







论文标题:
WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
论文链接:
https://github.com/wangxw5/wikiDiverse
作者:
以棠

实体链接,即将文本中出现的命名实体链接到知识图谱中对应的实体上,是一个广受关注的任务,它对于信息抽取、问答系统、语义检索等多个任务都有重要的意义。近年来,随着越来越多的信息以多模态的形式出现(本文特指图片+文本),因此亟需多模态实体链接的数据集以进行研究。
尽管在这一领域已有一些相关工作贡献了数据集,但是它们存在一定的缺陷:1)有限的主题类型; 2) 有限的实体类型;3)有限的歧义现象;4)是否开源易获取等。
针对这个问题,我们提出了一个多模态实体链接数据集。为构建这一数据集,我们基于多个角度的考虑:首先,我们综合参考现有的实体链接数据集、分析图文匹配程度、实体消歧难度等信息,采用WikiNews的“图片-标题”对作为原始数据,将Wikipedia作为对应的知识图谱。其次,我们采集了体育、政治、娱乐、灾难、科技、犯罪、经济、教育、健康、天气主题的图文对,并进行了质量低下、色情、暴恐信息的清洗,对图片类型进行了归一化(因为部分图片为gif等格式),从而保证数据的高覆盖性和质量。最后,我们引入了众包标注平台进行数据标注,在此过程中设计了详细的标注规范,特别地,我们关注人物、组织、地点、国家、事件、作品(包含图书、画作等)、其他等多个实体类型。
我们的数据集的统计数据如下表所示:
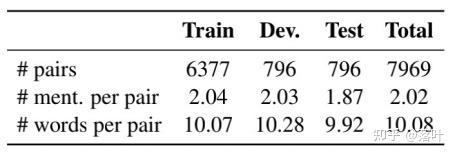
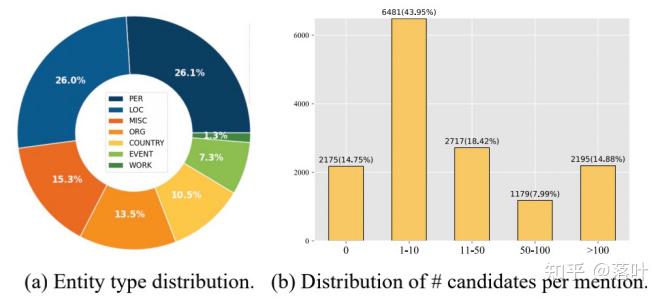
此外,我们还提出了一个基础的模型框架对该数据集进行了测试。我们的框架分为两个步骤。在第一个步骤,我们从知识图谱的百万级别的实体中,对每个实体名称多路召回TopK个候选实体,这一过程综合考虑了实体名称-实体共现概率,文本相似度,图片相似度等信息:

取得的效果如下:

在第二个步骤,我们基于双塔模型得到实体名称和实体的向量(见下图),该模型的核心组件是输入图像和文本的多模态编码器,我们参考现有的模型,设计并实现了三个经典baseline:1) 将图片和文本拼接后输入单流Transformer,2)图片和文本先分别过Transformer,然后再拼接并输入Transformer;3)图片和文本先分别过Transformer,然后属于基于跨模态注意力机制和自注意力机制的Transformer。
特别地,为了增强表示学习的能力,我们引入了对比学习损失函数:
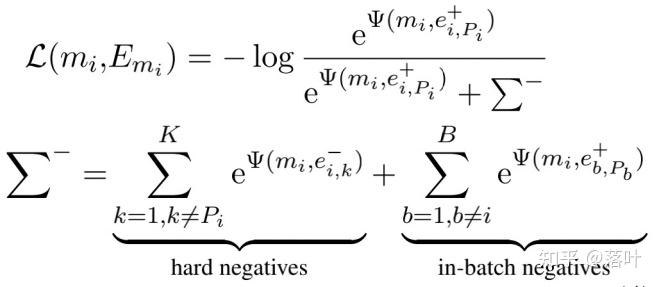
其中hard negatives是指实体名称的候选实体,其因为互相容易混淆而需要较强的区分性。In-batch negatives是指该batch内其他实体名称对应的实体。
实验效果如下:

如对相关技术比较感兴趣,欢迎关注我们的「AdaSeq序列理解技术」专栏,或加入钉钉 (4170025534) 进行技术交流。















 4856
4856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









