







1.理论
决策树的结构与数据结构的树差不多,树的根部输入所有样本,树的每个结点都是数据的特征,根据特征我们将样本分成一个个子集,使这一特征具有相同表现的样本汇聚,不同的分开,再对剩下的子集样本重复这些操作,直到不能分或没特征可判断为止。这个模型很好想象,它就像带着if-else的树一样。
决策树从最初提出的ID3模型,经历了很多次升级,例如C4.5,CART等。本文先介绍ID3与C4.5。
1.1信息熵、条件熵、信息增益
1.1.1信息熵
熵这个词我们最早应该是在中学的化学课本中听到的,用来描述分子无序、混乱的程度,熵是不断增加的。熵这一概念在各大学科领域都有应用,热力学,物理学,统计学等等。香农(C.E.Shannon)提出了信息论中的熵:信息熵。这个公式与期望有关,以下的分析更为简单直接,没有对公式由来作出解释,有兴趣的可以参考:通俗理解信息熵
公式:
pi表示信息中某一符号出现的频率,比如我们有本书,每个汉字出现的频率就是pi。信息熵可以用来描述语言/信息的混乱程度,但是我们知道信息的混乱程度有什么用呢?
百度百科中说:一般而言,当一种信息出现概率更高的时候,表明它被传播得更广泛,或者说,被引用的程度更高。我们可以认为,从信息传播的角度来看,信息熵可以表示信息的价值。这样子我们就有一个衡量信息价值高低的标准。
从公式的角度分析,若整个信息系统只有一个字、符号或者字母,那么p=1,信息熵为0,没有不确定性,它太确定了,无法传递什么信息,你抱着只有一个字的书能学到什么知识呢?那么我们加一个,这个信息系统里有1和0,p都是0.5,信息熵结果为1,这个信息系统可以传递信息了,就像现实中我们用1和0构建了计算机的逻辑。合理想象随着符号的增加,系统能传递的信息也在增加。另一个角度,假如1和0出现频率不同呢?若1是0.7,0是0.3,信息熵计算的结果是0.88。这说明如果符号出现的频率不相同,或者出现更大的差异,信息熵比频率相同的情况小,不确定减小,很好理解,如果一本书有99个1只有1个0那么我们也很难判断出什么信息。这就是信息熵,经过这段解释,相信对于这句话有了进一步的认识:信息熵表示信息的不确定性,进而可以用于表示信息的价值。
1.1.2条件熵
理解了信息熵,条件熵的概念便利于理解了,它表示在某条件下信息的不确定性。
它利用了条件概率来计算。(默认log以2为底)
回到我们真实的应用上,我们拥有一堆x与y,x拥有不同的特征,y拥有不同的种类,可以为这些建立一个信息系统模型。信息熵的概率当然是围绕y出现的概率来进行计算,来获得系统的不确定性,条件熵呢?则是在不同x的条件下,系统关于y信息的不确定性。
我之前看到这个公式的时候就发现为什么前面乘的概率是联合概率而不是条件概率呢?这是略微复杂的推导过程,参考自:通俗理解条件熵
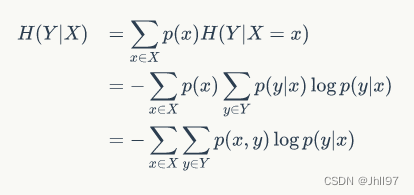
1.1.3信息增益
有了信息熵,(信息)条件熵,我们可以分析
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









