






 本文介绍了CUDA编程模型,如何利用NVIDIAGPU的并行计算能力加速神经网络模型的训练,以及在PyTorch中的实践步骤。强调了GPU对深度学习任务如神经网络训练的显著加速作用和性能提升。
本文介绍了CUDA编程模型,如何利用NVIDIAGPU的并行计算能力加速神经网络模型的训练,以及在PyTorch中的实践步骤。强调了GPU对深度学习任务如神经网络训练的显著加速作用和性能提升。
1.什么是CUDA:
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和编程模型。它允许开发者在NVIDIA GPU上进行通用目的的并行计算,包括深度学习、科学计算、图形处理和加密等任务。
CUDA通过提供一组编程接口和工具,使开发者能够利用GPU的并行计算能力。它包括以下主要组件:
1. CUDA编程模型:CUDA提供了一种基于C/C++编程语言的并行编程模型。开发者可以使用CUDA C/C++语言扩展来编写GPU上的并行代码。CUDA编程模型包括主机代码(在CPU上执行)和设备代码(在GPU上执行),开发者可以在主机和设备之间进行数据传输和协同计算。
2. CUDA运行时和驱动程序:CUDA运行时是一个库,提供了访问GPU设备和执行CUDA代码的接口。驱动程序是与GPU硬件交互的软件组件。开发者可以使用CUDA运行时库和驱动程序来加载和执行CUDA代码。
3. CUDA工具集:CUDA提供了一套工具集,用于帮助开发者进行CUDA程序的开发、调试和优化。这些工具包括编译器、调试器、性能分析器和可视化工具等。
CUDA的主要优势在于其并行计算能力和广泛的支持。通过利用GPU的大规模并行计算单元,CUDA可以加速各种计算密集型任务。它在深度学习领域得到广泛应用,许多深度学习框架如PyTorch和TensorFlow都支持CUDA,使得开发者能够在GPU上高效地进行深度学习训练和推理。
需要注意的是,CUDA只能在NVIDIA的GPU上运行,因此它是特定于NVIDIA硬件的。其他厂商的GPU使用不同的并行计算平台和编程模型,如AMD的ROCm和Intel的OneAPI。
2.使用GPU进行神经网络模型训练
使用GPU进行神经网络模型训练可以加速训练速度、处理大规模数据和模型、提供更好的模型性能,并且与PyTorch等深度学习框架良好地集成。这些优点使得GPU成为加速神经网络训练的重要工具,为研究人员和从业者提供了更高效的深度学习开发环境。
要在PyTorch中使用GPU训练完整的神经网络模型,需要执行以下步骤:
-
检查GPU可用性:首先,确保计算机上有可用的GPU。如果使用的是具有NVIDIA GPU的计算机,确保已经安装了适当的NVIDIA驱动程序和CUDA工具包。
-
导入必要的库:在Python脚本的开头,导入PyTorch和其他必要的库。
import torch
import torch.nn as nn
3.接下来便是使用GPU进行神经网络训练的完整代码:
# encoding=gbk
# 开发时间:2024/3/10 19:51
# 使用GPU进行训练:
'''
网络模型
数据
损失函数
三者调用cuda()
'''
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from nn_mode import *
#准备数据集
train_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=True,transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=False,transform=torchvision.transforms.ToTensor())
#输出数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print(train_data_size)
print(test_data_size)
#加载数据集
train_loader=DataLoader(dataset=train_data,batch_size=64)
test_loader=DataLoader(dataset=test_data,batch_size=64)
#创建神经网络
sjnet=Sjnet()
sjnet=sjnet.cuda()#网络模型调用cuda
#损失函数
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()#损失函数调用cuda
#优化器
learn_lr=0.01#便于修改
YHQ=torch.optim.SGD(sjnet.parameters(),lr=learn_lr)
#设置训练网络的参数
train_step=0#训练次数
test_step=0#测试次数
epoch=10#训练轮数
writer=SummaryWriter('wanzheng_GPU_logs')
for i in range(epoch):
print("第{}轮训练".format(i+1))
#开始训练
for data in train_loader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()#数据调用cuda
outputs=sjnet(imgs)
loss=loss_fn(outputs,targets)
#优化器
YHQ.zero_grad() # 将神经网络的梯度置零,以准备进行反向传播
loss.backward() # 执行反向传播,计算神经网络中各个参数的梯度
YHQ.step() # 调用优化器的step()方法,根据计算得到的梯度更新神经网络的参数,完成一次参数更新
train_step =train_step+1
if train_step%100==0:
print('训练次数为:{},loss为:{}'.format(train_step,loss))
writer.add_scalar('train_loss',loss,train_step)
#开始测试
total_loss=0
with torch.no_grad():#上下文管理器,用于指示在接下来的代码块中不计算梯度。
for data in test_loader:
imgs,targets=data
imgs = imgs.cuda()
targets = targets.cuda()#数据调用cuda
outputs = sjnet(imgs)
loss = loss_fn(outputs, targets)#使用损失函数 loss_fn 计算预测输出与目标之间的损失。
total_loss=total_loss+loss#将当前样本的损失加到总损失上,用于累积所有样本的损失。
print('整体测试集上的loss:{}'.format(total_loss))
writer.add_scalar('test_loss', total_loss, test_step)
test_step = test_step+1
torch.save(sjnet,'sjnet_{}.pth'.format(i))
print("模型已保存!")
writer.close()其代码相比于使用CPU的区别在于,网络模型、数据、损失函数这三者调用了cuda()
从运行窗口的输出:
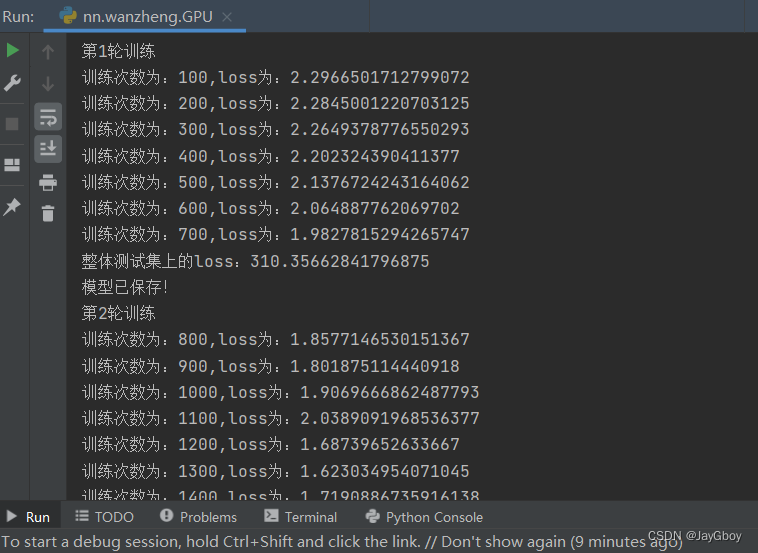
其速度远超使用CPU进行训练的速度。
在TensorBoard中的损失值展示:

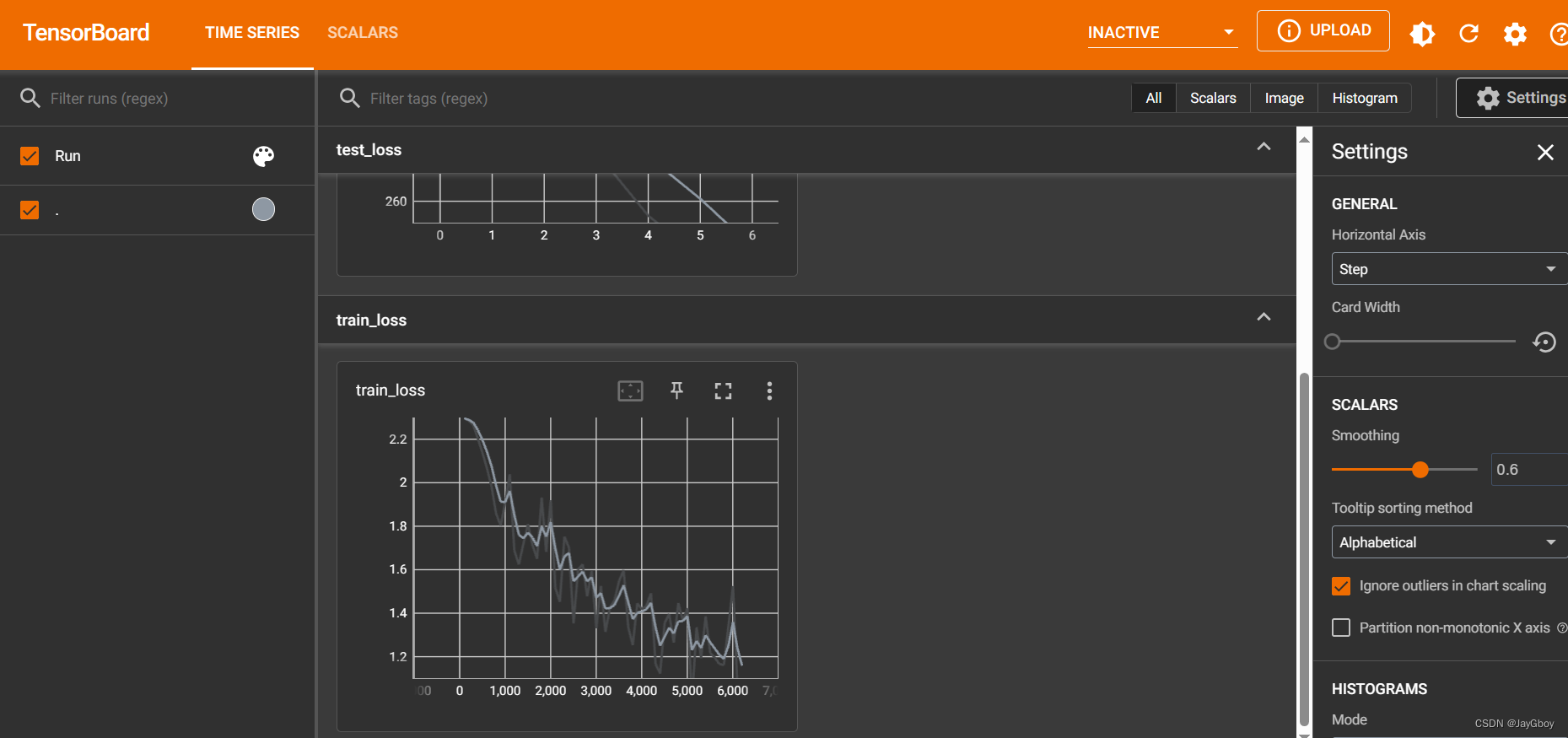
3.PyTorch使用GPU进行神经网络模型训练具有以下优点:
-
加速训练速度:GPU(图形处理器)具有并行计算能力,可以同时执行多个计算任务。相比于使用CPU进行训练,使用GPU可以显著加速神经网络的训练过程。GPU的并行计算能力可以同时处理大量的矩阵运算,这是神经网络训练中的关键操作,从而加快了训练速度。
-
处理大规模数据和模型:神经网络模型和数据集的规模不断增大,需要更强大的计算能力来处理。GPU提供了更多的计算资源,可以有效地处理大规模数据和模型。通过将模型和数据加载到GPU内存中,可以充分利用GPU的并行计算能力,加快训练速度和内存处理速度。
-
支持深度学习框架:PyTorch是一种广泛使用的深度学习框架,它提供了对GPU的良好支持。PyTorch提供了简单易用的API,使得将模型和数据移动到GPU上变得简单,并且可以轻松地在GPU上执行计算。这使得使用GPU进行模型训练变得更加方便和高效。
-
更好的模型性能:由于GPU可以并行处理大量计算任务,使用GPU进行训练可以提高模型的性能。通过加速训练速度,可以更快地迭代和优化模型,从而提高模型的准确性和泛化能力。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











