







前面已经多次提到线程束(wrap),即一个线程块中的连续32个线程。本章将对它及相关的CUDA语法和编程模型进行更为深入、系统的介绍。
10.1 单指令-多线程执行模式
从硬件上来看,一个GPU被分成若干个流多处理器(SM),同一个架构中的不同型号的GPU可以有不同数目的SM。核函数中定义的线程块在执行时将被分配到还没有完全占满地SM中,一个SM可以有一个或多个线程块。不同线程块之间可以并发或顺序的执行,一般来说,不能同步(即使利用后面要介绍的协作组也只能在一些特殊的情况下进行线程块之间的同步)。当某些线程块完成计算任务之后,对应的SM部分或完全空闲,然后会有新的线程块被分配到空闲的SM。
从更细的粒度看,一个SM以32个线程为单位产生、管理、调度、执行线程,这样32个线程称为一个线程束。一个SM可以处理一个或多个线程块。一个线程块又可分为若干线程束。例如,一个128线程的线程块将被分为4个线程束,其中每个线程束包含32个具有连续线程号的线程,这样划分对于所有GPU架构都是成立的。
在伏特架构之前,一个线程束中的线程拥有同一个程序计数器,但各自有不同的寄存器状态,从而可以根据程序的逻辑判断选择不同的分支,但在执行时,各个分支是依次顺序执行的。在同一时刻,一个线程束中的线程只能执行一个共同的指令或者闲置,这被称为单指令-多线程(SIMT)的执行模式。
当一个线程束中的线程顺序地执行判断语句中的不同分支时,称之为发生了分支发散(branch diverfence),例如核函数中有如下判断语句:if(condition){A;}else { B;}
首先,满足condition的线程会执行语句A,其他的线程将闲置。然后不满足condition的线程会执行语句B,其他的线程将闲置,这样当语句A和语句B的指令数差不多时,整个线程束的执行效率就比没有分支的情形低一半。值得强调的是,分支发散针对的是同一个线程束内部的线程的。如果不同的线程束执行条件语句的不同分支,不属于分支发散。我们考察核函数中的如下代码段(假如线程块大小是128):
int warp_id=threadIdx.x/32;
switch(warp_id)
{
case 0:S0;break;
case 1:S1;break;
case 2:S2;break;
case 3:S3;break;
}其中warp_id在不同的线程束中取不同的值,但是在同一个线程束中取相同的值,所以没有分支发散,若将上述代码改写成以下形式:
int warp_id=threadIdx.x%32;
switch(warp_id)
{
case 0:S0;break;
case 1:S1;break;
case 2:S2;break;
case 3:S3;break;
}则将导致严重的分支发散,因为变量warp_id在同一个线程束内部可以取32个不同的取值。
一般来说,在编写核函数的时候要尽量避免分支发散。但是在很多情况下,根据算法的需求,是无法完全避免分支发散的,例如在数组相加的程序等都会用到如下判断语句:if(n<N){do sth}.该判断语句最多在最后一个线程块中发生分支发散,所以一般来讲不会显著的影响程序的性能。但如果漏掉了该语句的判断,将会导致内存错误,正如在前一章neighbor2.gpu程序中所做的那样。另外,如果一个判断语句的两个分支中有一个分支不包含指令,那么即使发生了分支发散,也不会显著的影响性能,总之把正确性放在第一位。
从伏特架构开始,引入了独立线程调度(independent threat sheduling)机制,每个线程有自己的程序计数器。这使得伏特架构有了以前一些架构所没有的新的线程束内同步与通信的模式,从而提高了编程的灵活性,降低了移植已有代码的难度。要实现独立线程调度机制,一个代价是增加了寄存器负担:单个线程的程序计数器一般需要使用两个寄存器。也就是说伏特架构的独立线程调度机制使得SM中的每个线程可利用的寄存器少了两个。另外,独立线程机制使得假设了线程束同步的代码变得不再安全。例如,在数组规约的例子中,当线程号小于32时,省去线程块同步函数__synthreads()在伏特架构之前是允许的做法,但从伏特架构开始就不再是安全的做法了,下一节,介绍一个比线程块同步函数__syncthreads()粒度更细的线程束内同步函数__syncwarp()。如果要在伏特架构或更高架构的GPU中运行一个使用了线程束同步假设的程序,则可以在编译时将虚拟架构指定为低于伏特架构的计算能力,例如可选以下选项:
-arch=compute_60 -code=sm_70,将在生成的PTX代码中使用帕斯卡架构的线程调度机制,而忽略伏特架构的线程调度机制。
10.2 线程束内的线程同步函数
在规约问题当中,当所涉及的线程都在一个线程束内,可以将线程块同步函数__syncthreads()换成一个更加廉价的线程束同步函数__syncwarp()。将其简称为束内同步函数。该函数的原型是:void __syncwarp(unsigned mask=0xffffffff);该函数有一个可选的参数。该参数是一个代表掩码的无符号整形数,默认值全部32个二进制位都为1,代表线程束中的所有线程都参与同步。如果要排除一些线程,可以用一个对应的二进制位为0的掩码参数。例如,掩码0xffffffff代表排除第0号线程。用该束内同步函数,可以将第9章的规约核函数改词而成如下核函数:
void __syncwarp(unsigned mask=0xffffffff);该函数有一个可选的参数,该参数是一个代表掩码的无符号整数型,默认值的全部32个二进制位都为1,代表线程束中的所有线程都参与同步。如果要排除一些线程,可以用一个对应的二进制位为0的掩码参数,例如
void __global__ reduce_syncwarp(const real *d_x,real *d_y,const int N)
{
const int tid=threadIdx.x;
const int bid=blockIdx.x;
const int n=bid*blockDim.x+tid;
extern __shared__ real s_y[];
s_y[tid]=(n<N?d_x[n]:0);
__syncthreads();
for(int offset=blockDim.x>1;offset>=32;offset>>=1)
{
if(tid<offset)
{
s_y[tid]+=s_y[tid+offset];
}
__syncthreads();
}
for(int offset=16;offset>0;offset>=1)
{
if(tid<offset)
{
s_y[tid]+=s_y[tid+offset];
}
__syncwarp();
}
if(tid==0)
{
atomicAdd(d_y,s_y[0]);
}
}也就是说,当offset>=32时每一次进行折半求和后使用线程块同步函数__syncthreads();当offset<=16时,我们每一次折半求和后使用束内同步函数__syncwarp().此外在使用__syncwarp()和共享内存时,容易犯一个错误,为了展示这一点尝试将上述核函数第19-26行改写如下:
for(int offset=16;offset>0;offset>>=1)
{
s_y[tid]+=s_y[tid+offset];
__syncwarp();;
}
这种写法是错误的,以offset=16为例进行分析。考虑tid=0和tid=16的两个线程,他们分别涉及以下并行的计算:
s_y[0]+=s_y[16];s_y[16]+=s_y[32];
也就是说,我们试图将s_y[16]累加到s_y[0],而同时又想把s_y[32]累加到s_y[16]。或者说,既要向s_y[16]写数据又要读数据,这将导致所谓的读-写竞争。在核函数reduce_syncwarp.cu中,上述两条语句中的第二个循环内的判断if(tid<offset)排除了,顾不会出现读-写竞争。如果想要在循环内去掉对线程号的约束,又要避免出现读-写竞争,可以将相关代码改写如下:
real v=s_y[tid];
for(int offset=16;offset>0;offset>=1)
{
v+=s_y[tid+offset];
__syncwarp();
s_y[tid]=v;
__syncwarp();
}这样修改之后可以保证语句v+=s_y[tid+offset]总是在语句s_y[tid]=v;之前执行。当offset=16时,能够保证先从s_y[16]读数据。
10.3 更多线程束内的基本函数
10.3.1 介绍
在最近的几个CUDA版本中引入或更新了不少线程束内的基本函数,包括线程束表决(warp vote functions)函数、线程束匹配函数(warp match functions)、线程束洗牌函数(warp shuffle functions)及线程束矩阵函数(warp matrix functions)。其中,线程束匹配函数和线程束矩阵函数都只能在伏特或跟高的架构中使用。我们这里仅介绍线程束表决函数和线程束洗牌函数。这两类函数都是从开普勒架构中就开始用的,但在CUDA9中进行了更新。更新之后的线程束表决函数的原型如下:
unsigned __ballot_sync(unsigned mask,int predicate);
int __all_sync(unsigned mask,int predicate);
int any_sync(unsigned mask,int predicate);
更新之后四个线程束洗牌函数的原型如下:
T __shfl_sync(unsigned mask,T v,int srcLane,int w=warpSize);
T __shfl_up_sync(unsignd mask,T v,unsigned d,int w=warpSize);
T __shfl_down_sync(unsigned mask,T v,unsigned d,int w=warpSize);
T __shfl_xor_sync(unsigned mask,T v,int laneMask,int w=warpSize);
其中,类型T可以是整形(int)、长整形(long)、长长整形(long long)、无符号整形(unsigned)、无符号长整形(unsignd long)等。每个线程束洗牌函数的最后一个参数w都是可选的,有默认值warpSize,在当前所有架构的GPU中都是32.参数w只能取2、4、8、16、32这五个整数中的一个。当w小于32时,就相当于逻辑上的线程束大小是w,而不是32,其他规则不变,对于一般的情况,可以定义一个“束内指标”(假设使用一维线程块):
int lane_id=threadIdx.x%w;
赋值号右边的取模计算可以用更高效的按位与(bit-wise and)表示:
int lane_id=threadIdx.x&(w-1);
但是当w是常量时,编译器会自动优化该计算。假如线程块大小为16,w为8则一个线程块中各个线程的线程指标和束内指标有如下关系:
线程指标:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
束内指标:0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
对于其他任何情况(任何线程块大小和任何w值)在使用线程束内的函数时都需要特别注意线程指标和束内指标的对应关系。
以上函数中的mask称为掩码,是一个无符号整数,具有32位,这个二进制位从右边数起刚好对应线程束内32个线程,该整数的32个二进制位要么是0要么是1,例如常量掩码:
const unsigned FULL_MASK=0xffffffff
掩码用于指定将要参与计算的线程:当掩码中的一个二进制位为1时,代表对应的线程参与计算;当掩码中的一个二进制位为0时,代表忽略对应的线程。特别的,各种函数返回的结果对被掩码派出的线程来说是没有意义的,所以不要尝试在那些被排除的线程中使用函数的返回值。
这些函数的功能如下。
(1) __ballot_sync(mask,predicate)该函数返回一个无符号整形,如果线程束内地n个线程参与计算且predicate值非零,则将所返回的无符号整数的第n个二进制位为1,否则取0,该功能的特点相当于从一个掩码触发产生一个新的掩码。
(2)__all_sync(mask,predicate)线程束内所有参与线程的predicate值都不为零时才返回1,否则返回0.这里参与的线程对应于mask中取1的比特位。该函数实现了一个规约-广播式计算。该函数类似于这样一种选举操作,即当所有参选人都同意时才通过。
(3)__any_sync(mask,predicate):线程束内所有参与线程的predicate值都不为零时就返回1,不然就返回0.该函数也实现了一个规约-广播式计算,该函数类似于这样一种选举操作,即当有一个参选人同样就通过。
(4)__shfl_sync(mask,v,srclane,w)参与线程返回标号为srclane的线程中变量v的值。这是一种广播式数据交换,即将一个线程中的数据广播到所有包括自己的线程中。
(5)__shfl_up_sync(mask,v,d,w)标号为t的参与线程返回标号为t-d的线程中变量v的值。标号满足t-d<0的线程返回原来的v,例如当w=8时,d=2时,该函数将第0-5号线程中变量v传送给第2-7号线程,而第0-1号线程返回原来的v,形象的说就是一种将数据向上平移的操作。
(6)__shfl_down_sync(mask,v,d,w):标号为t的参与线程返回标号为t+d中线程中变量v的值。标号满足t+d>=w的线程返回原来的v。例如,当w=8,d=2时,该函数将2-7号线程中的变量v的值传送给0-5号线程,而6-7号线程返回他们原来的v,形象的说就是一种梦数据向下平移的操作。
(7)shfl_xor_sync(mask,v,lanemask,w):标号为t的参与线程返回标号为t^lanemark线程中变量v的值。这里t^lanemark表示两个整数按位异或运算的结果。例如当w=8时,lanemark=2时,第0-7号线程的按位异或运算t^lanemask分别如下:
0^2=0000^0010=0010=2
1^2=0001^0010=0011=3
2^2=0010^0010=0000=0
3^2=0011^0010=0001=1
4^2=0100^0010=0110=6
5^2=0101^0010=0111=7
6^2=0110^0010=0100=4
7^2=0111^0010=0101=5
该线程让线程束内的线程两两交换数据。
为了更进一步的了解这些函数,代码如下:
#include"error.cuh"
#inlcude<stdio.h>
const unsigned WIDTH=8;
const unsigned BLOCK_SIZE=16;
const unsigned FULL_MASK=0xffffff;
void __global__test_warp_primitives();
int main(int argc,char**argc)
{
test_warp_primitives<<<1,BLOCK_SIZE>>>();
CHECK(cudaDeviceSynchronize());
return 0;
}
void __global__ test_warp_primitives()
{
int tid=threadIdx.x;
int lane_id=tid%WIDTH;
if(tid==0) printf("threadIdx.x:");
printf("%2d",tid);
if(tid==0) printf("\n");
if(tid==0) printf("lane_id:");
printf("%2d",lane_id);
if(tid==0)printf("\n");
unsigned mask1=__ballot_sync(FULL_MASK,tid>0);
unsigned mask2=__ballot_sync(FULL_MASK,tid==0);
if(tid==0) printf("FULL_MASK=%x\n",FULL_MASK);
if(tid==1) printf("mask1=%x\n",mask1);
if(tid==0) printf("mask2=%x\n",mask2);
int result=_all_sync(FULL_MASK,tid);
if(tid==0) printf("all_sync(FULL_MASK)%d\n",result);
result=__any_sync(FULL_MASK,tid);
if(tid==0)printf("any_sync (FULL_MASK):%d\n",reault);
result=__anysync(mask2,tid);
if(tid==0)printf("any_sync (mask2):%d\n",result);
int value=__shfl_sync(FULL_MASK,tid,2,WIDTH);
if(tid==0)printf("shfl:");
printf("%2d",value);
if(tid==0)printf("\n");
int value=__shfl_up_sync(FULL_MASK,tid,2,WIDTH);
if(tid==0)printf("shfl_up:");
printf("%2d",value);
if(tid==0)printf("\n");
int value=__shfl_down_sync(FULL_MASK,tid,2,WIDTH);
if(tid==0)printf("shfl_down:");
printf("%2d",value);
if(tid==0)printf("\n");
int value=__shfl_xor_sync(FULL_MASK,tid,2,WIDTH);
if(tid==0)printf("shfl_xor:");
printf("%2d",value);
if(tid==0)printf("\n");
}运行结果如下: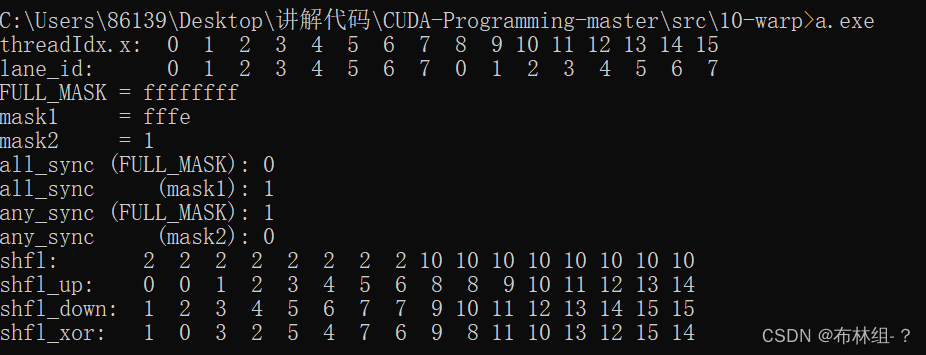
下面详细分析程序中的代码和对应的输出:
(1)为了让输出的内容简单,我们选取了一个宽度为8(逻辑上的)线程束和一个大小为16的线程块,如代码中4-5行所示。
(2)第20行定义了束内线程号lane_id。
(3)第23行向屏幕输出线程号tid,对应程序输出的第1行。
(4)第27行向屏幕输出线程束内线程号lane_id,对应程序输出的第二行:前8个数分别是0-7,可以说将16线程的线程块分成了两部分,每部分在逻辑上表现为一个迷你版的线程束。
(5)第30-21行调用__ballot_sync()函数从FULL_MASK出发计算mask1和mask2,分别对应排除0号线程和仅保留0号线程的掩码。
(6)第32-34行输出3个掩码的16进制表示(对应程序输出的3-5行)。
(7)第36行调用__all_sync()函数,掩码为FULL_MASK。因为不是所有线程的predicate值都非零,所以该函数的返回值为0;
(8)第39行继续调用__all_sync()函数,掩码为mask1,排除了第0号线程。因为每个参与线程的predicate值都非0,所以该函数的返回值为1;
(9)第45行继续调用__any_sync()函数,掩码为FULL_MASK,所以该函数的返回值为1。
(10)第42行调用__any_sync()函数,掩码为mask2,只保留了第0号线程。因为该线程的predicate值为零,随意该函数的返回值为0.
(11)第48行调用_shfl_sync()函数,将第2号线程的值广播到第0-7号线程中去。将第10号线程的值广播到第8-15号线程中去。也就是说,线程束洗牌函数是独立地作用在各个迷你版的线程束中。
(12)第53行调用__shfl_up_sync()函数,将第0-6号线程中的数据平移到第1-7号线程中去,第8-14号线程平移到9-15号线程,第0号和第八号线程返回原来的输入值。
(13)第58行调用__shfl_down_sync()函数,将1-7行线程中的数据平移到第0-6号线程号中去,9-15平移到8-14中去,第7和15返回原来的输出值。
(14)第63行调用__shfl_xor_sync()函数。其中,第三个参数1的二进制表示为0001.它与线程号0-7做按位或运算,作用是将相邻的两个线程号交换。
最后需要注意的是虽然这里涉及规约计算,但并不需要在任何地方明显地使用同步函数如__syncwarp(),这是因为所有的线程束内的基本函数(都以__sync()结尾)都具有隐式的同步功能。
10.3.2 利用线程束洗牌函数进行规约计算
我么可以利用线程束洗牌函数进行规约计算,回顾我们介绍的几个线程束洗牌函数,其中函数__shfl_down_sync()的作用是将高线程号的数据平移到低线程号中,这正是规约问题中需要的操作,以下给出了规约问题中需要的操作:
void __global__ reduce_shfl(const real*d_x,real *d_y,const int N)
{
const int tid=threadIdx.x;
const int bid=blockIdx.x;
const int n=bid*blockDim.x+tid;
extern __shared__ real s_y[];
s_y[tid]=(n<N)?d_x[n]:0.0;
__syncthreads();
for(int offset=blockDim.x>>1;offset>=32;offset>>=1)
{
if(tid<offset)
{
s_y[tid]+=s_y[tid+offset];
}
__syncthreads();
}
real y=s_y[tid];
for(int offset=16;offset>0;offset>>=1)
{
y+=__shfl_down_sync(FULL_MASK,y,offset);
}
if(tid==0)
{
atomicAdd(d_y,y);
}
}相比之前的版本,我们可以发现两处不同。第一,在进行线程束内的循环之前,这里将共享内存中的数据复制到了寄存器。在线程束内使用洗牌函数进行规约时,不再需要明显的使用共享内存。因为寄存器一般来说比共享内存更加高效,所以能用寄存器当然用寄存器。第二用语句
y+=__shfl_down_sync(FULL_MASK,y,offset);替换掉语句块
if(tid<offset) {s_y[tid]+=s_y[tid+offset];} __syncwarp();也就是说去掉了同步函数,也去掉了对于线程号的限制,因为洗牌函数能自动处理同步与读-写竞争问题。对全部参与的来说,上述洗牌函数总是先读取各个线程中y的值,再将洗牌操作的结果写入各个线程中的y,此外将__shfl_down_sync()换成__shfl_xor_sync(),结果一致。
10.4 协作组
通过本章前面的学习,知道,在某些并行算法中,需要若干线程间的合作,要合作必须要有同步机制。协作组(cooperative group)可以看做线程块和线程束同步机制的推广,它提供了更为灵活的线程协作方式,包括线程块内部的同步与协作、线程块之间的(网格级的)同步与协作。本节仅讲解线程块级的协作组,协作组在CUDA9才被引入,但对于线程块级的协作组功能可以用于开普勒以上架构,而其他级别的协作组功能需要帕斯卡及以上的架构才能使用。
使用协作组功能需要在相关源文件包含以下头文件:
#include <cooperative_groups.h>
除此之外,还要注意所有与协作组相关的数据类型和函数定义在命名空间cooperative_groups下。可以给该命名空间命名一个短小的名字 namspace cg=cooperative_groups;
10.4.1 线程块级别的协作组
协作组编程模型中最基本的类型是线程组thread_group.该类型有如下成员:
(1)void sync():该函数能同步组内所有线程。
(2)unsigned size():该函数返回组内总的线程数目,即组的大小。
(3)unsigned thread_rank():该函数返回当前调用该函数的线程在组内的标号(从0开始计数)。
(4)bool is_valid():该函数返回一个逻辑值,如果定义的组违反了任何CUDA的限制,则为假。
线程组类型有一个称为线程块thread_block的导出类型,在该类型中提供了两个额外的函数:
(1)dim3 group_index():该函数返回当前调用该函数的线程的线程块指标,等价于blockDim.x
(2)dim3 thread_index():该函数返回当前调用该函数的线程指标,等价于threadIdx.x.
可以用如下方式定义并初始化一个thread_block对象:
thread_block g=this_thread_block():
其中,this_thread_block()相当于一个线程块类型的常量。这样定义的g就代表就代表我们已经非常熟悉的线程块,只不过把他包装成了一个类型。例如g.sync()完全等价于__syncthreads(),g.group_index()完全等价于CUDA中的内建变量blockIdx,g.thread_index()完全等价于CUDA中的内建变量threadIdx.
可以用函数tiled_partition()将一个线程块划分成若干片(tile),每一个构成一个新的线程组。目前。仅仅可以将片的大小设置为2的正整数次方且不大于32.例如如下语句通过函数tiled_partition()将一个线程块划分为若干束:
thread_group g32=tiled_partition(this_thread_block(),32);
还可以将该线程组分割为更细的线程组。如下语句将每个线程束再分割为包含4个线程的线程组:
thread_group g4=tiled_partition(g32,4);
当这种线程组的大小在编译期间就已知时,可以用如下模板化的版本,可以更加高效的定义:
thread_block_tile<32> g32=tiled_partition<32>(this_thread_block());
thread_block_time<4> g4=tiled_partition<4>(this_thread_block());
这样定义的线程组一般称为线程块片,线程块片还额外的定义了如下函数(类似于线程束内的基本函数):
unsigned __ballot_sync(int predicate);
int __all_sync(int predicate);
int __any_sync(int predicate);
T __shfl_sync(T v,int srcLane);
T __shfl_up_sync(T v,unsugned d);
T __shfl_down_sync(T v,unsigned d);
T __shfl_xor_sync(T v,int laneMask);
10.4.2 利用协作组进行规约计算
既然线程块片类型中也有洗牌函数,显然也可以利用线程块片来进行数组归的计算。只需要对迁移版本的规约核函数稍作修改;如下:
void __global__ reduce_cp(const real * d_x,real * d_y,const int N)
{
const int tid=threadIdx.x;
const int bid=blockIdx.x;
const int n=bid*blockDim.x+tid;
extern __shared__ real s_y[];
s_y[tid]=(n<N)?d_x[n]:0.0;
__syncthreads();
for(int offset=blockDim.x>>1;offset>=32;offset>>=1)
{
if(tid<offset)
{
s_y[tid]+=s_y[tid+offset];
}
__syncthreads();
}
real y=s_y[tid];
thread_block_tile<32>g=tiled_partition<32>(this_thread_block());
for(int i=g.size()>>1;i>0;i>>=1)
{
y+=g.shfl_down(y.i);
}
if(tid==0)
{
atomicAdd(d_y,y);
}
}在第21行,定义了一个线程块片类型的变量g,将整个线程块分割成了若干个线程束。注意:这里必须采用带有模板参数的线程块片类型,因为普通的线程组是没有洗牌函数的。在以下的循环条件中使用成员g.size()来表示线程块片的大小。在循环体中使用了函数g.shfl_down()来进行规约,这里将该函数换成g_shfl_xor()也能得到一样的效果。
10.5 数组规约程序的进一步优化
10.5.1 提高线程利用率
我们注意到,在前一章节的数组规约核函数中,线程的利用率并不高。因为我们使用大小为128的线程块,所以当offset等于64时,只用了1/2的线程进行了计算,其余线程重置。当offset等于32时,只用了1/4的线程进行了计算,其余线程闲置。最终offset等于1的时候,只用了1/128的线程进行计算,其余线程闲置。规约过程一共用了log2128=7步,规约过程中线程的平均利用率只有(1/2+1/4+......)/7=1/7.
相比之下,在规约之前,将全局内存中的数据复制到共享内存的操作对线程的利用率时100%的,据此得到一个想法:如果能够提高规约之前所做计算的比例,则应该可以从整体上提升对线程的利用率。再上一个版本,共享内存数组中的每一个元素(注意:不同线程块有不同的共享内存变量副本)仅仅保存了一个全局内存数组的数据。为了提高规约之前所做计算的比例,可以在规约之前将多个全局内存数组的数据累加到一个共享内存数组的一个元素中。
为了做到这一点,可以让每个线程处理相邻的若干个数据,因为这必然导致全局内存的非合并访问,要保证全局内存的合并访问,在我们的问题中必须让相邻的线程访问相邻的数据,而同一个线程所访问的数据之间必然具有某种跨度。该跨度可以是一个线程块的线程数,也可以是整个网格的线程数,对于一维的情形,分别是blockDim.x和blockDim.x*gridDim.x,在这里介绍跨度为整个网格的做法:
void __global__ reduce_cp(const real *d_x,real *d_y,const int N)
{
const int tid=threadIdx.x;
const int bid=BlockIdx.x;
extern __shared__ real s_y[];
real y=0.0;
const int stride=blockDim.x*gridDim.x;
for(int n=bid*blockDim.x+tid;n<N;n+=stride)
{
y+=d_x[n];
}
s_y[tid]=y;
__syncthreads();
for(int offset=blockDim.x>>1;offset>=32;offset>>=1)
{
if(tid<offset)
{
s_y[tid]+=s_y[tid+offset];
}
__syncthreads();
}
y=s_y[tid];
thread_block_tile<32>g=tiled_partition<32>(this_thread_block());
for(int i=g.size()>>1;i>0;i>>=1)
{
y+=g.shfl_down(y,i);
}
if(tid==0)
{
d_y[bid]=y;
}
}函数中第八行低音的常数stride就是我们上面说的“跨度”。第9行的循环条件语句体现了该跨度。第7行定义了一个寄存器变量y,用来在循环体中对读取的全局内存数据进行累加,见第11行。也可以在共享内存中进行累加,但使用寄存器更为高效。当然,在规约之前,必须将寄存器的数据复制到共享内存,见13行。
细心地读者发现,将原来程序中的atomicAdd(d_y,y)改成了现在的d_y[bid]=y(第35行)。回顾一下,之前使用原子函数的目的是在规约结束后,将每个线程块中的部分和累加起来得到最终的和,避免将这些部分和数据从设备复制到主机。本章的规约核函数非常灵活,可以在不使用原子函数的情况下通过对其调用两次方方便得到最终的结果。当然,这里依然可以使用原子函数,但后面可以看到用两个核函数可获得更为精确地结果。
以下代码给出了一个调用核函数的包装函数,它返回最终的计算结果。这,我们将grid_size取为10240,将block_size取为128.在第10行,调用核函数将长一些的数组d_x规约到短一点的数组d_y时,我们使用执行配置<<<grid_size,block_size>>>。当数据量为N=1e8时,在规约前每个线程先累加几十个数据(核函数的11行)。如果将gird_size取为N/128,那就和前面的章节一致,在第11行,再次调用同一个核函数将数组d_y规约到最终的结果,虽然是用一个线程块,但是线程块大小是1024:
real reduce(const real * d_x)
{
const int ymem=sizeof(real)*grid_size;
const int smem=sizeof(real)*block_size;
real h_y[1]={0};
real *d_y;
CHECK(cudaMalloc(&d_y,ymem));
reduce_cp<<<grid_size,block_size,smem>>>(d_x,d_y,N);
reduce_cp<<<1,1024,sizeof(real)*1024>>>(d_y,d_y,grid_size);
CHECK(cudaMemcpy(h_y,d_y,sizoef(real),cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_y));
return h+y[0];
}
10.5.2 避免反复分配和释放设备内存
在上面的包装函数reduce()中,我们需要为数组d_y分配和释放设备内存,实际上,设备内存的分配和释放是比较耗时的,一种优化方案是使用静态全局内存代替这里的动态全局内存,因为静态内存是编译期间就分配好的,不会在运动程序时反复的分配,所以比动态内存分配高效的多,回顾第六章的内容,我们知道,可以用以下语句在函数外部定义我们需要的静态全局内存变量:
__device__ real static_y[grid_size];
我么可以直接在核函数中使用该变量,但这需要改变核函数代码,如果不想改变核函数代码,可以利用运行时API函数cudaGetSymbolAddress()将该指针与静态全局变量static_y联系起来。该函数的原型是:
real reduce(const real* d_x)
{
real * d_y;
CHECK(cudaGetSymbolAddress((void**)&d_y,static_y));
const int smem=sizeof(real)*block_size;
reduce_cp<<<grid_size,block_size,smem>>>(d_x,d_y,N);
reduce_cp<<<1,1024,sizeof(real)*1024>>>(d_y,d_y,grid_size);
real h_y[1]={0};
CHECK(cudaMemcpy(h_y,d_y,sizoef(real),cudaMemcpyDeviceToHost));
return h_y[0];
}cudaError_t cudaGetSymbolAddress(void**debptr,const void *symbol);这里的symbol参数可以使静态全局内存(用__device__定义)或者常量内存(用__constant__定义)的变量名,通过cudaGetSymbolAddress()获得的设备指针可以像其他设备指针一样使用。除可以将该指针传入核函数外,还可以利用它完成主机与设备之间的数据传输。

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









