






池化层(Pooling layer)是深度学习神经网络中常用的一种层类型,它的作用是对输入数据进行降采样(downsampling)操作。池化层通过在输入数据的局部区域上进行聚合操作,将该区域的信息压缩成一个单一的值,从而减少数据的维度。
池化层的主要作用如下:
-
特征提取:池化层可以通过保留输入数据的主要特征,提取出对模型有用的信息。通过对输入数据进行降采样,池化层可以减少模型中的参数数量,从而降低模型的复杂度,提高计算效率。
-
平移不变性:池化层对输入数据的平移不变性具有一定的保持作用。即,无论输入数据在图像中的位置如何变化,池化层都可以提取出相似的特征表示。这对于处理图像中的物体平移、旋转等变换具有一定的鲁棒性。
-
降低过拟合:池化层可以通过降低输入数据的空间维度,减少模型的参数数量,从而有助于减少过拟合的风险。过拟合是指模型在训练数据上表现很好,但在未见过的测试数据上表现较差的现象。通过降低数据的维度,池化层可以减少模型的复杂度,提高模型的泛化能力。
在PyTorch中,最大池化层可以通过torch.nn.MaxPool2d类来实现。这个类用于实现二维最大池化操作,常用于卷积神经网络中。
下面是一个使用最大池化层的简单示例:
import torch
from torch import nn
from torch.nn import MaxPool2d
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
#注意:此尺寸是不符合要求的,因此要做一些尺寸变换:
input=torch.reshape(input,(-1,1,5,5))
class Demo(nn.Module):
def __init__(self):
super(Demo, self).__init__()
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=True)
#kernel_size=3形成一个3x3的池化核,默认步长为池化核的大小,ceil_mode=True:决定是否取不足池化核的值
def forward(self,input):
output=self.maxpool(input)
return output
maxpool=Demo()
output=maxpool(input)
print(output)输出结果为:
tensor([[[[2., 3.],
[5., 1.]]]])
首先导入了torch和torch.nn模块。然后,创建了一个最大池化层maxpool,指定了池化核的大小为3,并设置了步幅。接下来,生成了一个形状为(1, 1, 5, 5)的输入张量input,其中1表示批大小,1表示通道数,5表示高度,5表示宽度。最后,使用最大池化层对输入张量进行池化操作,并打印出输入张量和池化后的输出张量。
在这个示例中,最大池化层将输入张量按3x3的池化核进行最大池化操作,并将结果输出。输出张量的形状为(1, 1, 2, 2),其中2表示池化后的高度和宽度。
接下来进行数据集的实战:
# 最大池化层
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('../Data',train=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
class Demo(nn.Module):
def __init__(self):
super(Demo, self).__init__()
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=True)
#kernel_size=3形成一个3x3的池化核,默认步长为池化核的大小,ceil_mode=True:决定是否取不足池化核的值
def forward(self,input):
output=self.maxpool(input)
return output
maxpool=Demo()
step=0
writer=SummaryWriter('logs_Maxpool')
for data in dataloader:
imgs,targets=data
writer.add_images('input',imgs,step)
output=maxpool(imgs)
writer.add_images('output',output,step)
step=step+1
writer.close()其运行结果:
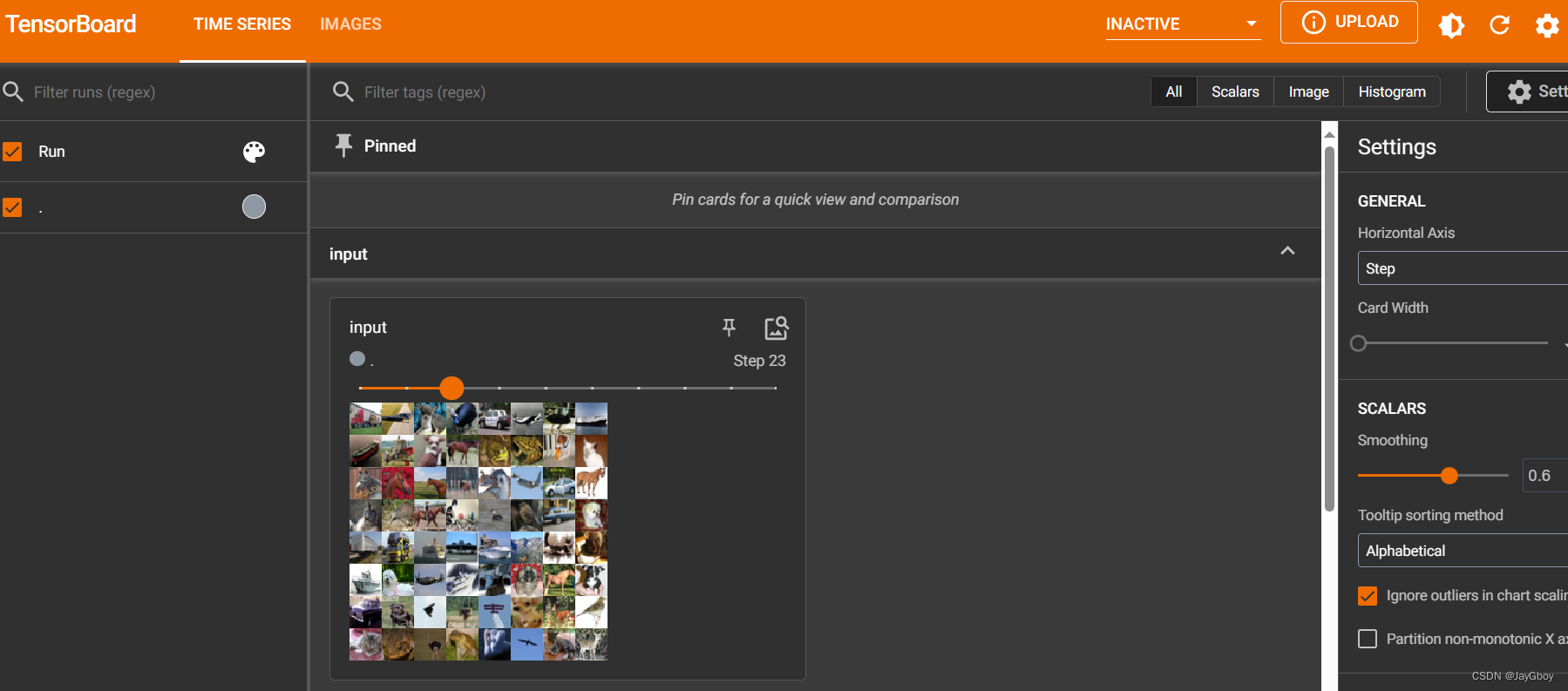
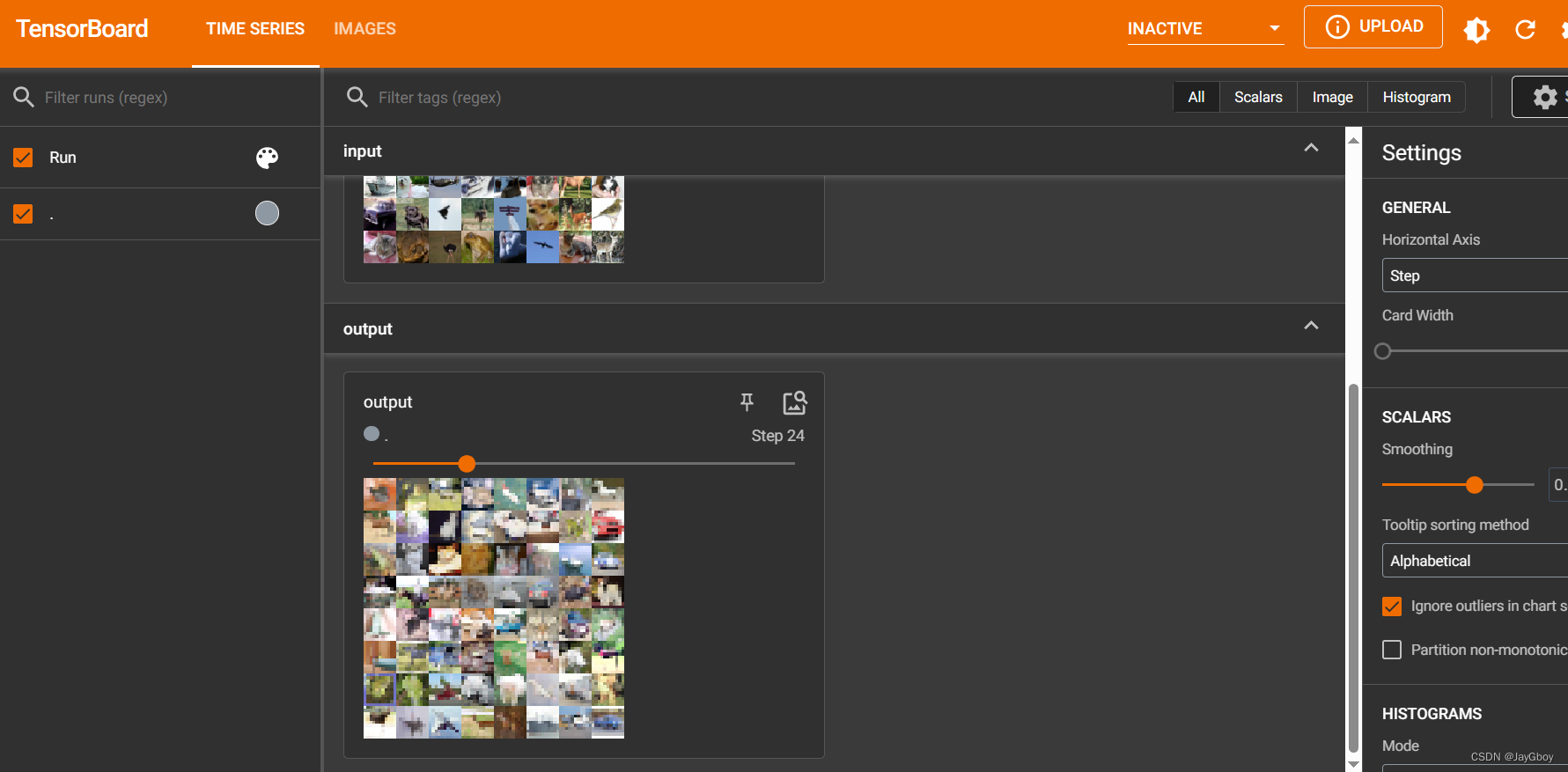
常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化选取输入局部区域中的最大值作为输出,而平均池化计算输入局部区域的平均值作为输出。
池化层在深度学习神经网络中扮演着重要的角色,它可以提取特征、降低模型复杂度、增加模型的鲁棒性,并有助于减少过拟合的风险。















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











