







多模态信息提取是多模态学习与信息提取技术的结合。传统上,IE的研究侧重于从纯文本中提取实体和关系,其中信息主要以自然语言文本的格式表示。然而,互联网的快速发展导致了大量的数据,包括文本、音频、图像、视频和其他形式。互联网上的多模态信息,在某些场景下,只对文本数据信息进行提取,可能会造成数据信息的丢失;因此,研究人员开始讨论如何从多模态数据中提取所需的信息。现有的工作已经证明,添加视觉模态信息可以在工作中发挥重要作用,如知识图补全和三元组分类,多源信息显示出在知识图上推理的潜力。“模态”的定义很广泛,可以直观地理解为不同类型的多媒体数据或更细粒度的概念。区分模式的关键点可以理解为数据是否异质。例如,对于演员,可以在互联网上找到相关的信息,包括文字介绍、个人图片、影视作品、影视音频。这四种数据分别对应文本、图片、视频和声音,可以理解为对象的多模态数据。在多模态数据环境中,跨模态数据既有模态特征又有语义共性。多模态IE是多模态学习与IE技术的结合。目前,已有的单模态表示学习方法取得了良好的效果,为多模态表示的获取奠定了基础。深度学习的发展也为多模态研究提供了便利。下面的一个小节讨论了多模态命名实体识别。
传统的命名实体识别只考虑文本信息,忽略了其他模式的集成对命名实体识别的影响。针对利用单模态信息识别命名实体的不足,学者们开始研究结合多模态信息的命名实体识别任务。大多数多模态方法利用注意机制提取视觉信息,而忽略了文本与图像之间是否存在相关性,与文本无关的视觉信息会对多模态模型的学习产生不确定性甚至负面影响。Sun等人提出了基于文本-图像关系传播的多模态BERT模型(RP-BERT)的多模态BERT模型,用于文本-图像关系分类(TRC),并在MNER上训练该模型RP-BERT。该模型在TRC和MNER中都获得了最高的F1分数。实验结果表明,文本-图像关系的传播能够减少无关图像的干扰,RP-BERT能够更好地利用基于文本-图像关系的视觉信息。Zhang等人构建并获得了一个包含来自Twitter的多模式推文的大规模标记数据集。为了利用视觉信息识别多模式推文中的命名实体,Zhang提出了一种链接文本和视觉信息的自适应共注意网络(adaptive co-attention network, ACN)。在隐层和CRF层之间插入自适应共注意网络层,实现文本和图片的相互注意;因此,通过引入门控多模态融合模块来决定何时依赖视觉信息,每个单词都获得了多模态表示。同时还采用了滤波门模块对视觉信息产生的噪声进行滤波。该模型引入基于CNN + BiLSTM + CRF的图像信息,在构建的数据集上添加ACN模块,准确率为72.75%,召回率为68.74%,F1为70.79%,优于CNN + BiLSTM + CRF。一些MNER模型没有充分利用不同模态语义单元之间的细粒度语义对应,这可能会优化多模态表示学习。Zhang等人提出了一种用于MNER的统一多模态图融合(UMGF)方法。首先使用统一的多模态图来表示输入的句子和图像。在合成过程中,每个目标图像充当一个图像节点。每个单词充当一个文本节点。该图捕获了模态语义单位(单词和视觉对象)之间的各种语义关系。在堆叠多个基于图的多模态融合层后,迭代进行语义交互以学习节点表示。使用图神经网络与两个模态单元交互,进一步使用了跨模态门控的双流版本。最后通过线性层和CRF编码层得到最终输出。在两个基准数据集上的实验中,该模型的F1值高于其他方法的F1值,UMGF对多模态命名实体识别具有较好的效果。
目前,多模态命名实体识别已经取得了很大的进展,但大多数研究都集中在英语上,而以往的中文命名实体识别研究大多集中在单模态文本上。Sui等人从文本和声学两方面研究了中文多模态命名实体识别,构建了包含文本和声学内容的大规模人工标注多模态命名实体识别数据(CNERTA)。基于该数据集,建立了BiLSTM-CRF和BERT-CRF等一系列可使用文本模式或多模式特征的基线模型。此外,通过引入语音-文本对齐辅助任务,提出了一种简单的多模态多任务模型(M3T)T)来捕获文本和声音模式之间的自然单调对齐。在M3T模型中,声学信息通过跨模态注意模块(CMA)集成到文本表示中。通过大量的实验,作者证明了引入声学模式可以使中文命名实体识别模型受益。
然而,现有的MNER和MRE方法在将不相关的目标图像合并到文本中时往往存在误差敏感的问题。为了解决这些问题,Chen, X.等人提出了一种新的分层视觉前缀融合网络(HVPNeT),用于视觉增强的实体和关系提取,旨在实现更有效和更健壮的性能。具体而言,本文将视觉表示作为可插入的视觉前缀来指导错误不敏感预测决策的文本表示。本文进一步提出了一种动态门控聚合策略,将分层的多尺度视觉特征作为融合的视觉前缀。现有的MNER方法容易受到一些隐式交互作用的影响,容易忽略所涉及的重要特征。为了解决这一问题,X. Wang等人提出通过识别和突出一些任务突出特征来精炼跨模态注意。每个特征的显著性根据其与从外部知识库派生的扩展实体标签词的相关性来衡量。本文进一步提出了一种基于端到端Transformer的MNER框架,该框架的体系结构更加简洁,性能也比以前的方法更好。
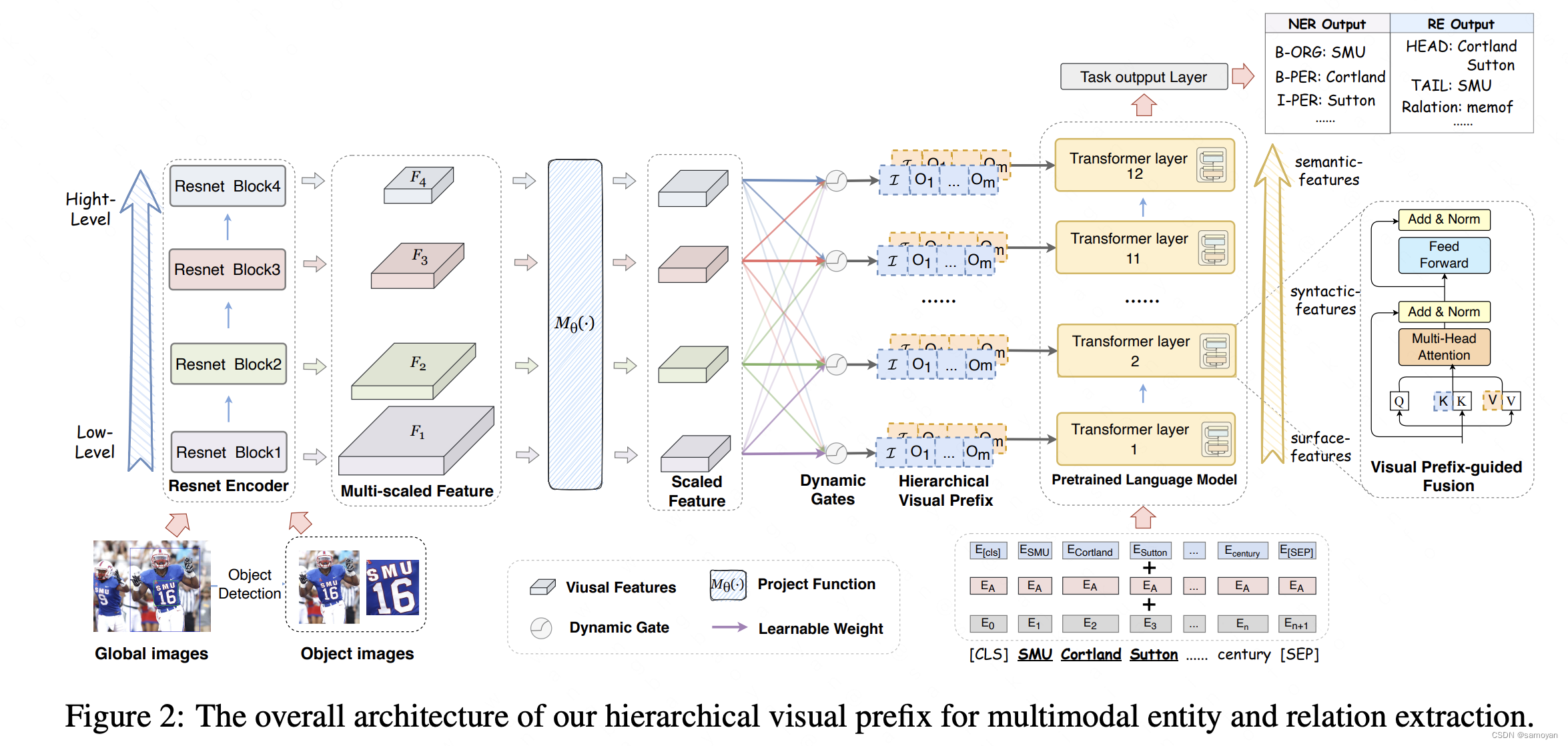
代码地址: https://github.com/zjunlp/HVPNeT
优点:提高了模态信息的命名实体识别效果,多模态实体链接技术有助于实体对齐。
缺点:需要改进模态融合,需要加强对容易混淆的实体的区分


















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











