







定义
统计上,经常用Pearson矩相关系数来衡量两个变量
X
和
对于总体,我们记皮尔逊相关系数为
ρ
,计算公式为
这里, (cov) 代表协方差, σX 代表 X 的标准误。因为
所以上面的相关系数计算公式还可以写为
这里, μX 代表 X 的均值,
所以上面的公式还可以写为
对于样本,我们用 r 代表样本皮尔逊相关系数。我们可以用样本协方差和标准差代替总体方差和标准差来计算样本相关系数。比如
这里 n 代表样本个数,
以及
这里 sx=1n−1∑ni=1(xi−x¯)2−−−−−−−−−−−−−−√ 代表样本标准误差,而 (xi−x¯sx) 就是样本的标准分数或者z-分数。
皮尔逊相关系数的数学性质及几何意义
不论是样本还是总体,皮尔逊相关系数绝对值总是小于等于1的。如果相关系数等于
1
或者
皮尔逊相关系数一个非常重要的性质就是不随着两个变量的位置改变、大小缩放而改变。比如,把
X
变为
下面是几个皮尔逊相关系数的例子。
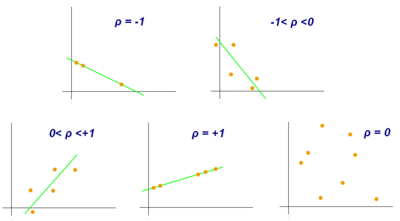
相关系数介于0和1之间。相关系数为1就意味着
X
和
更一般的,当且仅当 Xi 和 Yi 落在各自均值的同一侧时, (Xi−X¯¯¯)(Yi−Y¯¯¯) 为正。因此当 Xi 和 Yi 相对于均值倾向于同时增加或者同时减小时相关系数为正。反之,相关系数为负。而且这种趋势越强就说明相关系数的绝对值越大。
如果数据经过了标准化处理,那么皮尔逊相关系数表示的就是这两个
n
维向量夹角的余弦值。也就是说如果有
注意事项
皮尔逊相关系数非常有用,但也不能滥用,我们来看一些需要注意的地方。
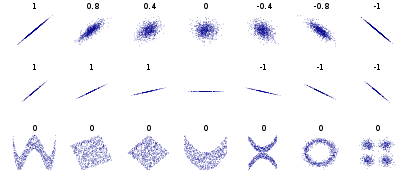
- 皮尔逊相关系数是一个线性关系测度,但 r <script type="math/tex" id="MathJax-Element-58">r</script>比较小不能代表变量间没有关系,只能说明变量间没有线性关系或者线性关系比较弱。实际上变量间可能存在非线性关系(下图有几个非线性关系例子),对数据进行一些合适的变换可以增大它们之间的线性关系。
- 解释相关系数时要考虑实际情况。比如你可能计算出一些人鞋子大小和智商高低相关系数非常大,但这很显然是不合理的,这时相关系数比较大可能仅仅是巧合。
- 相关不代表因果,不能把相关系数和因果关系混在一起。比如夏天冰激凌销量大,冷饮销量也比较大,它们之间存在相关关系,但我们不能说是冰激凌销量大导致冷饮销量也大,这完全是两码事,实际上温度才是导致它们销量上升的原因。
- 相关系数和回归系数也要区分开,相关系数不代表直线斜率。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









