







 Transformer可以说是NLP划时代的论文,之后的bert等模型都借鉴了Transformer的attention机制
Transformer可以说是NLP划时代的论文,之后的bert等模型都借鉴了Transformer的attention机制
1、概要
transformer的最核心思想是抛弃了传统的sequence aligned的RNN和CNN方法,转而使用纯attention来做sequence数据的处理。得到的效果是非常显著的,不仅达到了stoa,而且更容易并行化的进行训练。
2、模型结构
整体上仍然是encoder-decoder结构,encoder和decoder都使用stacked self-attention和point-wise 全连接层,本节将分别介绍下图中的各个神经层的设计理念。
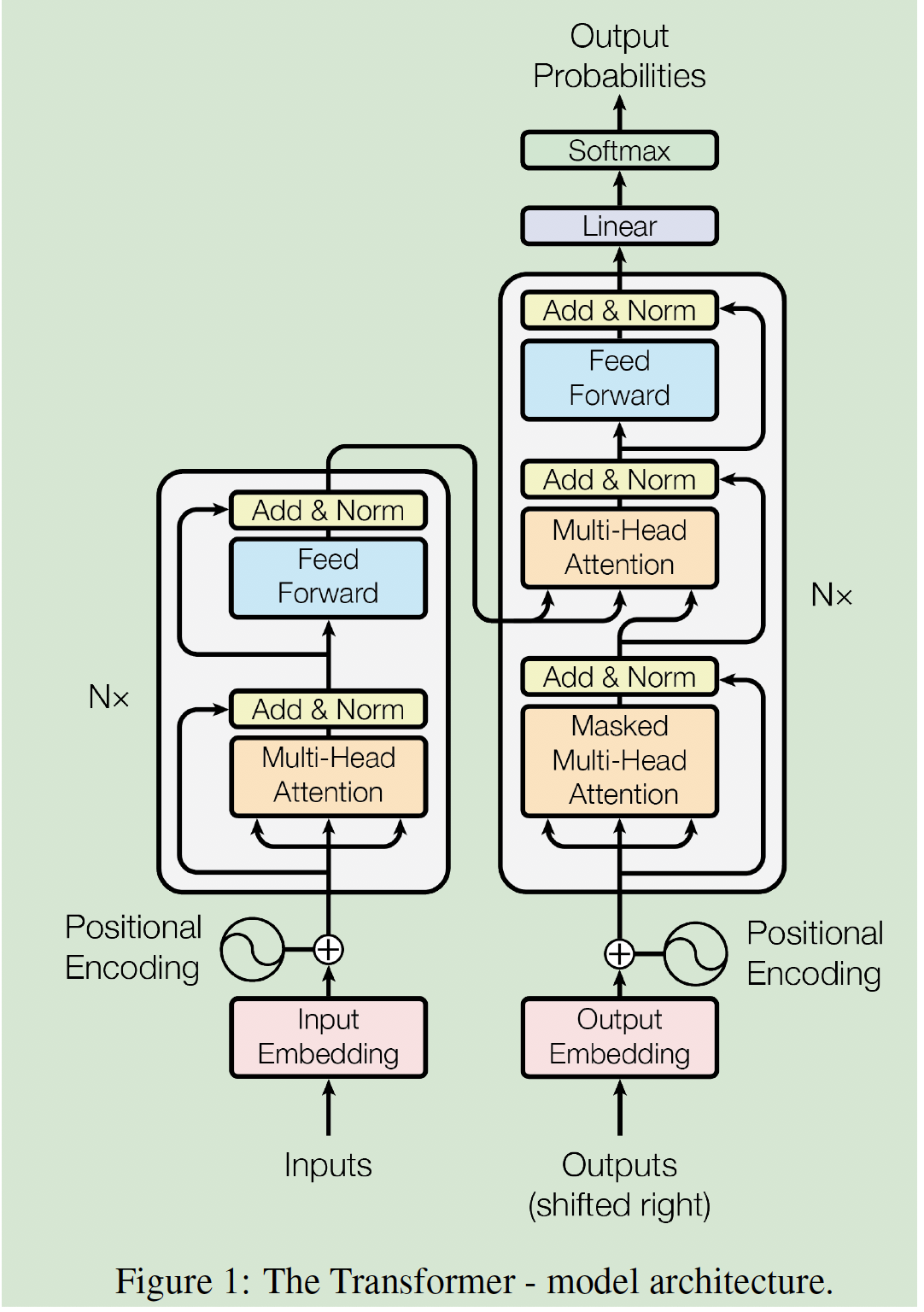
2.1 输入和输出
这个网络的encoder和decoder输入分别是原序列和目标序列的token经过embedding之后的dense vector,decoder的输出经过线性变换和softmax后预测下一个token出现的概率分布,并与目标序列的下一个值计算loss。(所以预测的时候还是需要逐步迭代,但是训练的时候就可以并行)
2.2 模型整体结构: Encoder and Decoder Stacks
编码器是由里6个相同的神经层堆叠而成的,每层含有两个子层,分别是一个多头注意力层和一个point-wise的全连接层。同时本文还在每个子层的首尾添加了残差连接,并在残差连接之后进行Layer Normalization(注意这里不是BatchNorm,而是arXiv:1607.06450中的LayerNorm)。所有的子层以及embedding层的输出都是512维。
解码器仍然是6个神经层的堆叠,不同的是在中间加入了一个额外的多头注意力层用来作用于编码器的输出,然后将第一个注意力层改为masked多头注意力层,保证解码 i i i 位置时只能看到之前的结果。
2.3 模型核心:Scaled Dot-Product Attention 函数
首先介绍多头注意力中的“一头”。每个词语先通过word embedding转化为512维( d m o d e l = 512 d_{model}=512 dmodel=512)的向量,然后这个向量通过三个转换矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV 分别输出其对应的query、key和value向量Q、K、V,query和key向量维度为 d k d_k dk, value向量的维度为 d v d_v dv。那么经过注意力层后,每个词语的输出就表示为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
我们现在来分析这个公式:首先明确Q和K都是 n × d k n\times d_k n×dk的矩阵,n表示句子的长度,那么softmax()最后产生的结果是一个 n × n n \times n n×n 的矩阵,我们这里姑且将其称为注意力矩阵,这里softmax是作用于 ( Q K T d k ) (\frac{QK^T}{\sqrt{d_k}}) (dkQK
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









