







线程与进程:
线程是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。而线程是进程中的一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
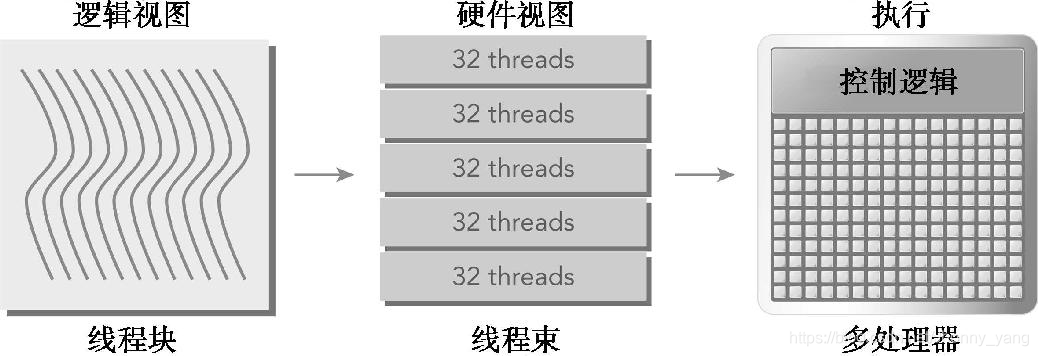
线程束和线程块:
一个线程束由32个连续的线程组成,在一个线程束中,所有的线程按照单指令多线程(SIMT)方式执行;即,所有线程都执行相同的指令,每个线程在私有数据上进行操作。
- 从逻辑角度来看,线程块是线程的集合,它们可以被组织为一维、二维或三维布局。
- 从硬件角度来看,线程块是一维线程束的集合。在线程块中线程被组织成一维布局,每32个连续线程组成一个线程束。
由于线程束分化,应该避免在同一线程束中有不同的执行路径,即确保同一个线程束中的所有线程在一个应用程序中使用同一个控制路径
极端地操纵线程块会限制资源的利用:
- 小线程块:每个块中线程太少,会在所有资源被充分利用之前导致硬件达到每个SM的线程束数量的限制。
- 大线程块:每个块中有太多的线程,会导致在每个SM中每个线程可用的硬件资源较少。
网格和线程块大小准则:
- 保持每个块中线程数量是线程束大小 ( 32 ) 的倍数
- 避免块太小:每个块至少要有128或256个线程
- 依据内核资源的需求调整块大小
- 块的数量要远远多于SM的数量,从而在设备中可以显示有足够的并行
- 通过调试实验得到最佳的执行配置和资源使用情况
CUDA内核启动时,线程块分布在多个SM中。网格中的线程块以并行或连续或任意的顺序被执行。这种独立性使得CUDA程序在任意数量的计算核心间可以扩展。
理解threadIdx, blockIdx, blockDim,gridDim:
#include <cuda_runtime.h>
#include <stdio.h>
#define CHECK(call) \
{ \
const cudaError_t error =call; \
if(error != cudaSuccess) \
{ \
printf("Error: %s:%d,", __FILE__, __LINE__); \
printf("code:%d, reason: %s \n",error,cudaGetErrorString(error)); \
exit(1); \
} \
}
__global__ void checkIndex(void)
{
printf("threadIdx:(%d, %d, %d) "
"blockIdx:(%d, %d, %d) "
"blockDim:(%d, %d, %d) "
"gridDim:(%d, %d, %d)\n",
threadIdx.x,threadIdx.y,threadIdx.z,
blockIdx.x,blockIdx.y,blockIdx.z,
blockDim.x,blockDim.y,blockDim.z,
gridDim.x,gridDim.y,gridDim.z);
int idx = blockIdx.x*blockDim.x+threadIdx.x;
printf("blockIdx =%d blockDim.x =%d threadIdx.x =%d idx =%d \n",
blockIdx.x,blockDim.x,threadIdx.x,idx);
}
int main(int argc, char **argv)
{
int nElem =6;
dim3 block(3);
dim3 grid((nElem+block.x-1)/block.x);
printf("grid.x=%d, grid.y=%d, grid.z=%d \n",grid.x,grid.y,grid.z);
printf("block.x=%d, block.y=%d, block.z=%d \n",block.x,block.y,block.z);
checkIndex<<<grid,block>>>();
//cudaDeviceReset();
CHECK(cudaDeviceSynchronize());
return 0;
}

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









