区域,如背景填充和目标合成。现有的方法侧重于使用文本描述的上下文感知填充或目标合成。然而,由于训练策略不同,同时完成这两项任务具有挑战性。为了克服这一挑战,我们推出了PowerPaint,这是第一个高质量、多功能的修复模型,擅长多种绘画任务,在text-guided object inpainting and context-aware image inpainting方面都表现出色。
首先,我们引入可学习的任务提示task prompts以及量身定制的微调策略tailored training strategies,以明确地引导模型专注于不同的修复目标。这使得PowerPaint能够通过使用不同的任务提示来完成各种修复任务,从而获得最先进的性能。其次,我们展示了PowerPaint中任务提示多样性,通过展示其作为对象删除负面提示的有效性。
早期工作:侧重于上下文感知图像修复,其中模型是通过随机掩蔽图像中的一个区域并重建原始内容来训练的,然而,这些模型在合成新目标时遇到了挑战,因为它们仅依赖于上下文来推断缺失的内容。
最近进展:已经转向文本引导text-guidance的图像修复,其中使用mask和文本描述对预训练的T2I模型进行微调,从而在目标合成方面取得了显著成果。【1. Smartbrush: Text and shape guided object inpainting with diffusion model;2.Uni-paint: A unified framework for multimodal im- age inpainting with pretrained diffusion model;3.Imagen editor and editbench: Advancing and evaluating text-guided image inpainting】
特别是,现有的T2I模型采用了无分类器的引导采样策略,其中负提示可以有效地抑制不期望的影响[8,13]。通过利用这种采样策略并将Pctxt指定为正提示,将Pobj指定为负提示,PowerPaint有效地防止了不需要的对象的生成,并促进了目标区域的无缝背景填充,从而显著提高了对象删除的效率[25]。
二、方法
![]()
![]()
为了微调用于修复的Stable Diffusion,PowerPaint首先扩展去噪网络εθ的第一个卷积层,并为掩模图像x0⊙(1-m)和掩模m专门设计了五个额外的通道。PowerPaint的输入由带噪的潜像noisy latent、mask图像和mask组成,表示为x′t。此外,去噪过程可以通过文本y等附加信息来指导。该模型通过以下方式进行优化:
其中τθ(·)是CLIP文本编码器。重要的是,PowerPaint通过引入可学习的任务提示来扩展文本条件,这些提示为模型完成各种修复任务提供了指导。
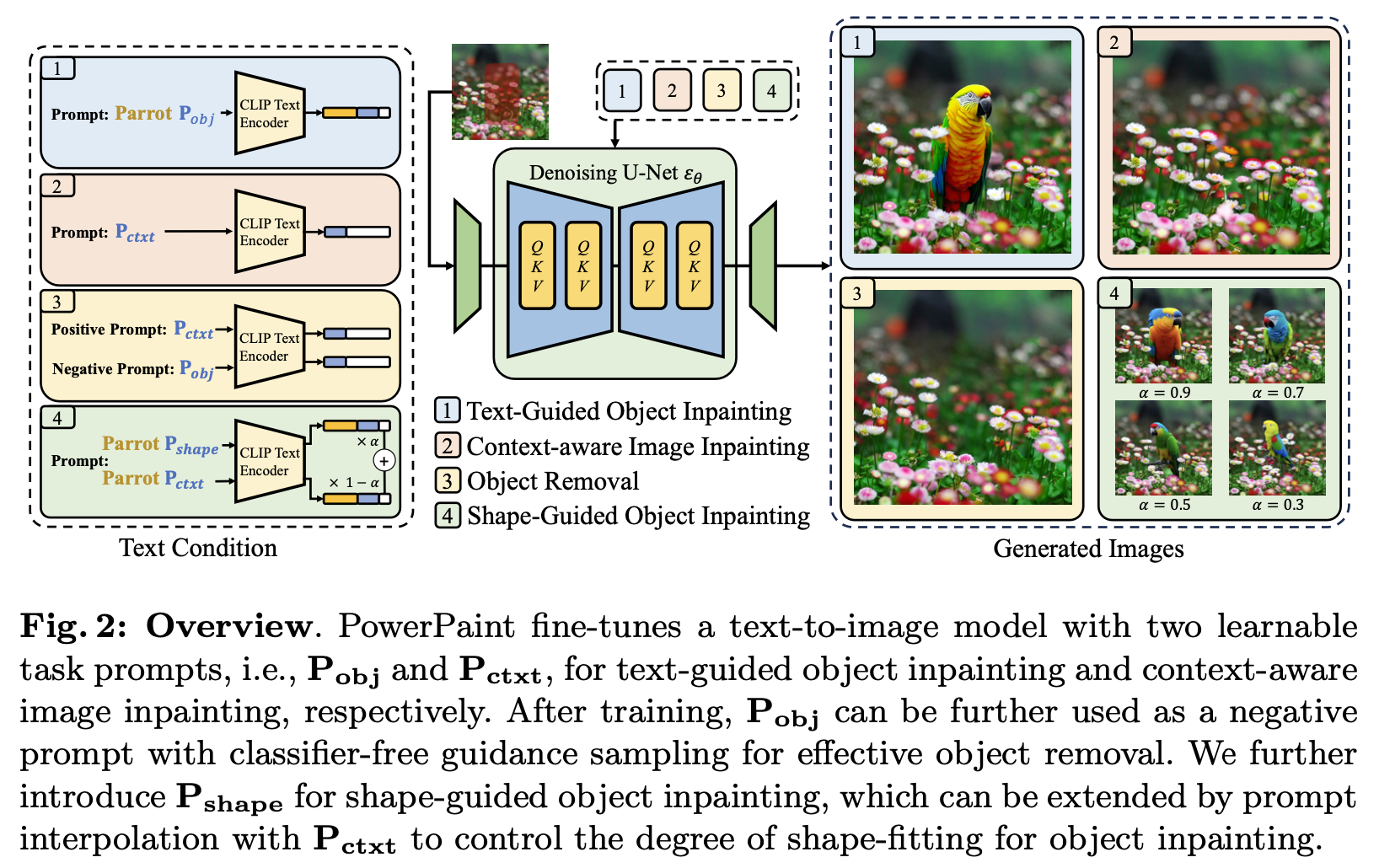
3.2 Learning with Task Prompts
为了微调预训练的text-to-image模型,以实现高质量和多功能的修复,我们引入了三个可学习的任务提示:Pobj、Pctxt和Pshape。为了将这两个不同的目标无缝集成到一个统一的模型中,我们建议为每个任务使用两个可学习的任务提示。
Context-aware Image Inpainting. 上下文感知图像修复旨在用与周围图像上下文无缝集成的内容填充用户指定的区域。为了实现这一点,我们引入了一个可学习的任务提示,表示为Pctxt,它在训练过程中充当文本条件。此外,作为训练过程的一部分,我们随机屏蔽图像区域。在模型微调过程中,Pctxt通过以下方式进行优化:
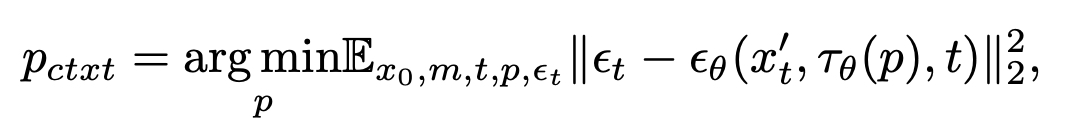
其中p被随机初始化为token array,然后用作文本编码器的输入。这种公式使用户能够无缝地填充具有连贯内容的区域,而无需明确指定所需的内容。
Text-guided Object Inpainting. 合成不能仅从图像上下文中推断出的新对象通常需要文本提示提供的额外指导。为了实现这一点,我们引入了一个可学习的任务提示,表示为Pobj,它作为文本引导对象修复的任务提示。具体来说,Pobj与上述方程具有相似的优化函数,但有两个不同之处。首先,对于给定的训练图像,我们利用检测对象的边界框作为inpaint mask。其次,我们将Pobj作为后缀附加到掩码区域的文本描述中,作为文本编码器的输入。经过训练,我们的模型有效地学习了根据给定的上下文或文本描述输入修复图像。
Object Removal. PowerPaint可用于对象删除,用户可以使用掩码覆盖整个对象,并在任务提示Pctxt上调整模型以填充连贯的内容。然而,当试图在拥挤的环境中删除对象时,它变得更加具有挑战性。我们怀疑,包括注意力层在内的固有网络结构导致模型过度关注上下文。这使得模型更容易从拥挤的上下文中“copy”信息并将其“paste”到mask区域,从而实现对象合成而不是删除。
![]()

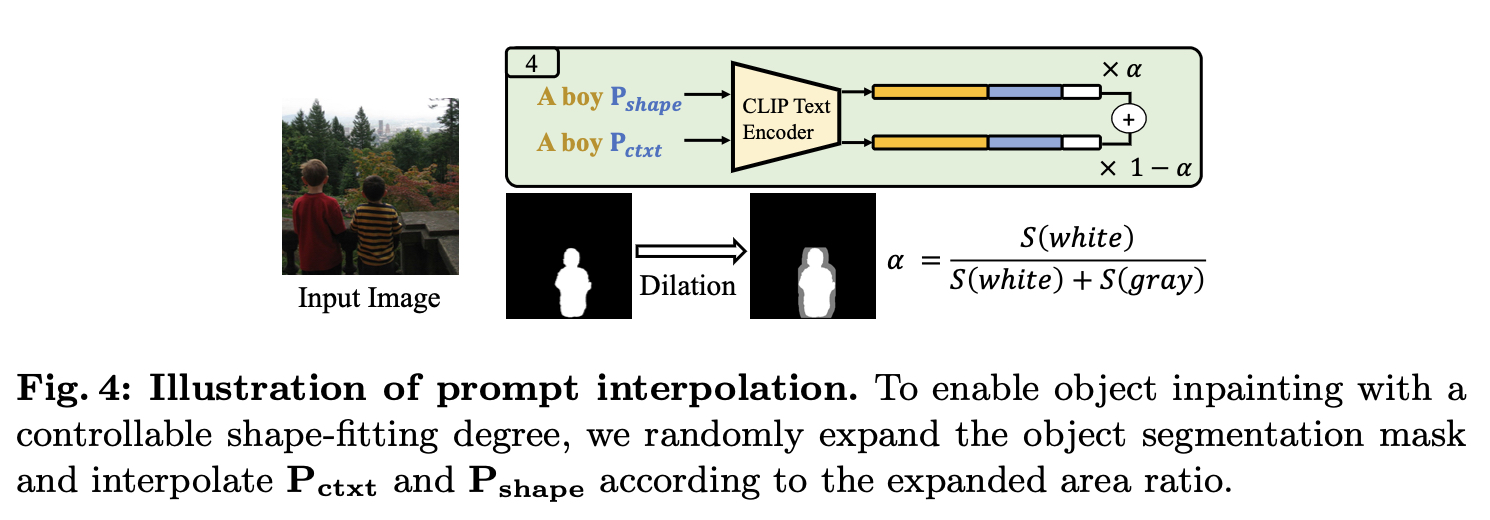
Controllable Shape Guided Object Inpainting. 在本部分中,我们将探讨形状引导对象修复,其中生成的对象与给定的mask形状很好地对齐。为了实现这一点,我们引入了第三个任务提示,称为Pshape,它是在前面的工作之后使用精确的对象分割掩码和对象描述进行训练的然而,我们注意到,仅依赖Pshape可能会导致模型过度拟合mask形状,而忽略对象的整体形状。例如,当提供提示“猫”和方形mask时,模型可以在方形mask内生成猫纹理,而不考虑猫的真实形状。
为了解决上述局限性,为用户提供更合理、更可控的形状引导物体修复,我们提出了任务提示插值task prompt interpolation。我们首先使用基于卷积的膨胀操作D随机膨胀对象分割掩模,该操作表示为:
![]()
其中k表示核大小,it表示膨胀的迭代。这将生成一组与对象形状具有不同拟合度的mask。 对于每个训练mask,我们计算面积比α,表示拟合程度。较大的α表示更接近mask形状,而较小的α表示拟合度较低。为了执行提示插值,我们将Pshape和Pctxt作为后缀附加到文本描述y中,并将它们分别输入到CLIP文本编码器中。这产生了两个文本嵌入。通过基于α的值线性插值这些嵌入,如图4所示,我们得到了最终的文本嵌入,表示为:
![]()
训练后,用户可以调整α的值,以控制生成的对象与mask形状的拟合程度。
3.3 Implementation Details
我们基于SD v1.5模型对CLIP文本编码器和U-Net的嵌入层中的任务提示进行了微调。PowerPaint在8个A100 GPU上进行了25K迭代的训练,批处理大小为1024,学习率为1e-5。我们使用OpenImage v6[15]的语义分割子集作为多任务提示调优的主要数据集。此外,根据Smartbrush[34],我们使用分割标签和BLIP caption作为本地文本描述。同时,我们将文本到图像的生成任务视为修复(掩盖一切)的特例,并使用LAION美学v2 5+[28]中的图像/文本对进行训练。在训练阶段,主任务和文本到图像生成任务的概率分别为80%和20%。
3.4 Evaluation Metrics
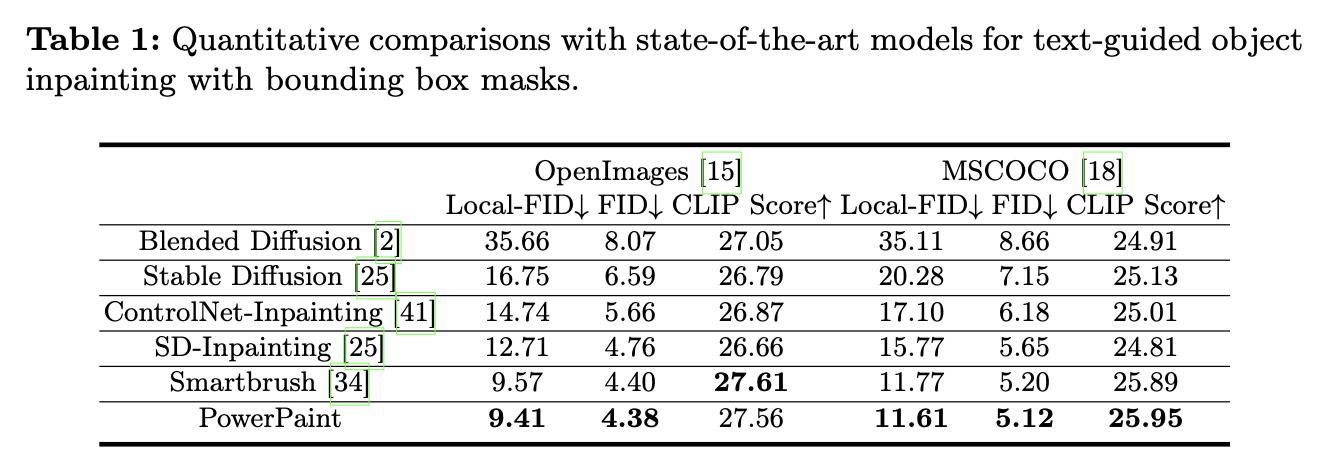
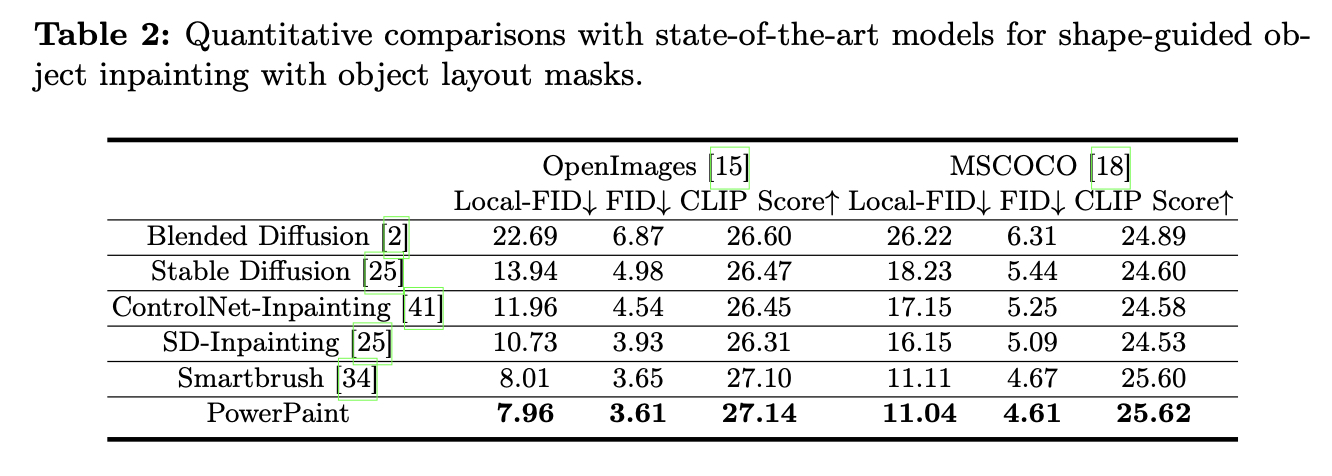
我们使用Fréchet Inception Distance(FID)、local-FID、CLIP评分、LPIPS和aesthetic score作为不同修复任务的数字指标。具体来说,我们使用FID和局部FID来获得全局和局部图像的视觉质量。CLIP评分用于文本引导对象修复,以评估生成的视觉内容与文本提示的对齐情况。




















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











