






引言
Inception networks 是图像分类任务中具有里程碑意义的一类网络结构,起源于 2014 年的 GoogLeNet (Inception V1),随后分别诞生了 Inception V2 & V3 和 Inception V4 & ResNet,每个版本的 inception 都是基于前一版本的改进,理解这些改进能帮助我们优化自己的网络。本文按时间顺序介绍 Inception Networks 的进化过程。
Inception V1
所有 Inception networks 起源于 Inception V1,首先讨论该结构的提出是为了解决什么问题,然后解释它是如何解决的。
为了解决什么问题?
- 目标在图像中的大小总是存在着很大的变化(如图 1 中的狗狗),因此选择合适的卷积核尺寸十分困难。通常来说,大卷积核能更好捕获大尺度目标信息,而小卷积核对小尺度目标更优;
- 为进一步提高准确率,最直接的方法是增加网络层数,但计算量会迅速增加;
- 简单增加网络层数还容易产生过拟合和梯度消失问题。

针对问题一
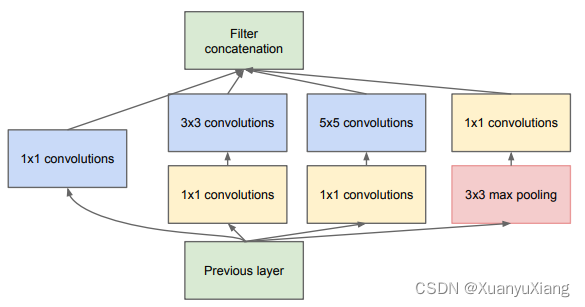
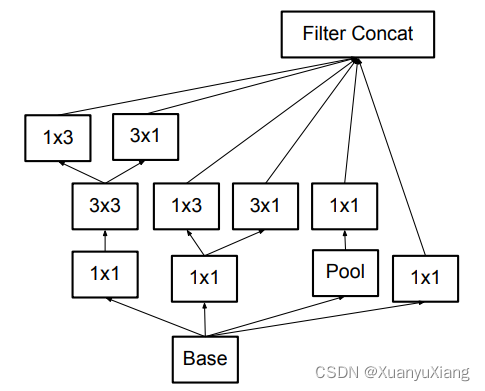
在同一层使用多种尺寸的卷积核,增加网络对多尺度目标的特征提取能力,于是诞生了最初的 inception module,如图 2 所示:

对输入同时采用 3 种尺度的卷积并进行 max pooling(作者说增加池化操作后效果更好),将得到的不同尺度特征图连接在一起作为输出。
针对问题二
上图 max pooling 不会改变输入通道数,当特征图经过若干个 inception module 后,通道数会大大增加,除此之外,直接使用 32 个 5 × 5 卷积和先使用 16 个 1 × 1 卷积,再使用 32 个 5 × 5 卷积效果相同,且后者参数量更少。因此,在每个分支中增加 1 × 1 卷积,减少特征图通道数,就可以实现减小计算量的目的。新的 inception module 如图 3 所示:
针对问题三
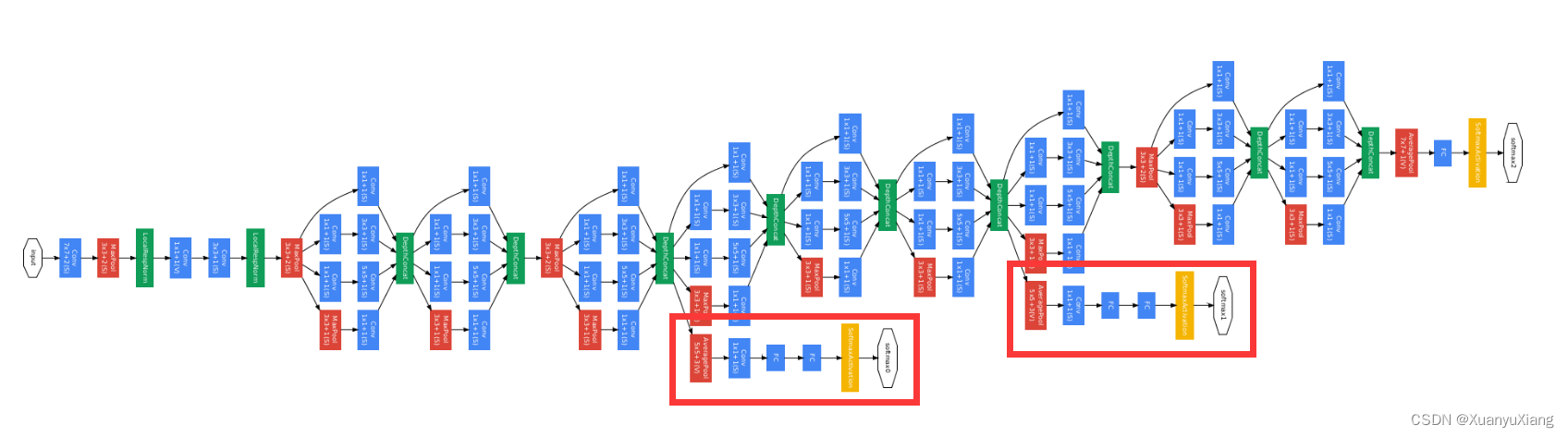
深层网络通常会出现梯度消失和过拟合问题,对此作者在网络的浅层和中层分别添加了 辅助分类器,希望能直接将梯度注入浅层和中层,并增加正则化能力,完整的 GoogLeNet 如下图所示,辅助分类器用矩形标识出来:
Inception V2 & V3
Inception V2 和 inception V3 由同一篇 论文 提出,同理,先说要解决的问题再说解决方法。
为了解决什么问题?
- 进一步增加计算效率;
- 减少特征信息的丢失。
针对问题一
作者提出一系列方法将大卷积核分解成数个小卷积核,在满足效果的情况下减少了参数量。首先是将一个 5 × 5 conv 分解成两个 3 × 3 conv,参数量减少了 28%,如图 5 所示,该模块在论文中被用在网络的前层。
其次,作者发现可以将 n × n conv 分解成两个非对称的 1 × n conv 和 n × 1 conv,例如将 3 × 3 conv 分解成 1 × 3 conv 和 3 × 1 conv 可以节省 33% 参数量,得到的对应模块如图 6 所示:
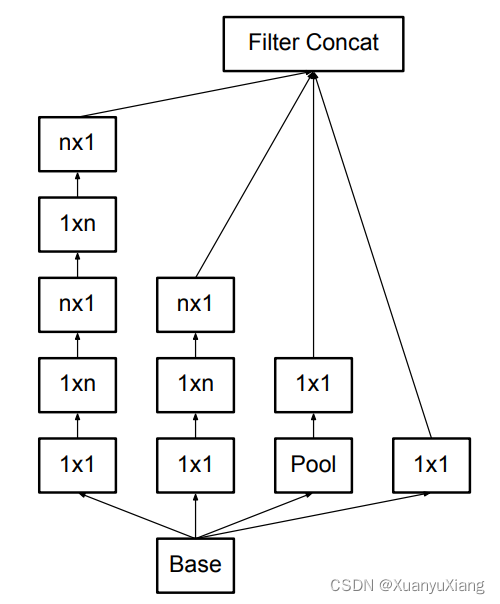
作者提到图 6 模块用在 12~20 大小的特征图上效果更好,实验中他们设置 n = 7,在论文中被用在网络的中层。
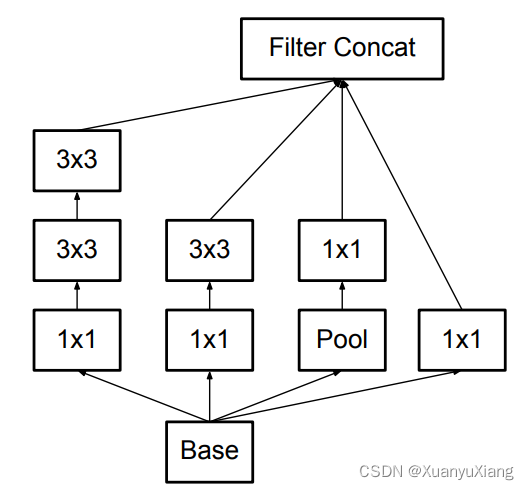
在分类网络的后层,特征图空间尺寸较小,为了提升通道数保留更多信息,作者进一步提出了图 7 所示模块:
针对问题二
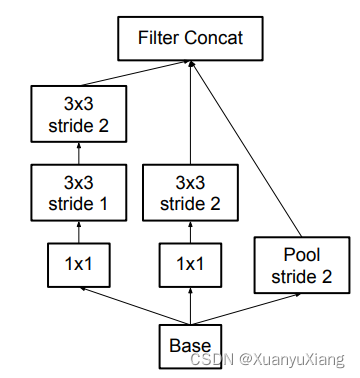
分类网络中有专门降低空间尺寸的模块,GoogLeNet 通过在 inception module 前增加 max pooling 实现,如图 8 所示:
作者认为先通过池化层会减少特征图包含的空间信息,一种简单的方法是将池化层放到 inception module 之后,但这样会增加 3 倍的计算量。因此提出了改进模块,如图 9 所示,没有减少 inception module 可以利用的信息,同时实现了空间尺寸的降低。
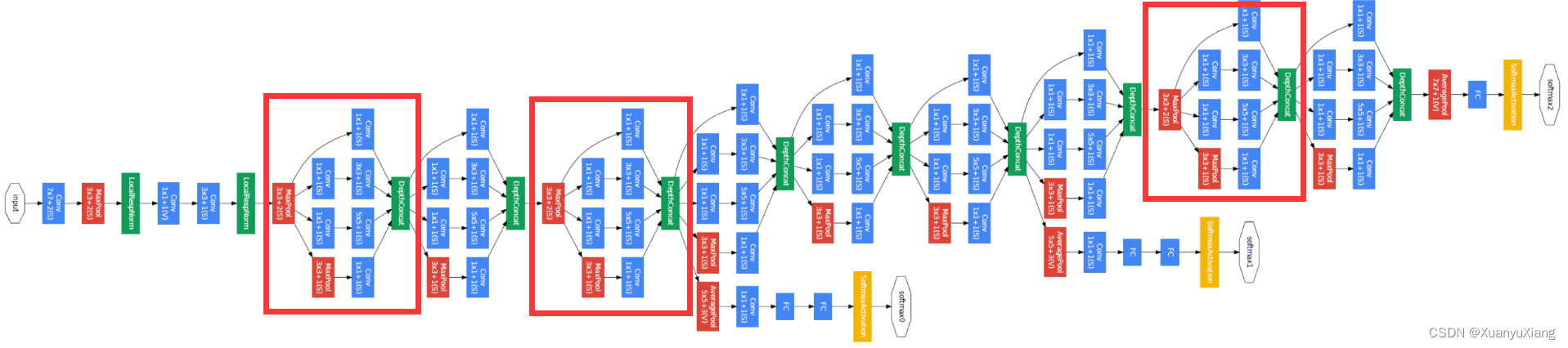
最终完整的 Inception V2 networks 如图 10 所示,分别利用了图 5,6,7,9 中的改进模块。
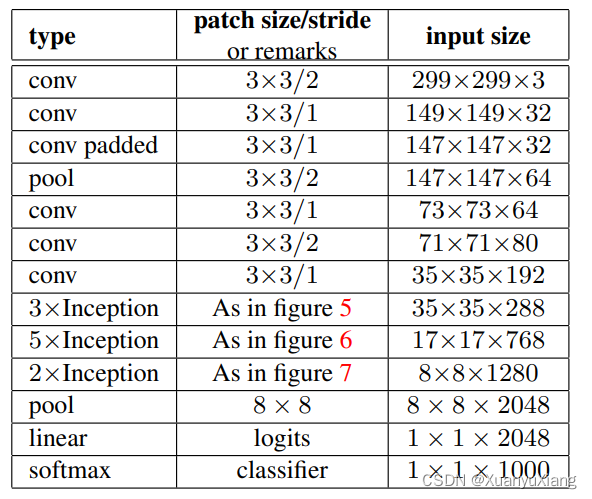
Inception V3
作者发现在网络训练前期,是否使用辅助分类器没有对准确率产生很大影响,在训练后期准确率接近饱和时,使用辅助分类器的准确率更高;浅层辅助分类器似乎没有产生很大的影响;在辅助分类器分支增加正则化操作(例如 Batch Norm,Dropout)能提升准确率。因此,作者认为辅助分类器更多是起 regularizes 的作用。V3 相比 V2 网络结构几乎一致,增加了下述改进:
- 使用 RMSProp 参数更新器;
- 去掉浅层辅助分类器,在辅助分类器分支增加 Batch Norm 操作;
- 增加 Label Smoothing 损失(针对分类损失的正则化项,避免网络过拟合)。
Inception V4 & ResNet
Inception V4 和 inception-ResNet V1,inception-ResNet V2 都出自于 论文,为了清晰简洁,这里我们只讨论 inception-ResNet,V1 和 V2 结构相同,只是超参数设置有差异。Inception net 和 ResNet 都是 2015 年具有里程碑意义的网络结构,很自然会让人想到将这两种结构结合在一起是否能进一步提升性能。
作者首先修改了网络的 stem 模块,如图 11 所示。stem 指网络最开始对图像进行处理的部分,由于图像数据具有冗余性,通常 stem 都会将图像下采样到合适尺寸的特征图。
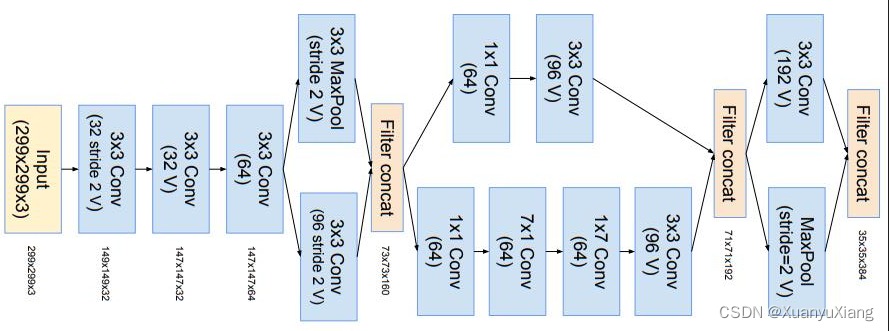
为了让残差连接起作用,卷积前后的通道数必须相同,作者在原始卷积后增加了 1 × 1 conv 来保持通道数的一致,如图 12 所示:
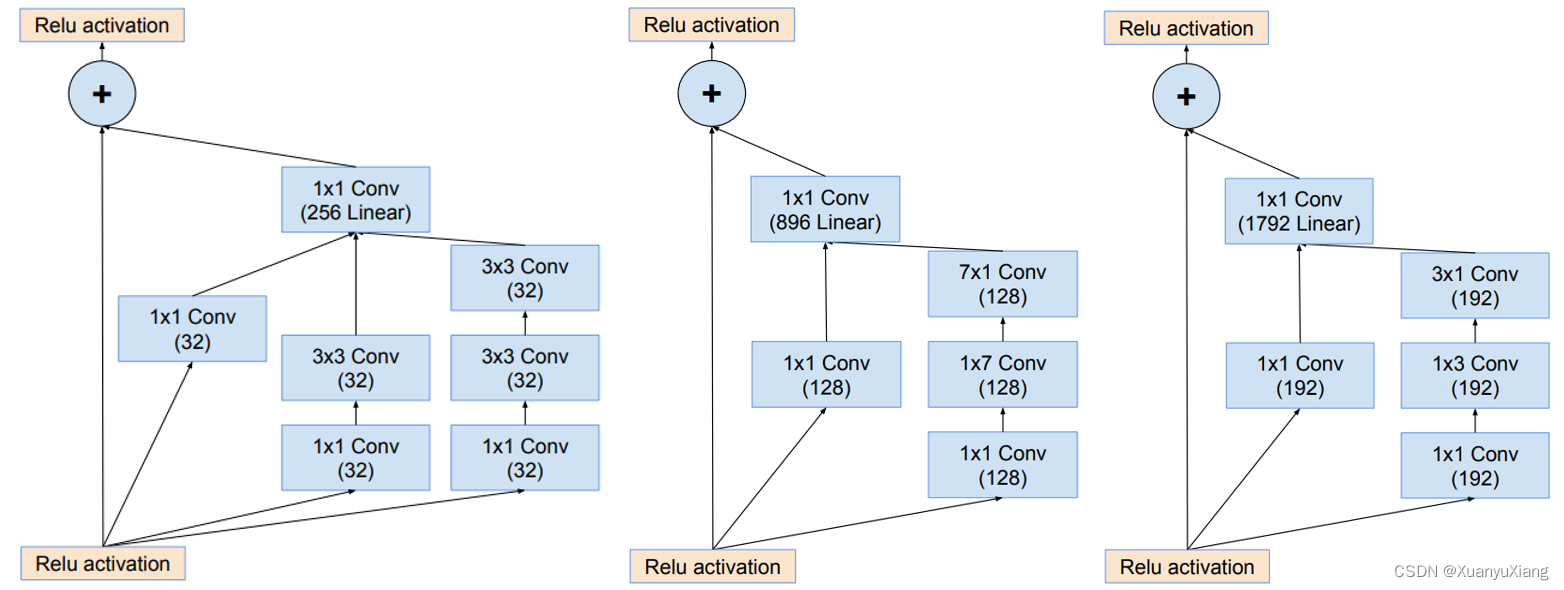
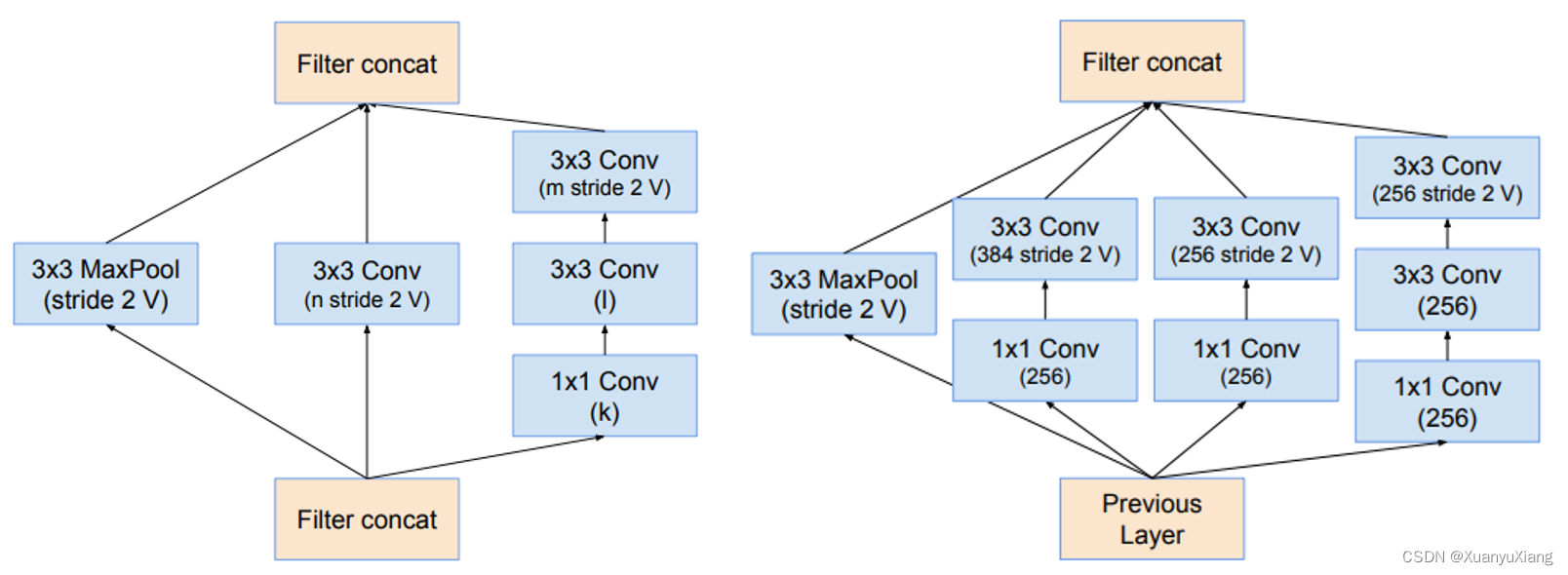
Inception module 并不会增加通道数,通道数的增加由空间尺寸降低模块实现,作者针对不同尺寸的降低使用了不同的结构,如图 13 所示:
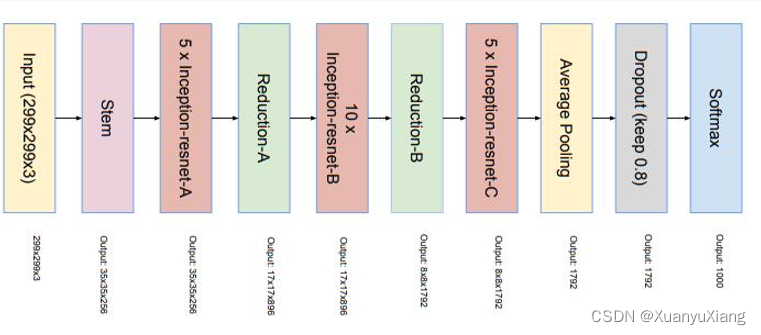
最终的整体网络结构如图 14 所示:
残差缩放
作者发现当滤波器的数量大于 1000 后训练会变得很不稳定,平均池化层前一层的输出几乎都是零,这一点在 ResNet 原文中也有提及。作者的建议是从 0.1~0.3 随机采样缩放因子来缩放残差连接上的值,可以稳定训练。















 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









