






Stability.ai趁着春节的契机发布了SVD的小更新V1.1版本。这里简单记录下试用体验。
官方地址:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main
这次更新的是一个4.5G的模型,如果你网络不太好,也可以用这个链接:https://pan.quark.cn/s/76f8fdc2cd29
按照官方介绍,稳定视频扩散 (SVD) 1.1 图像到视频是一种扩散模型,它将静态图像作为条件帧,并从中生成视频。

【以上四张图片是官方提供的】
该模型经过训练,可以在给定相同大小的上下文帧的情况下生成分辨率为 1024x576 的 25 帧,并从SVD-xt-1.0 进行微调。
通过 6FPS 和 Motion Bucket Id 127 的固定条件进行微调,以提高输出的一致性,而无需调整超参数。这些条件仍然是可调整的并且尚未被删除。与 SVD 1.0 相比,固定调节设置之外的性能可能会有所不同。
这里画个重点,官方推荐的参数是:
分辨率:1024x576
帧数:25帧
FPS:6
Motion Bucket Id :127
接下来我们使用的测试就以以上参数为基础进行测试。
工作流还是用之前SVD的工作流,只需要把模型替换成新的SVD1.1版本的模型就可以用了。
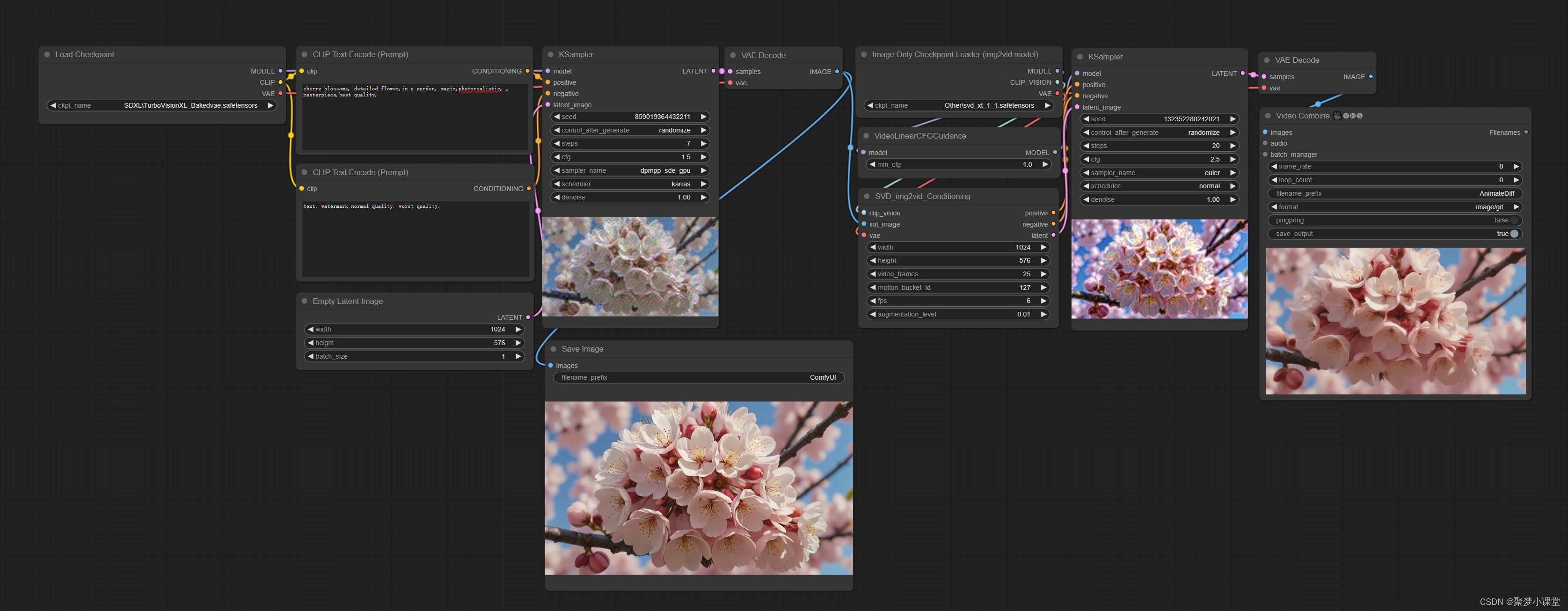
提示词:cherry_blossoms, detailed flower,in a garden, magic,photorealistic, , masterpiece,best quality,


提示词:a girl on the moonface, portrait, detailed face, night,magic world, alice_in_wonderland ,photorealistic, , masterpiece,best quality,


提示词:
Chinese traditional festivals, firecrackers, lanterns, fireworks, prosperous times,photorealistic, , masterpiece,best quality,


但,如果是一些卡通类的形象或者画面主体占画面比较小,还是比较容易崩的,比如说:




关于这个效果,你觉得怎么样呢?
局限性
- 生成的视频相当短(<= 4秒),并且该模型无法实现完美的照片级真实感。
- 该模型可能会生成没有运动或非常缓慢的摄像机平移的视频。
- 模型无法通过文本控制。
- 该模型无法呈现清晰的文本。
- 一般情况下,面孔和人物可能无法正确生成。
- 模型的自动编码部分是有损的。
建议
关于版权,官方提示这个模型仅用于研究目的,所以商业使用是不被官方允许的:)
插播一句,2024年,我们会时不时的更新一些AIGC相关的研究视频,记得点关注哦~最后祝大家新春快乐,龙年大吉!!!



















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











