









论文
《A Neural Probabilistic Language Model》2003
Neural Network Language Model
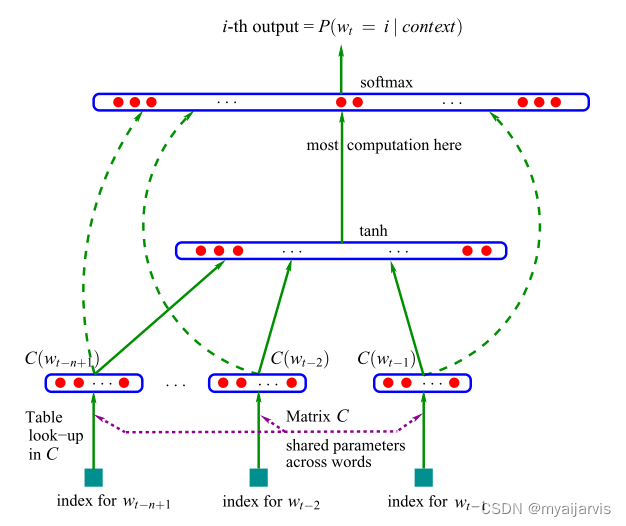

其中双曲正切 tanh 逐个元素地应用,W 可选为零(无直接连接),x 是词特征层激活向量,它是来自矩阵 C 的输入词特征的串联:
代码
【参考:graykode/nlp-tutorial: Natural Language Processing Tutorial for Deep Learning Researchers】
【参考:Neural Network Language Model PyTorch实现_哔哩哔哩_bilibili】
【参考:NNLM的PyTorch实现 - mathor】
# %%
# code by Tae Hwan Jung @graykode
import torch
import torch.nn as nn
import torch.optim as optim
def make_batch():
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split() # space tokenizer
input = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
target = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Linear(n_step * m, n_hidden, bias=False)
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(n_step * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
# 论文中 y = b+Wx+Utanh(d+Hx)
'''
X: [batch_size, n_step]
'''
X = self.C(X) # X : [batch_size, n_step, m] # [batch_size,seq_len,embedding_size]
X = X.view(-1, n_step * m) # [batch_size, n_step * m] # [batch_size,seq_len*embedding_size]
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
if __name__ == '__main__':
n_step = 2 # number of steps, n-1 in paper # 相当于seq_len
n_hidden = 2 # number of hidden size, h in paper
m = 2 # embedding size, m in paper # embedding_size
sentences = ["i like dog", "i love coffee", "i hate milk"]
# batch_size = 3
word_list = " ".join(sentences).split() # 先把列表变成字符串再以空格为分隔符切分字符串,返回List[str]
word_list = list(set(word_list)) # 去重
word_dict = {w: i for i, w in enumerate(word_list)} # word2idx
number_dict = {i: w for i, w in enumerate(word_list)} # idx2word
n_class = len(word_dict) # number of Vocabulary :n_class=7
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# input_batch:[batch_size,seq_len] target_batch:[batch_size,1]
input_batch, target_batch = make_batch() # 构建数据
# 转成Tensor类型
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input_batch) # [batch_size,n_class]
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Predict
# predict = model(input_batch).data.max(1, keepdim=True)[1] # 原来的代码
predict=model(input_batch) # [batch_size,n_class]
predict_index=predict.max(dim=1, # 每行求最大值下标
keepdim=True) # 保持维度不变 [batch_size,1]
predict_data=predict_index[1] # 只返回最大值的每个索引 [batch_size,1]
# Test
# print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()]) # 原来的代码
sent=[sen.split()[:2] for sen in sentences] # 取每句话前面两个单词 例如:["i like dog"]->[[i,like]]
predict_text=[
number_dict[n.item()] # 到idx2word查找word
for n in predict_data.squeeze() # [batch_size]
]
print(sent,'->',predict_text)
Epoch: 1000 cost = 0.040966
Epoch: 2000 cost = 0.008105
Epoch: 3000 cost = 0.002991
Epoch: 4000 cost = 0.001298
Epoch: 5000 cost = 0.000630
[['i', 'like'], ['i', 'love'], ['i', 'hate']] -> ['dog', 'coffee', 'milk']
代码二
【参考:ML_Study/NNLModel.py at master · pi408637535/ML_Study】
# -*- coding: utf-8 -*-
# @Time : 2020/4/16 15:59
# @Author : piguanghua
# @FileName: NNLModel.py
# @Software: PyCharm
# this model train word embedding NNLM
# Impletation refer to <A Neural Probabilistic Language Model> pdf:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
from matplotlib import pyplot as plt
import numpy as np
import random
import torch as t
import torch.nn as nn
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from collections import Counter
# hypotrical parameter
USE_CUDA = t.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
t.manual_seed(53113)
if USE_CUDA:
t.cuda.manual_seed(53113)
NUM_EPOCHS = 200
BATCH_SIZE = 1 # the batch size
LEARNING_RATE = 0.2 # the initial learning rate
EMBEDDING_SIZE = 300
N_GRAM = 2
HIDDEN_UNIT = 128
UNK = "<unk>"
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
tokens = test_sentence
trigram = [((test_sentence[i], test_sentence[i + 1]), test_sentence[i + 2]) for i in range(len(tokens) - N_GRAM)]
words = dict(Counter(tokens).most_common()) # 返回所有单词的频率 例如[('a', 5), ('b', 2), ('r', 2)]
def cmp(a, b):
return (a > b) - (a < b)
words = sorted(iter(words.keys()), key=words.get, reverse=False)
words += UNK
word2id = {k: i for i, k in enumerate(words)}
id2word = {i: k for i, k in enumerate(words)}
H = N_GRAM * EMBEDDING_SIZE
U = HIDDEN_UNIT
class MyDataset(Dataset):
def __init__(self, word2id, id2word, tokens):
self.word2id = word2id
self.id2word = id2word
self.tokens = tokens
# self.word_encoder = [word2idx[token] for token in tokens]
def __len__(self):
return len(self.tokens) - N_GRAM
def __getitem__(self, index):
((word_0, word_1), word_2) = trigram[index]
word_0 = self.word2id[word_0]
word_1 = self.word2id[word_1]
word_2 = self.word2id[word_2]
return word_0, word_1, word_2
class NNLM(nn.Module):
def __init__(self, vocab, dim):
super(NNLM, self).__init__()
self.embed = nn.Embedding(vocab, dim)
self.H = nn.Parameter(t.randn(EMBEDDING_SIZE * N_GRAM, HIDDEN_UNIT))
self.d = nn.Parameter(t.randn(HIDDEN_UNIT))
self.U = nn.Parameter(t.randn(HIDDEN_UNIT, vocab))
self.b = nn.Parameter(t.randn(vocab))
self.W = nn.Parameter(t.randn(EMBEDDING_SIZE * N_GRAM, vocab))
'''
words:batch,sequence
# x: [batch_size, n_step*n_class]
'''
def forward(self, word_0, word_1):
batch = word_0.shape[0]
word_0 = self.embed(word_0)
word_1 = self.embed(word_1)
words = t.cat((word_0, word_1), dim=1)
words = words.view(batch, -1) # batch,sequence*dim
tanh = t.tanh(t.mm(words, self.H) + self.d) # tanh:batch,HIDDEN_UNIT
hidden_output = t.mm(tanh, self.U) + self.b # hidden_output:batch,vocab
y = hidden_output + t.mm(words, self.W)
y = F.log_softmax(y, 1)
return -y
def evaluate(model, word_0, word_1):
model.eval()
word_0 = word_0.long()
word_1 = word_1.long()
softmax = model(word_0, word_1)
predict = t.argmax(softmax, 1)
word_0 = word_0.cpu().detach().numpy()
word_1 = word_1.cpu().detach().numpy()
predict = predict.cpu().detach().numpy()
word_sequence = [((id2word[word_0[i]], id2word[word_1[i]]), id2word[predict[i]]) for i in range(len(word_0))]
print(word_sequence)
model.train()
def train(model, dataloader, optimizer, criterion):
model.train()
for e in range(NUM_EPOCHS):
for i, (word_0, word_1, word_2) in enumerate(dataloader):
word_0 = word_0.long()
word_1 = word_1.long()
word_2 = word_2.long()
if USE_CUDA:
word_0 = word_0.cuda()
word_1 = word_1.cuda()
word_2 = word_2.cuda()
optimizer.zero_grad()
softmax = model(word_0, word_1)
loss = criterion(softmax, word_2)
loss.backward()
optimizer.step()
if i % 50 == 0:
print("epoch: {}, iter: {}, loss: {}".format(e, i, loss.item()))
evaluate(model, word_0, word_1)
# embedding_weights = model.input_embeddings()
# np.save("embedding-{}".format(EMBEDDING_SIZE), embedding_weights)
t.save(model.state_dict(), "embedding-{}.pth".format(EMBEDDING_SIZE))
if __name__ == '__main__':
word2idx, idx2word, = word2id, id2word
dim = EMBEDDING_SIZE
hidden = HIDDEN_UNIT
model = NNLM(len(word2id.keys()), dim)
for name, parameters in model.named_parameters():
print(name, ':', parameters.size())
model.to(t.device("cuda" if USE_CUDA else 'cpu'))
lr = 1e-4
optimizer = t.optim.SGD(model.parameters(), lr=lr)
dataloader = DataLoader(dataset=MyDataset(word2id, id2word, tokens), batch_size=BATCH_SIZE)
criterion = nn.CrossEntropyLoss()
train(model, dataloader, optimizer, criterion)
epoch: 197, iter: 0, loss: 24.425506591796875
[(('When', 'forty'), 'blood')]
epoch: 197, iter: 50, loss: 48.05567932128906
[(('within', 'thine'), 'now,')]
epoch: 197, iter: 100, loss: 1.5497195136049413e-06
[(('made', 'when'), 'thou')]
epoch: 198, iter: 0, loss: 24.238327026367188
[(('When', 'forty'), 'blood')]
epoch: 198, iter: 50, loss: 47.84667205810547
[(('within', 'thine'), 'now,')]
epoch: 198, iter: 100, loss: 1.5497195136049413e-06
[(('made', 'when'), 'thou')]
epoch: 199, iter: 0, loss: 24.051368713378906
[(('When', 'forty'), 'blood')]
epoch: 199, iter: 50, loss: 47.63882064819336
[(('within', 'thine'), 'now,')]
epoch: 199, iter: 100, loss: 1.5497195136049413e-06
[(('made', 'when'), 'thou')]
进程已结束,退出代码0















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









