







 本文提出了一种名为MFI的模态自适应特征交互模块,利用图结构和注意力机制处理多模态MRI数据中的脑肿瘤分割问题,特别关注缺失模态的情况。U-Net-MFI通过分层交互特征,有效融合多模态信息,实验结果显示在BraTS2018数据集上优于现有最先进的方法。
本文提出了一种名为MFI的模态自适应特征交互模块,利用图结构和注意力机制处理多模态MRI数据中的脑肿瘤分割问题,特别关注缺失模态的情况。U-Net-MFI通过分层交互特征,有效融合多模态信息,实验结果显示在BraTS2018数据集上优于现有最先进的方法。
论文地址: https://link.springer.com/chapter/10.1007/978-3-031-16443-9_18
代码仓库: https://github.com/zzc1909/UNET-MFI
摘要
多模态磁共振成像(MRI)在脑肿瘤分割中起着至关重要的作用。然而,缺失模态是临床实践中的常见现象,导致肿瘤分割性能下降。考虑到模态之间存在互补信息,模态之间的特征相互作用对于肿瘤分割很重要。在这项工作中,我们提出了具有多模态代码的模态自适应特征交互(MFI),以自适应地交互不同模态缺失情况下模态之间的特征。 MFI是一个简单而有效的单元,基于图结构和注意力机制,用于学习和交互图节点(模态)之间的互补特征。同时,所提出的多模态代码,指示每个模态是否缺失,指导MFI学习不同缺失情况下节点之间的自适应互补信息。 在U型架构的不同阶段应用MFI与多模态编码,设计了一种新型的U-Net-MFI网络,以分层和自适应的方式交互多模态特征,以进行缺失模态的脑肿瘤分割。实验表明,我们的模型优于目前最先进的脑肿瘤分割方法,但缺少模态。
引言
脑肿瘤是危害人类健康的一种危险疾病,脑肿瘤的准确分割在临床评估和治疗计划中发挥着重要作用。通常采集多个磁共振成像 (MRI) 图像来识别肿瘤区域,例如流体衰减反转恢复 (FLAIR)、对比增强 T1 加权 (T1c)、T1 加权 (T1) 和 T2 加权 (T2)因为它们可以为肿瘤分割提供补充信息。在临床实践中,丢失一种或多种模式的现象可能是由于不同的成像协议或图像损坏而发生的。因此,设计对缺失模态鲁棒的学习方法是必要的。
以前针对缺失模态的医学图像分割方法可以分为三种方法,包括1)为每个模态子集训练单独的模型, 2)合成缺失模态图像,然后使用完整的模态, 3)学习不同模态子集的单一分割模型。 第一种方法需要训练大量模型,每个模型都针对一个缺失的模态场景,这种策略是资源密集型且耗时的。第二种方法需要训练合成网络,生成图像的质量对最终的分割结果有很大影响。第三种方法针对所有可能缺失的模态场景训练单个模型(可能由多个用于分割的模态特定编码器和解码器组成)。最近,有几种方法属于第三类方法。HeMIS将各个模态的特征的一阶矩和二阶矩连接起来作为分割的融合特征。多伦特等人提出了多模态变分自动编码器(MVAE),将所有现有到的模态嵌入到肿瘤分割的共享潜在表示中。RobustSeg将特征分解为模态不变特征和模态特定特征,并根据门控策略采用不变特征生成最终分割结果。目前最先进的方法 RFNet基于区域感知融合模块(RFM),通过自适应聚合不同区域的多模态特征,来建模模态和肿瘤区域的关系。不完整的多模态图像分割的关键挑战是如何有效地融合多模态图像特征,同时对任意缺失模态保持鲁棒性。这些先前的工作要么专注于学习共享/不变特征,要么关注模态与肿瘤区域之间的关系,可能没有充分考虑用于分割的多模态图像之间的互补信息以及模型对不同缺失模态的适应性。
这项工作设计了一种自适应特征交互策略,该策略与多模态特征交互,以适应不同缺失模态的多模态分割。具体来说,我们提出了模态自适应特征交互(MFI),它基于图结构,将每个模态建模为图节点,并基于注意力机制自适应地交互节点特征。为了自适应地学习模态(即图节点)之间的互补特征,我们引入了多模态代码来表示是否观察到不同的模态,以指导学习过程。我们将多模态编码引导的 MFI 插入 U 形架构的不同阶段 ,以分层交互多模态特征。实验表明,我们的方法在 BraTS2018 数据集上的不完整多模态脑肿瘤分割中取得了最先进的结果。
方法
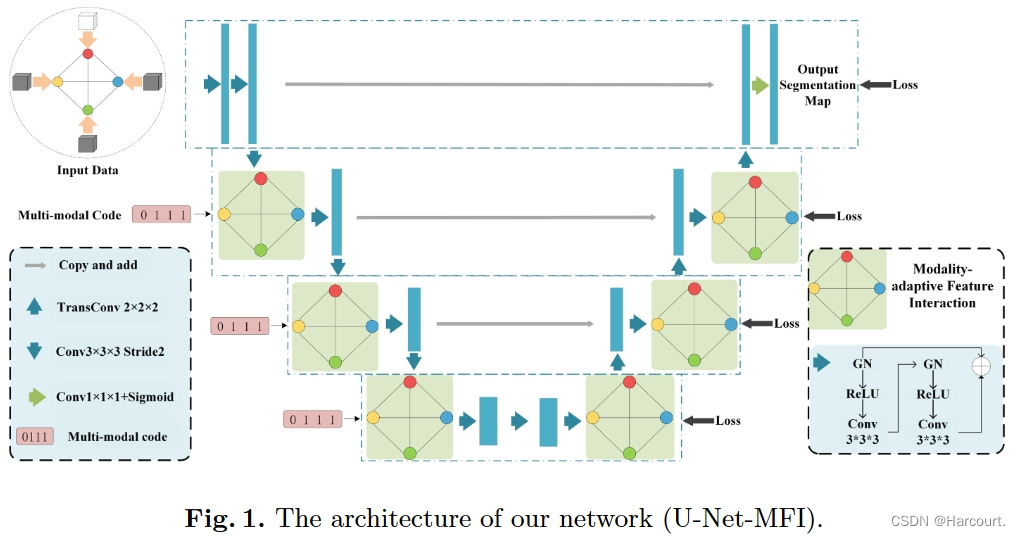
图1:U-Net-MFI网络架构
在本节中,我们将介绍网络设计和模态自适应特征交互(MFI)模块的详细信息,该模块是我们网络中的关键模块。对于脑肿瘤分割,多模态 MRI 图像的序列为
M
=
{
F
L
A
I
R
,
T
1
c
,
T
1
,
T
2
}
M = \{FLAIR, T1c, T1, T2\}
M={FLAIR,T1c,T1,T2}。如图 1 所示,我们的网络被称为 U-Net-MFI,是一个U-shape网络,编码器和解码器都有四个阶段。编码器和解码器中具有相同分辨率的相应阶段之间通过逐元素求和来建立捷径连接。与传统的 U-Net 不同,我们使用 MFI 模块分层交互不同阶段的多模态特征。为了强制网络适应不同的缺失模态场景,我们引入了多模态代码的二进制向量来表示是否观察到不同的模态,以指导 MFI 中的特征交互。我们网络的输入是多模态图像,并且对不同的模态不会共享参数(包括MFI模块),与为不同模态定义不同编码器/解码器的相同。如果未提供模态图像,则其相应的输入将被替换为与输入图像大小相同的零张量。filter尺寸的变换设计请参考图1。
基于该架构,由多模态代码引导的MFI模块分层提取不同模态的特征并相互交互,以适应不同的缺失模态。在解码器的末尾,所有模态特征被连接起来以生成分割图。在最后阶段之前的解码器的多尺度阶段中,我们还附加了分段损失以进行多尺度训练。接下来我们介绍 MFI 模块的详细信息。
模态自适应特征交互
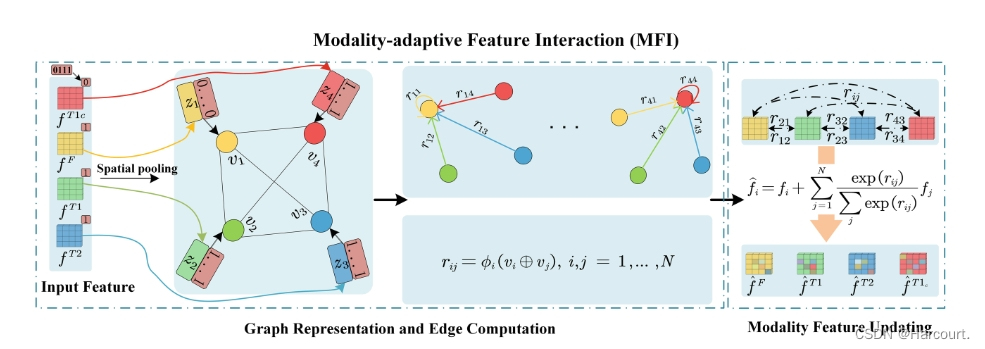
图2:模态自适应特征交互模块的概述
不同的模态对于识别不同的肿瘤区域有不同的贡献。例如,FLAIR 是显示全脑肿瘤的主要方式。然而,观察更多的模态将进一步提高分割的准确性。这一事实意味着不同的模态为肿瘤区域分割提供互补的信息/特征。进一步考虑不同的可能缺失模态情况,特征交互应考虑对模态之间的互补特征进行建模,并且还应适应不同的缺失模态情况。受此动机的启发,所提出的 MFI 被设计用于由多模态编码引导的多模态特征交互,以自适应地学习模态之间的交互特征,如图 2 所示。
在U-Net-MFI的某一阶段的特征空间中,MFI的输入是N个模态的多模态特征
{
f
1
,
.
.
.
,
f
N
}
\{f1,...,fN\}
{f1,...,fN},其中
f
i
∈
R
C
×
H
×
W
×
L
f_{i}\in\mathbb{R}^{C\times H\times W\times L}
fi∈RC×H×W×L,其中
C
C
C是通道数,
W
、
H
、
L
W、H、L
W、H、L表示当前阶段 3D 体积特征的宽度、高度和切片尺寸。使用这些模态特征和多模态编码作为输入,我们首先将每个模态作为一个节点构成一个图,然后设计消息传递以学习合并来自其他模态的特征。所提出的多模态编码
h
h
h(指示是否观察到不同模态)将指导 MFI 学习过程。我们将在下面的段落中讨论细节。
图表征 给定多模态特征和多模态编码,我们构建一个图
G
=
(
V
,
E
)
G =(V, E)
G=(V,E),其中
V
V
V 表示使用特征表征模态的图节点,
E
E
E 表示表征节点(模态)之间关系的邻接边矩阵。
图边计算 此过程是计算成对图节点(即模态)之间的边权重。对于图中的每个第
i
i
i 个节点,我们首先在多模态编码的指导下计算其压缩节点特征以进行边权重计算,压缩节点特征定义为
v
i
=
ψ
s
p
(
f
i
)
⊕
(
h
i
1
)
,
i
=
1
,
⋯
,
N
v_i=\psi_{sp}(f_i)\oplus(h_i\mathbf{1}),\quad i=1,\cdots,N
vi=ψsp(fi)⊕(hi1),i=1,⋯,N 其中 ⊕ 表示concat操作,
ψ
s
p
\psi_{sp}
ψsp表示空间池化操作,
ψ
s
p
(
f
i
)
∈
R
C
\psi_{sp}(f_{i})\in\mathbb{R}^{C}
ψsp(fi)∈RC 。
h
=
{
h
1
,
.
.
.
,
h
N
}
h = \{h_1, ..., h_N \}
h={h1,...,hN}是多模态编码,
h
i
∈
{
0
,
1
}
h_i ∈\{0, 1\}
hi∈{0,1} 是
h
h
h 的第
i
i
i 个元素,指示第
i
i
i 个模态是否缺失。
1
∈
R
C
\mathbf{1}\in R^{C}
1∈RC 是全单值向量且
h
i
1
∈
R
C
h_i\boldsymbol{1}\in\mathbb{R}^C
hi1∈RC 。这样,
v
i
∈
R
2
×
C
v_{i}\in\mathbb{R}^{2\times C}
vi∈R2×C 既包含模态特征又包含模态可用性信息。
接下来我们介绍如何计算特征交互模态之间的边缘权重。我们将第
j
j
j个节点到第
i
i
i个节点之间的边权重表示为
r
i
j
r_{ij}
rij,它的计算为
r
i
j
=
ϕ
i
(
v
i
⊕
v
j
)
,
i
,
j
=
1
,
⋯
,
N
r_{ij}=\phi_i(v_i\oplus v_j),\quad i,j=1,\cdots,N
rij=ϕi(vi⊕vj),i,j=1,⋯,N其中
ϕ
i
\phi_i
ϕi 是一个线性层,后面是Leaky ReLU 。通过这种方式,压缩的节点特征
v
i
v_i
vi 和
v
j
v_j
vj 被馈送到
ϕ
i
\phi_i
ϕi来学习
r
i
j
∈
R
C
r_{ij}\in\mathbb{R}^C
rij∈RC 。由于
v
i
v_i
vi 和
v
j
v_j
vj 包含模态特征和多模态代码信息,因此
r
i
j
r_{ij}
rij 取决于模态
i
i
i、
j
j
j 的可用性信息。
模态特征更新 基于边权重,该过程是交互节点的模态特征
f
i
(
i
=
1
⋯
N
)
f_{i}(i=1\cdots N)
fi(i=1⋯N) 以获得每个节点的更新特征
f
^
i
\hat{f}_i
f^i,即模态。以第
i
i
i 个节点为例,我们将
R
i
=
{
r
i
1
,
.
.
.
,
r
i
N
}
R_{i}=\{r_{i1},...,r_{iN}\}
Ri={ri1,...,riN}(计算所得边权重) 馈送到 softmax 层以获得归一化注意力分数,然后输出特征
f
^
i
\hat{f}_i
f^i计算如下:
f
^
i
=
f
i
+
∑
j
=
1
N
exp
(
r
i
j
)
∑
j
exp
(
r
i
j
)
f
j
,
i
=
1
,
⋯
,
N
\hat{f}_i=f_i+\sum_{j=1}^N\frac{\exp(r_{ij})}{\sum_j\exp(r_{ij})}f_j,\quad i=1,\cdots,N
f^i=fi+j=1∑N∑jexp(rij)exp(rij)fj,i=1,⋯,N请注意,更新后的特征
f
^
i
\hat{f}_i
f^i是输入特征
f
i
f_{i}
fi 与基于残差跳跃连接的其他模态“借用”的特征相加。这实现了我们的模态之间特征交互的想法。
总之,MFI 旨在从多模态编码引导的多模态图像特征中学习互补特征。将 MFI 模块插入 U-Net-MFI 的分层多模态特征空间有助于深入捕获这些互补特征以进行分割。
网络细节和训练损失
如图 1 所示,该网络是一个 U 形架构 ,嵌入了我们提出的 MFI。在编码器的每个阶段,我们使用两个 3 × 3 × 3 卷积与组归一化(GN)(组大小为 8)和 ReLU 激活,然后是加性恒等跳跃连接。然后,使用步长为 2 的 3 × 3 × 3 滤波器的卷积层,将每个维度的特征图分辨率降低 2 倍,同时将特征通道数增加 2 倍。每个解码器阶段开始使用内核大小为 2 × 2 × 2、步幅为 2 的转置卷积来提高特征图的分辨率并减少通道数。然后将上采样的特征与编码器相应阶段的特征相加,然后进行 MFI。在解码器的末尾,使用 1×1×1 卷积将输出通道数减少到 3,然后使用 sigmoid 函数。在最终阶段之前的解码器的多尺度阶段中,我们在MFI之后应用3×3×3卷积和上采样来生成多尺度分割以实现多尺度损失。
多尺度训练损失基于交叉熵损失
L
C
E
L_{CE}
LCE和软Dice损失
L
D
i
c
e
L_{Dice}
LDice的组合,在解码器的每个阶段(U-Net-MFI解码器中的四个阶段)用作深度监督,损失是
L
(
y
^
,
y
)
=
∑
s
=
1
4
λ
L
C
E
(
y
^
s
,
y
s
)
+
L
D
i
c
e
(
y
^
s
,
y
s
)
L(\hat{y},y)=\sum_{s=1}^4\lambda L_{CE}(\hat{y}^s,y^s)+L_{Dice}(\hat{y}^s,y^s)
L(y^,y)=s=1∑4λLCE(y^s,ys)+LDice(y^s,ys)其中
y
s
y^s
ys和
y
^
s
\hat{y}^s
y^s 分别表示阶段 s 中的真实概率和分割概率。
λ
λ
λ是一个权衡参数,实验中根据经验设置为0.5。
实验
数据集:BraTS 2018
显卡:RTX 3090GPU
模型性能比较:
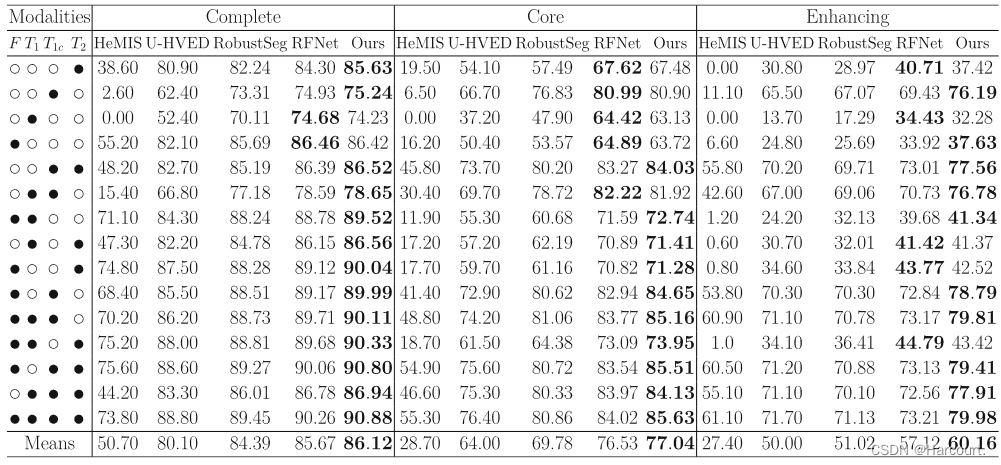
表1:BraTS 2018上各个方法的比较,其中●表示模态存在,o表示模态缺失















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









