







目录
引言
强化学习作为人工智能中最令人兴奋的分支之一,正在各个领域掀起革命浪潮。从AlphaGo击败世界围棋冠军到自动驾驶技术的飞速发展,强化学习都发挥着核心作用。本文将带你从零开始,系统性地理解强化学习的核心概念、解决方案和实现技巧,帮助你掌握这一引领未来的技术。
无论你是AI初学者、经验丰富的开发者,还是准备面试的求职者,这篇指南都能满足你的需求。让我们开始这段探索之旅吧!
1. 强化学习基础结构
1.1 核心元素
强化学习的基本框架由以下元素组成:
- 智能体(Agent): 决策的主体,学习如何行动以最大化回报
- 环境(Environment): 智能体所处的外部系统
- 状态(State): 环境在某时刻的描述
- 动作(Action): 智能体可选的行为集合
- 奖励(Reward): 环境对智能体行为的反馈信号
- 策略(Policy): 智能体从状态到动作的映射
- 价值函数(Value Function): 评估状态或状态-动作对的价值
- 模型(Model): 对环境转移概率和奖励函数的估计(可选)
这些元素通过交互流程串联: 智能体观察当前状态,执行动作,环境反馈奖励并转移到新状态,循环往复。

1.2 为什么强化学习比监督学习更难?
强化学习面临着独特的挑战:
- 反馈稀疏且延迟: 不像监督学习每个样本都有明确标签,强化学习中往往只有延迟的、稀疏的回报信号
- 非独立同分布(non-IID): 状态-动作序列高度相关,破坏了传统机器学习的基本假设
- 探索-利用权衡: 需要平衡尝试新动作(探索)与执行已知最优动作(利用)
- 目标函数非平稳: 策略的改变会影响数据分布,导致训练不稳定
1.3 强化学习的直观理解
想象你在训练一只狗:
- 狗不断尝试各种行为(坐下、握手、跑回你身边)
- 当它做对时,你给予奖励(食物、表扬)
- 随着时间推移,狗学会在特定指令下做出正确反应
强化学习本质上就是这个过程的数学形式化和算法实现。
2. 马尔可夫决策过程(MDP)详解
2.1 MDP基础
马尔可夫决策过程是强化学习的数学基础,用五个要素表示:
- S: 状态空间 - 智能体可能处于的所有情况
- A: 动作空间 - 智能体可以采取的所有行动
- P: 状态转移概率 - 执行某动作后环境如何变化
- R: 奖励函数 - 执行动作获得的即时反馈
- γ: 折扣因子 - 决定未来奖励的重要性(0到1之间)
2.2 为什么需要折扣因子?
折扣因子的引入有三个关键原因:
- 保证总回报有限: 避免无限时间范围内奖励无限累加
- 体现时间偏好: 越小的γ越注重近期回报;越接近1则更重视长期结果
- 改善学习稳定性: 减弱远期奖励带来的不确定性,让学习更稳定
2.3 马尔可夫性质
MDP最重要的特性是马尔可夫性质:未来状态只依赖于当前状态和动作,与历史路径无关。简单说就是"未来只取决于现在,不取决于过去"。
2.4 贝尔曼方程
贝尔曼方程是强化学习的核心等式,描述了值函数的递归关系:
- 状态值函数:某状态的价值等于在此状态下,按当前策略选择动作,获得的即时奖励加上下一状态价值的折扣和的期望
- 动作值函数:某状态-动作对的价值等于执行该动作获得的即时奖励加上下一状态价值的折扣和的期望
3. 动态规划求解MDP
当环境模型已知时,可以使用动态规划方法找到最优策略。
3.1 策略迭代(Policy Iteration)
策略迭代包含两个交替的步骤:
策略评估
重复以下步骤直到值函数收敛:
对所有状态计算: 当前策略下该状态的价值策略改进:
对所有状态:
更新策略,使它选择能获得最大期望回报的动作重复这两个步骤直到策略不再变化。
3.2 价值迭代(Value Iteration)
价值迭代将评估和改进合并为一步:
重复以下步骤直到值函数收敛:
对所有状态:
更新该状态的价值为所有可能动作中能获得最大期望回报的值3.3 收敛判断
算法收敛的条件通常有两个:
- 价值函数变化微小: 两次迭代间的最大值变化小于阈值
- 策略不再变化: 一次迭代后策略保持不变
3.4 策略迭代vs价值迭代
两者的主要区别:
| 策略迭代 | 价值迭代 |
|---|---|
| 显式分为策略评估和改进 | 评估和改进合并为一步 |
| 每次评估都迭代多次直到收敛 | 每次只做一次最优更新 |
| 改进次数少但每轮开销大 | 迭代轮数多但每轮简单 |
基于价值(Value-based)
想象你在游乐园里,一张地图上标出了各个景点的“好玩程度”分数。你要去玩,就每次都看哪个地方分数最高,就往那个方向走。
“价值”就是地图上的分数:你不停地更新分数(好玩程度),越来越准确。
“取最大值”:每次都走分数最高的路。
价值分数=未来总收益之和的估计:地图上每个景点的“好玩程度”分数,并不是该景点当下瞬间的奖励(比如一个过山车的刺激度),而是从这里出发、一路玩下去,直到结束时能获得的累计好玩分(折扣以后或不折扣)。这意味着,哪怕某个景点当下分数一般,但它旁边有一票非常好玩的项目连环搭配,它的“总体分”依然可能很高。
收敛:当分数不再大幅变化时,地图就“收敛”了,你能一直找到最好玩的路线。
基于策略(Policy-based)
你想学做一道菜,不是先给你食谱的分数表,而是教授让你自己动手试各种调料配比,每试一次就给你打个分,让你根据分数往更好吃的方向调。
“策略”就是你的调料配方:你手上有一套按比例混合盐、糖、辣椒的配方。
“试不同做法”:每次根据当前配方做一道菜,尝一尝,根据反馈(分数)调整比例;
收敛:多试几次,你的配方会不断优化,最后调出最合口味的版本。
4. 无模型学习:蒙特卡洛与时序差分
当环境模型未知时,我们需要基于经验样本来学习。
4.1 蒙特卡洛方法(MC)
比喻场景:你手里只有一张"景点列表",但并不知道每条通道的概率和奖励。想知道哪条线路好玩,就必须"亲自"跑一趟,坐缆车、坐过山车,直到跑到终点。跑完一次回到起点,你才知道这趟到底赚了多少乐趣分。
直观理解:
- 不需要模型,只能"实际去跑一次",等一整趟跑完后,才回头给所有经过的状态打分。
- 某种意义上,这是"边玩边总结,等到一趟结束后再统一打分"。
- 你无法中途打分,只有跑到底才能知道"整条线路"的得分。
- 好处是"不用知道地图概率",坏处是"必须一趟一趟地跑,状态更新速度慢,方差大"。

完成一整个回合后更新价值估计,使用实际得到的总回报来更新无偏但方差大,需要完整回合
4.2 时序差分(TD)方法
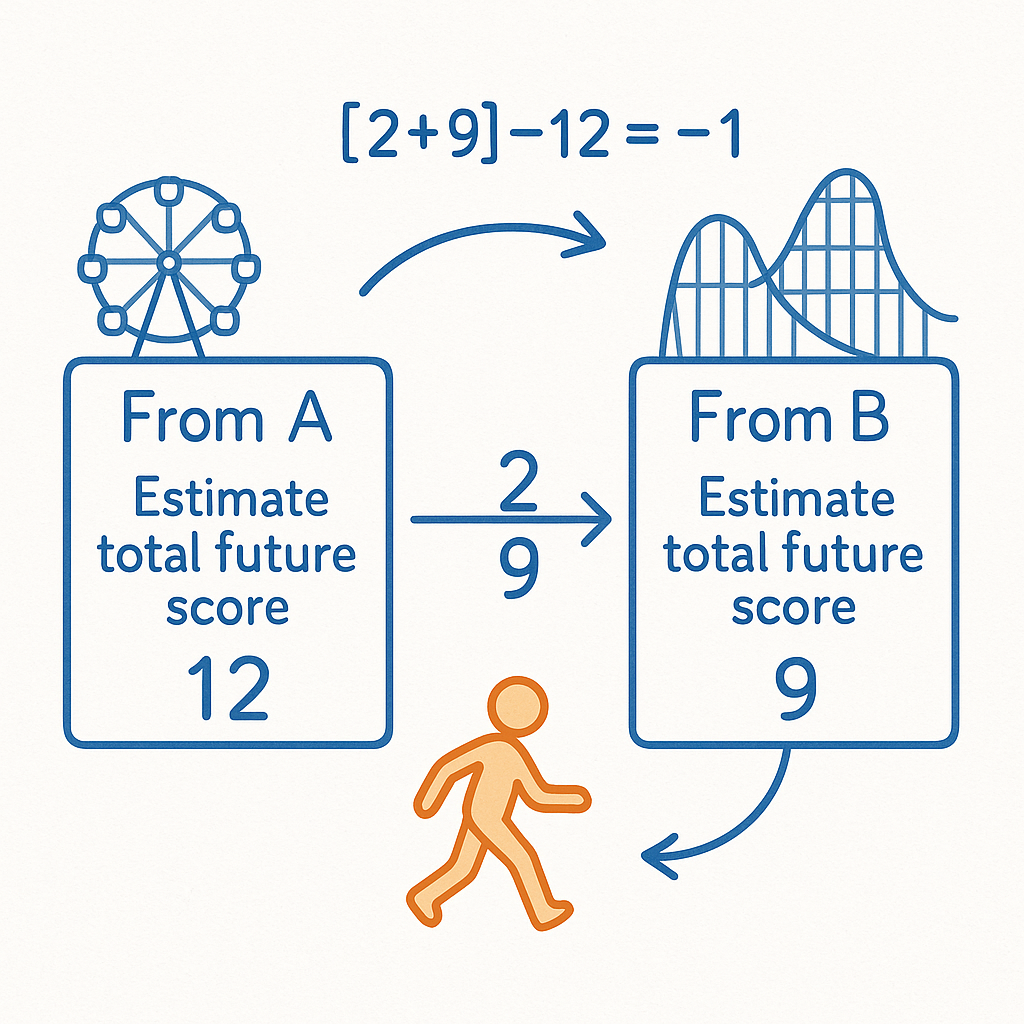
比喻场景:想象你去游乐园,手里有本粗略的"分数手札":
- 当你在景点 A 时,你手札里写着"从 A 出发,估计未来总共可以拿到 12 分"。
- 你真正从 A 出发,走了一步,来到 B,此时你手札里可能写着"从 B 出发,估计未来总共可以拿到 9 分"。
- 你马上就能拿到 B 的"即时分数"比如 2 分,然后从 B 的手札里可以知道"后面还去别的地方还能赚 9 分"。
- 这时,你就可以把"真实到 B 位时拿到的分数 + 之后估计的 9 分"与手札里原先标的"从 A 开始应该是 12 分"做个对比:[2+9]−12=−1,说明原来写在 A 的"12 分"稍微有点高估了。
直观理解:
- 既不用完整模型,也不需要等"一整趟"跑完就打分,而是在"每走一步"时,就先估计一下当前的好玩程度,然后把估计与"下一步估计"之间的差别拿来改进自己。
- 走到每个新景点,拿到一小段即时反馈,就能立刻调整之前写在前面景点的"价值估计"。
- 这样渐进式地,一边玩一边修正,快速学到哪个地方后面值不值得去。
无需完整回合,可在线更新数据利用效率高结合了采样和自举(bootstrapping)
| 特点 | 动态规划(DP) | 蒙特卡洛(MC) | 时序差分(TD) |
|---|---|---|---|
| 需不需要"完整模型"? | 需要(需要知道状态转移概率和奖励) | 不需要(实际跑一趟再回头估计) | 不需要(走一步、估一步,靠自己记录估计) |
| 更新时机 | 并非在环境中"真实跑",是在脑子里/纸上"推演" | 要等"跑完整条线路"后,才能计算回报并更新 | 走每一步就能更新,不用等跑完整条线路 |
| 估计方式 | 完全用"贝尔曼方程"一次性展开所有可选动作 | 用"整趟回报"当真实值,不做引导估计 | 用"即时回报 + 下一状态估计"来做引导估计 |
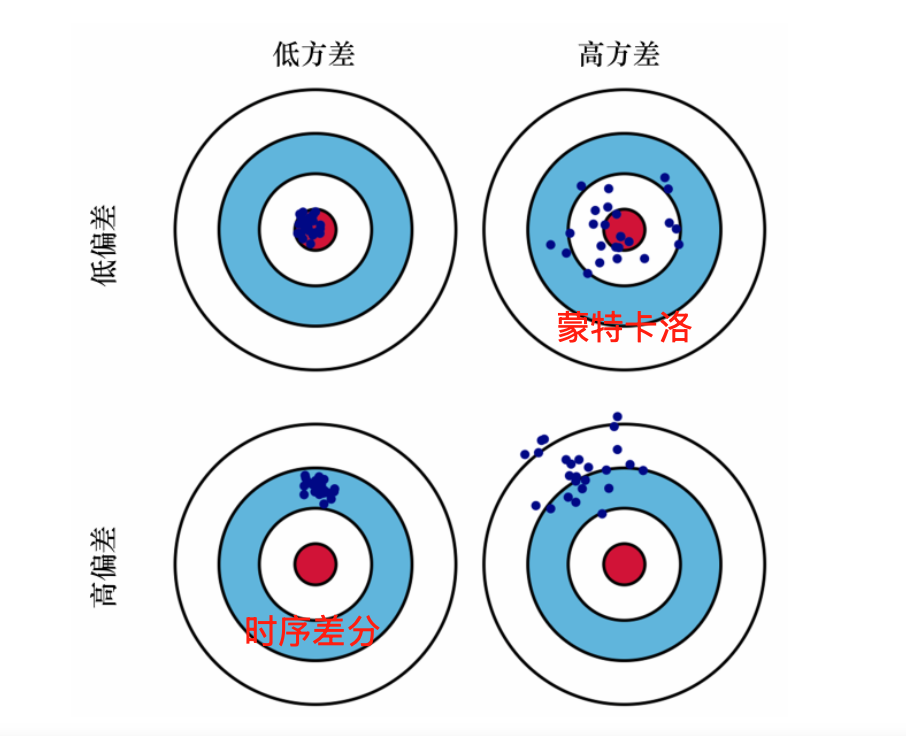
| 偏差/方差 | 只要模型对,理论上无偏;方差不谈,因为是解析计算 | 无偏(样本平均是真实期望),但方差大 | 有偏(依赖当前估计),但方差小(只看一步) |
| 是否在线学习 | 一般是"全局推算",不是真正在线 | 只有在回合结束后才更新,不算严格在线 | 可以"边走边学",是真正的在线更新 |
5. Q-学习算法与SARSA算法的详细对比
5.1 Q-学习算法详解
你是个冒险家,每次都想知道“如果我一不小心碰到各种挑战,却总能挑到最棒的路线,最后能拿到多少宝藏”。
实际上你走的路可能是随意探索(有时左转、有时右转),但心里一直默念:“假设我下次肯定选最好的那条路,我会得到多少?”
特点:
目标很“乐观”:每次都假设下步能选最优路线,所以学到的数字往往偏高。
勇于冒险:即使实际走得糟糕,更新时也不管“我真走的是哪条”,只管“最理想的那条”有多好。
5.2 SARSA算法详解
你还是那个冒险家,但这次你承诺“我今后也会按同样的随机方式(或 ε-贪心)去探索”,所以我学到的“下次期待收益”完全源自我真实的选择习惯。
每次走完一步,心里估算:“我刚走的这条,按照我平常会走的套路,接下来还能拿多少宝藏?”
特点:
更“保守”:真实走哪条,就按哪条的表现来更新,数据不吹嘘。
风险更小:不会总是想当然地“下次肯定走最好那条”,所以学到的预期更稳妥。
5.3 主要区别总结
-
同策略:行为策略(用于生成样本)与目标策略(要学习或改进的策略)相同
-
异策略:行为策略与目标策略不同,智能体可用一种策略(如更“探索”的 ε-贪心)来采样,而学习或评估另一种更“贪心”的策略
| 特征 | SARSA | Q-学习 |
|---|---|---|
| 策略类型 | 同策略(on-policy) | 异策略(off-policy) |
| 更新目标 | 按照我真走的那条路来计算 | 假设下一步我肯定走最好的 |
| 风险偏好 | 由于跟随探索策略,表现更"保守",风险小 | 直接追求最大值,可能过于"乐观",风险大 |
两者都是基于价值的时序差分控制算法;
区分在于:SARSA 是同策略TD,Q-学习是异策略TD。
6. 函数逼近与深度强化学习
当状态空间巨大或连续时,表格方法不再适用,我们需要函数逼近器。
6.1 深度Q网络(DQN)
DQN结合深度学习和Q-learning,引入多项创新:
- 经验回放: 存储转移(s,a,r,s')打破样本相关性
- 目标网络: 使用延迟更新的参数网络稳定训练
- 端到端学习: 直接从原始输入(如图像)到动作
# DQN基本流程
初始化回放记忆D和Q网络
初始化目标网络
对每个回合:
初始化状态
对每一步:
选择动作(通常用ε-贪心策略)
执行动作,观察奖励和下一状态
将经验存入回放记忆
从记忆中随机采样batch
计算目标Q值
更新Q网络参数最小化预测误差
定期更新目标网络6.2 策略梯度与Actor-Critic方法
策略梯度方法直接优化策略:
- REINFORCE: 使用整个回合的回报来调整策略参数
- Actor-Critic: 同时学习策略(Actor)和价值函数(Critic)
- PPO/TRPO: 改进的策略优化算法,控制策略更新步长
7. 代码实战:GridWorld环境
让我们看一个实际的例子:在GridWorld环境中实现动态规划算法。
7.1 环境设置
GridWorld是一个10x10的网格世界:
- 起始点在左上角
- 中心有+1奖励(目标)
- 部分格子有-1奖励(陷阱)
- 灰色格子为墙壁(不可移动)
7.2 策略评估实现
// 评估当前策略的价值函数
evaluatePolicy: function() {
// 创建新的价值函数数组
var Vnew = zeros(this.ns);
for(var s=0; s < this.ns; s++) {
var v = 0.0;
var poss = this.env.allowedActions(s);
for(var i=0, n=poss.length; i < n; i++) {
var a = poss[i];
// 当前策略下选择动作a的概率
var prob = this.P[a*this.ns+s];
// 下一状态
var ns = this.env.nextStateDistribution(s,a);
// 获得的奖励
var rs = this.env.reward(s,a,ns);
// 贝尔曼备份
v += prob * (rs + this.gamma * this.V[ns]);
}
Vnew[s] = v;
}
// 更新价值函数
this.V = Vnew;
}7.3 策略改进实现
// 根据当前值函数改进策略
updatePolicy: function() {
for(var s=0; s < this.ns; s++) {
var poss = this.env.allowedActions(s);
var vmax, nmax;
var vs = [];
// 计算每个动作的价值
for(var i=0, n=poss.length; i < n; i++) {
var a = poss[i];
var ns = this.env.nextStateDistribution(s,a);
var rs = this.env.reward(s,a,ns);
// 计算Q(s,a)
var v = rs + this.gamma * this.V[ns];
vs.push(v);
if(i === 0 || v > vmax) { vmax = v; nmax = 1; }
else if(v === vmax) { nmax += 1; }
}
// 更新策略:对最优动作平均分配概率
for(var i=0, n=poss.length; i < n; i++) {
var a = poss[i];
this.P[a*this.ns+s] = (vs[i] === vmax) ? 1.0/nmax : 0.0;
}
}
}7.4 使用算法
// 创建环境和智能体
env = new Gridworld();
agent = new RL.DPAgent(env, {'gamma':0.9});
// 重复调用直至收敛
agent.learn();
// 使用训练好的智能体行动
var action = agent.act();8. 非马尔可夫环境的处理技巧
现实世界中,很多问题不满足马尔可夫性质。以下是三种处理方法:
8.1 特征扩展:滑动窗口
将历史观测和动作作为当前状态的一部分:
# 使用最近k步历史构建扩展状态
def make_state(obs_history, action_history, k):
return np.concatenate([
obs_history[-k:].flatten(),
action_history[-k+1:].flatten()
])8.2 使用记忆机制:RNN/LSTM
利用循环神经网络从历史中提取隐藏状态:
# LSTM网络示例
model = Sequential([
LSTM(128, input_shape=(None, obs_dim)),
Dense(action_dim, activation='softmax')
])8.3 外部记忆:Transformer与神经图灵机
- Transformer: 通过自注意力机制捕捉长距离依赖
- 神经图灵机(NTM): 维护可微分的外部内存矩阵,进行读写操作
9. 面试常见问题解析
9.1 理论问题
Q: 强化学习与监督学习、无监督学习有什么区别?
A:
- 监督学习: 利用标注好的输入-输出对最小化预测误差
- 无监督学习: 无标签,从数据分布中挖掘结构(如聚类)
- 强化学习: 通过试错与环境交互获得延迟奖励,优化长期回报
Q: 有模型和免模型学习有什么区别?
A:
- 有模型(Model-Based): 学习或已知环境动态模型,结合规划算法决策,样本效率高
- 免模型(Model-Free): 不构建环境模型,直接从经验中学习价值或策略,更简单但样本消耗大
9.2 算法问题
Q: 策略迭代和价值迭代为什么等价?
A: 两者都能收敛到相同的最优值函数和最优策略。策略迭代通过交替评估和改进,价值迭代通过最优方程迭代,但最终都找到能选择最大期望回报动作的策略。
Q: Q-learning为什么是off-policy的?
A: Q-learning学习的是最优动作价值函数,不依赖于用于生成样本的行为策略。它使用max操作选择下一步的最优动作值,而不是当前策略下实际执行的动作。
9.3 实践问题
Q: 强化学习的应用场景有哪些?
A: 常见应用包括:
- 游戏AI(围棋、Dota2、星际争霸)
- 机器人控制(行走、抓取)
- 自动驾驶决策系统
- 推荐系统优化
- 金融交易和投资组合管理
- 资源调度(如数据中心能源优化)
10.总结与展望
强化学习作为一个快速发展的领域,正在重塑AI的可能性边界。从理论基础到实际应用,强化学习提供了一套强大的工具来解决复杂的序列决策问题。
本文从基础概念开始,系统介绍了马尔可夫决策过程、动态规划方法、无模型学习算法、函数逼近技术,并通过代码示例展示了实际实现。我们还探讨了非马尔可夫环境的处理方法和面试常见问题。
随着计算能力的增长和算法的改进,强化学习将继续推动自动驾驶、机器人技术、医疗健康等领域的创新。掌握这一技术,就是掌握了未来AI发展的关键。
11.参考资源
- Sutton & Barto, "Reinforcement Learning: An Introduction"
- David Silver's Reinforcement Learning Course
- OpenAI Spinning Up
- Deep Mind's publications on RL
- REINFORCEjs library documentation


















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











