







1.理论简述
逻辑回归实际用于分类,回归这个名字的由来我记得是最先发明/使用的统计学家在首次提到它的书/文章中将该方法称为什么什么回归,于是后来也就沿用了这一叫法。百度了下这位统计学家是David Cox。
1.1二分类
逻辑回归适用于二分类和多分类。面对分类任务时,统计学思想是利用概率进行分类,如最基本的二分类中,被分到的那一类的概率会大于0.5 。可是如何将线性回归计算出的数值型结果转换为概率呢?我们使用Sigmoid函数:
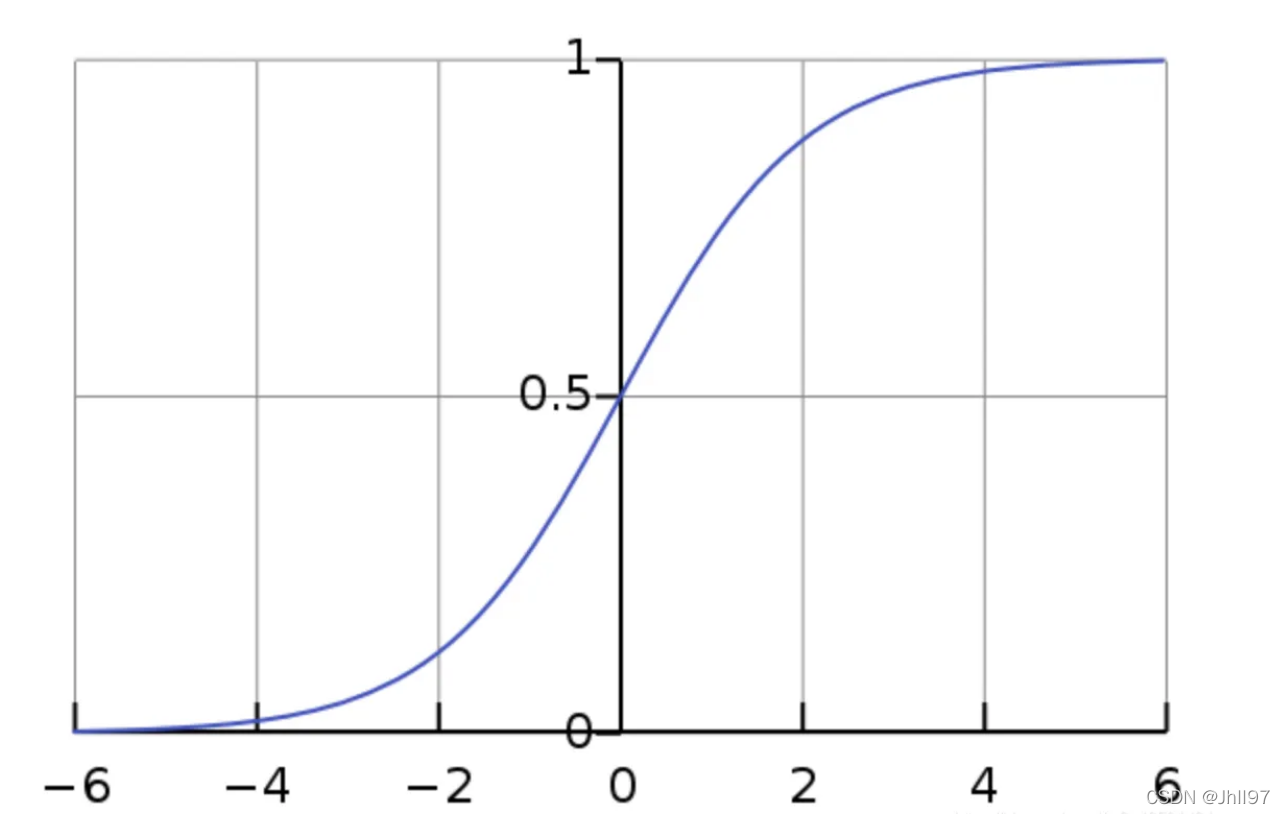
它可以将线性回归得到的分布在()中的结果压缩入[0,1]这个区间中。于是我们的分类模型就诞生了:
可以发现我们需要的参数仍然是w,只是它变化带来的影响是概率的改变。与线性回归不同的是,带入了概率问题之后,我们没办法再像以前一样通过平方或者绝对值就能算出预测值与真实值之间的差距,准确的说,线性回归的差距实际是距离,在概率上面不适用,我们需要转换分析的角度,更多地从统计学的角度来看待这个模型,才有利于理解它的分类原理。
首先我们将任何二分类问题都可以抽象化为目的是将结果分为1和0这两个标签。假设分类为1的概率是p,那么分类为0的概率就是1-p。假如我们获得了一个样本 i,其结果的概率可以表示为:
,利用一个公式表示就是
我们获得了很多个样本 i=1,2,3...由于每个样本并不依赖彼此(比如区分苹果和橙子,第 i 次拿的苹果并不会影响第 i+1 次拿到的是苹果还是橙子),所有样本的概率可以相乘,从而得到了总概率:
到这里我们才会看到w是如何发挥作用的,如果我们拥有很准确的w,我们每个样本得到的概率 p(1-p) 都应该是最大的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









