







文章目录
1计算机视觉算法基础与 OpenMMLab
CV引入
首先介绍了分类,检测,分割(实例分割语义分割),关键点检测常见CV问题及其区别。CS231N里有讲~
专用目标检测vs通用目标检测:你家的猫和猫
视觉特征:
OpenMMLab

基础知识:

如何理解Batch:
batch就是一批,你作为向量的一组
Batch大小是一个超参数,用于定义在更新内部模型参数之前要处理的样本数。将批处理视为循环迭代一个或多个样本并进行预测。在批处理结束时,将预测与预期输出变量进行比较,并计算误差。从该错误中,更新算法用于改进模型,例如沿误差梯度向下移动。训练数据集可以分为一个或多个Batch。当所有训练样本用于创建一个Batch时,学习算法称为批量梯度下降。当批量是一个样本的大小时,学习算法称为随机梯度下降。当批量大小超过一个样本且小于训练数据集的大小时,学习算法称为小批量梯度下降。
深度学习中的batch怎么理解呢?
CNN:
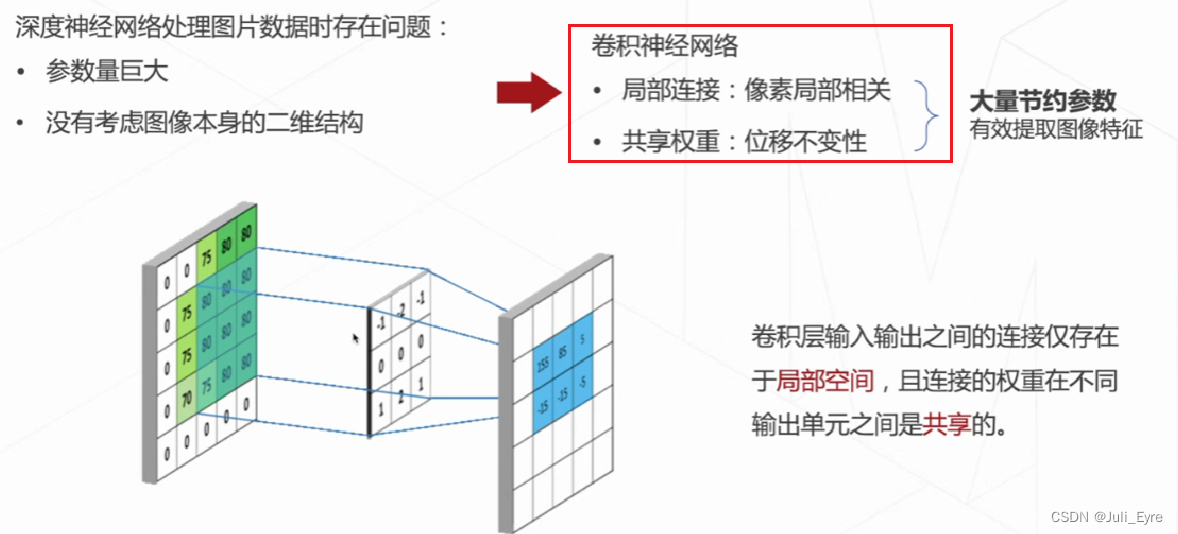
卷积核的通道数和输入图像的通道数相同
输出特征图的通道数和卷积核的个数相同

2 计算机视觉之图像分类算法基础
课程内容
传统方法–设计图像特征
机器学习擅长处理低维,分布相对简单的数据,图像数据维度较高且分布复杂。
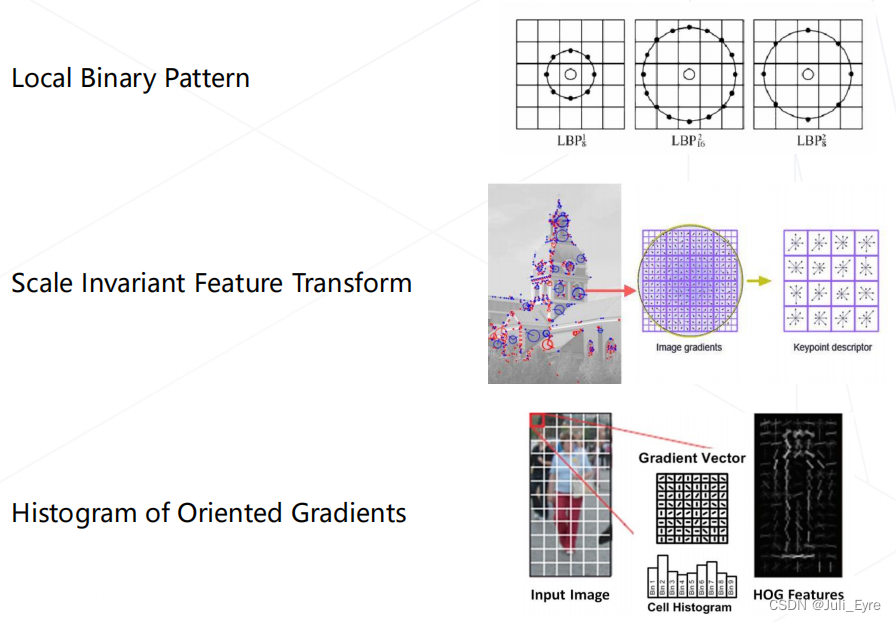
特征工程: 以方向梯度直方图提取特征为例:

特征学习: 学习如何产生适合分类的特征
- CNN 实现一步提取特征
- 多头注意力 实现一步提取特征,如Transformer
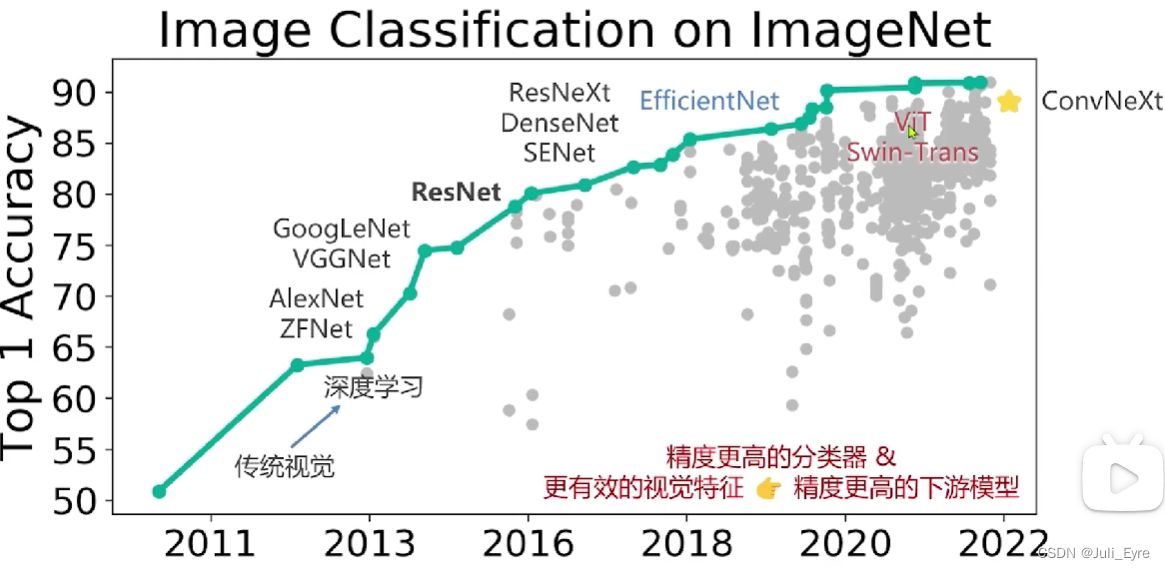
AlexNet VGG 等
VGG:
将大尺寸的卷积拆解为多层3x3卷积:相同的感受野,更少的参数量,更多的层数和表达能力
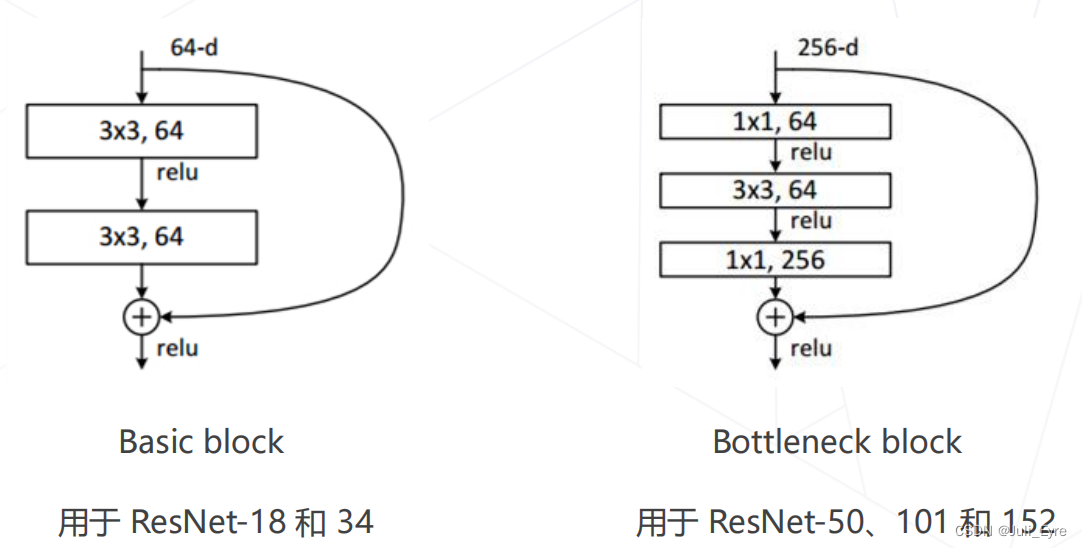
ResNet:
残差链接
基于此的改进:在通道维度引入注意力机制,残差模块的局部改进,使用分组卷积降低参数量
神经网络搜索(2016+)
基本思路:借助强化学习等方法搜索表现最佳的网络
代表工作:NASNet等
Vision/Swin Transformer
即VIT
性能超CNN
ConvNeXt (2022): 将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer
轻量化卷积神经网络
轻量化->过拟合的风险小了->泛化能力强->迁移学习能力强
卷积层的可学习参数包括:卷积核 + 偏置值
卷积的计算量:

so,可考虑的方向:
• 降低通道数 𝐶′ 和 𝐶(平方级别)
• 减小卷积核的尺寸 𝐾(平方级别)
GoogLeNet 使用不同大小的卷积核:并不是所有特征都需要同样大的感受野,在同一层中混合使用不同尺寸的特征可以减少参数量
ResNet 使用1×1卷积压缩通道数:
可分离卷积depthwise separate convolution:
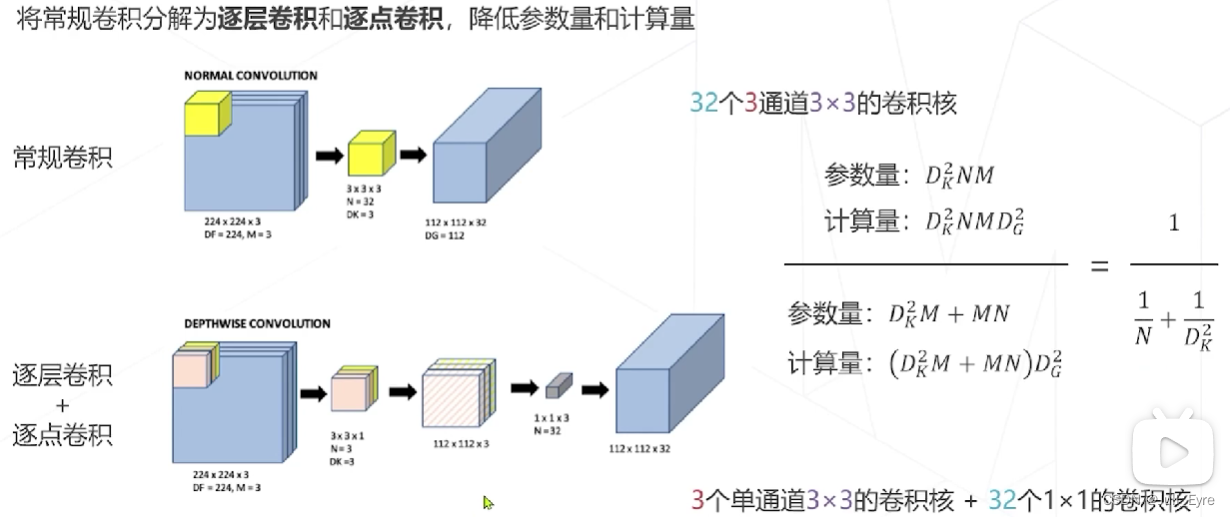
MobileNet V1 使用可分离卷积,只有 4.2M 参数
MobileNet V2/V3 在 V1 的基础上加入了残差模块和 SE 模块
(pointwise是跨通道)
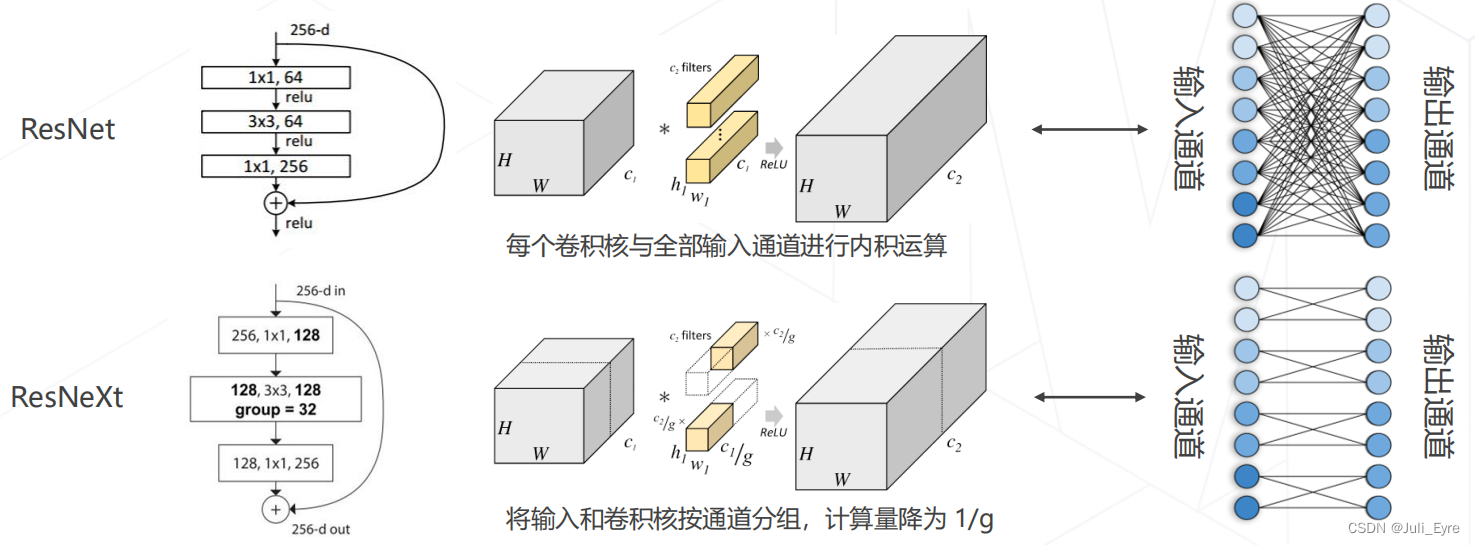
ResNeXt 中的分组卷积
ResNeXt 将 ResNet 的 bottleneck block 中 3×3 的卷积改为分组卷积,降低模型计算量
可分离卷积为分组卷积的特殊情形,组数=通道数
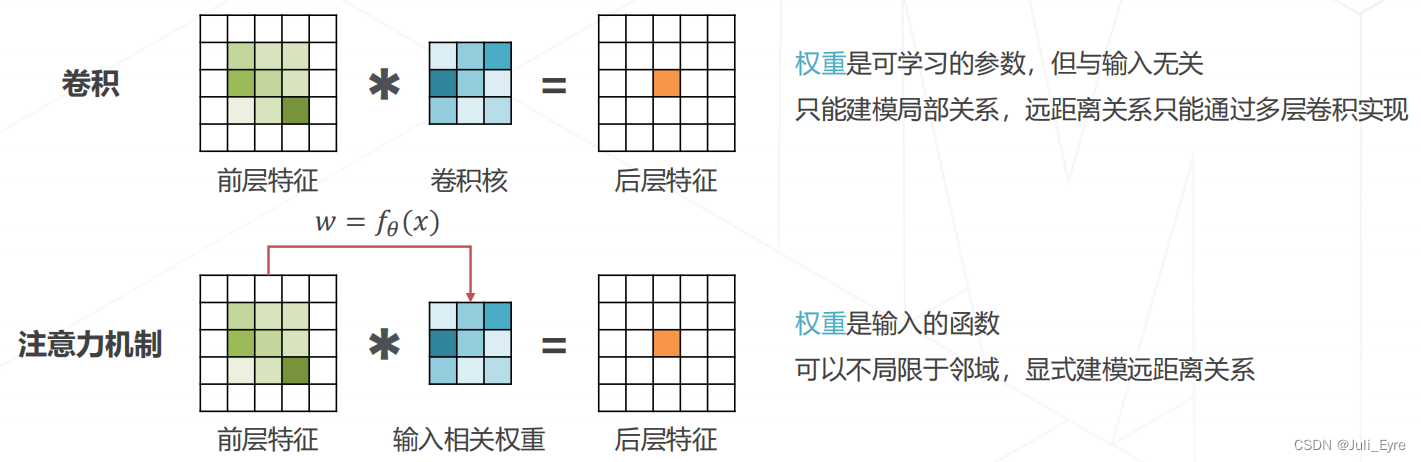
注意力机制 Attention Mechanism
实现层次化特征:(和卷积一样,没有变)
- 后层特征是空间邻域内的前层特征的加权求和
- 权重越大,对应位置的特征就越重要
区别:
实现 Attention:
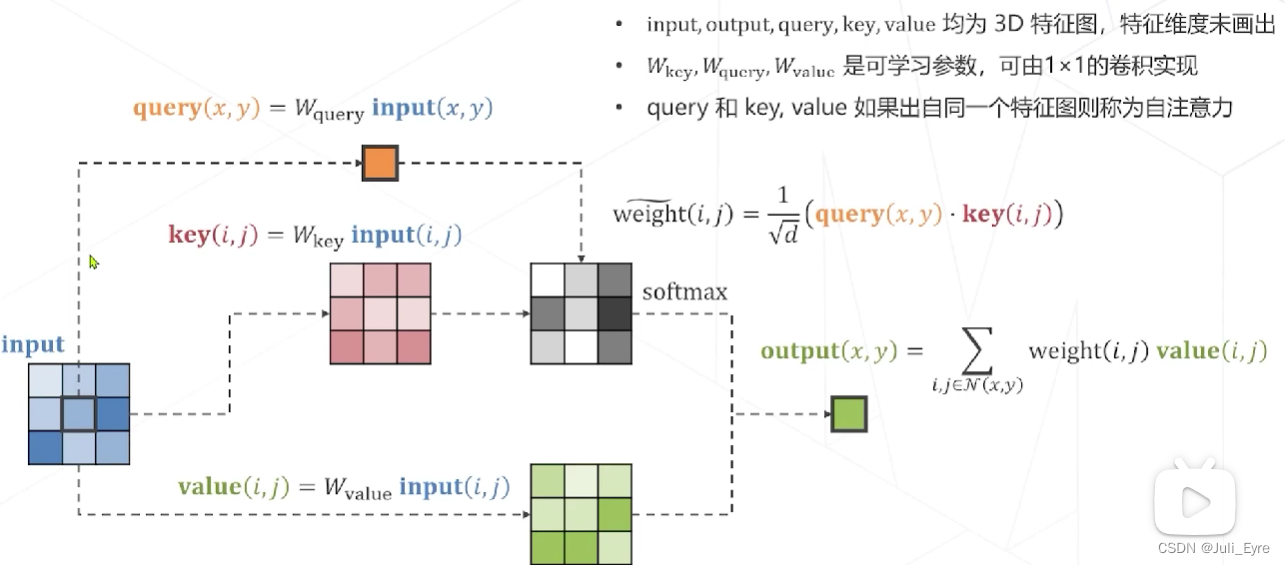
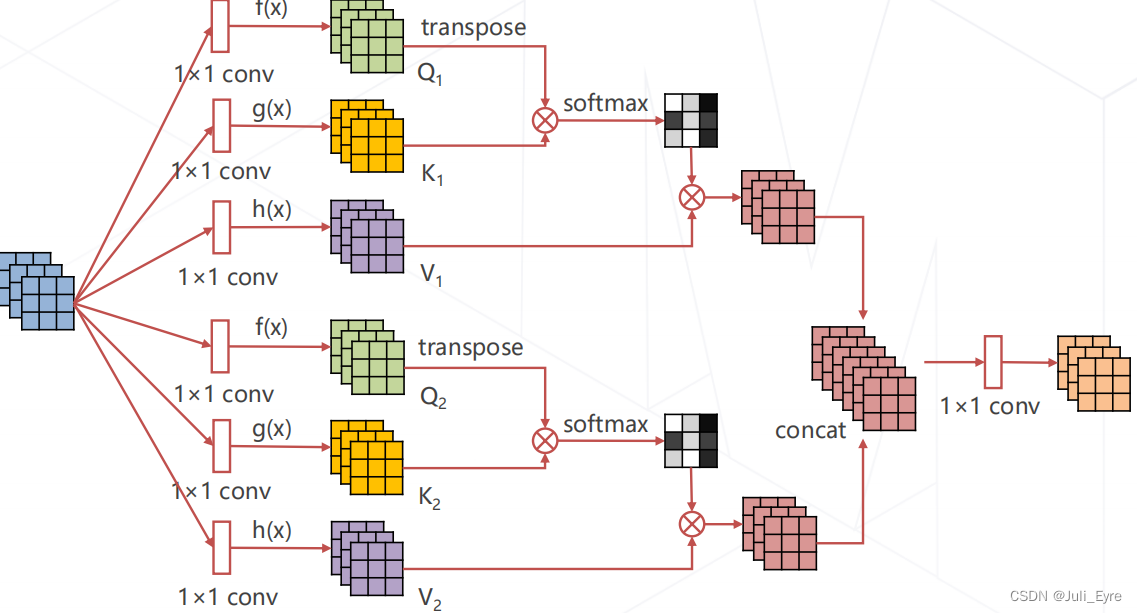
多头注意力 Multi-head (Self-)Attention
使用不同参数的注意力头 产生多组特征,沿通道维度 拼接得到最终特征,Transformer Encoder 的核心模块
Swin Transformer将分类,检测等很多任务的ACC往上推了一个级别
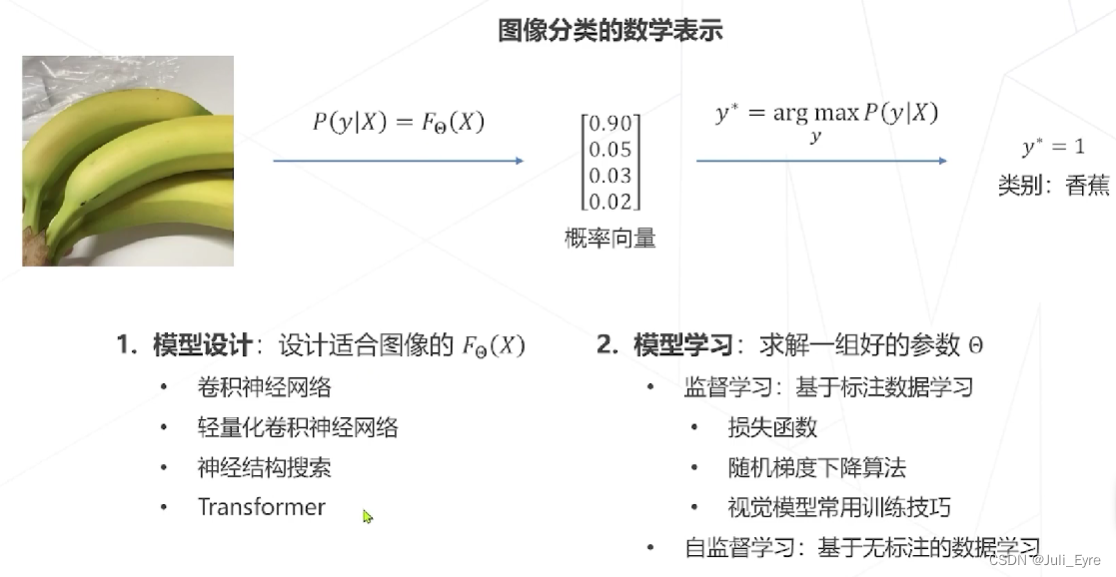
模型学习
目标:确定模型 𝐹 Θ 𝐹_Θ FΘ 的具体形式后,找寻最优参数 Θ ∗ Θ∗ Θ∗ ,使得模型 𝐹 Θ ∗ ( 𝑋 ) 𝐹_{Θ∗} (𝑋) FΘ∗(X) 给出准确的分类结果 𝑃 ( 𝑦 ∣ 𝑋 ) 𝑃( 𝑦 |𝑋) P(y∣X)
范式一:监督学习
互联网数据是海量的 ,但数据的标注是昂贵的
针对神经网络,𝐿 为 Θ 的非凸函数,通常采用随机梯度下降算
pytorch定义linear等层,默认进行了参数初始化
学习率策略:
从头训练可使用较大的学习率,例如 0.01~0.1
微调通常使用较小学习率,例如 0.001~0.01
学习率退火 Annealing
在训练初始阶段使用较大的学习率,损失函数稳定后下降学习率
学习率升温 Warmup
在训练前几轮学习率逐渐上升,直到预设的学习率,以稳定训练的初始阶段
Linear Scaling Rule
经验性结论:针对同一个训练任务,当 batch size 扩大为原来的 𝑘 倍时,学习率也应对应扩大 𝑘 倍
直观理解:这样做可以保证平均每个样本带来的梯度下降步长相同

实践中,假设预训练模型使用 lr=0.1,8卡数据并行训练,如果希望用1卡复现实验,lr 应设置为 0.0125(batch size降为了1/8)
batch size越大收敛越快
自适应梯度算法: 不同的参数需要不同的学习率,根据梯度的历史幅度自动调整学习率
正则化与权重衰减 Weight Decay:
衰减的原因是正则化

丢弃层 Dropout
训练时随机丢弃一些连接,破坏神经元之间的关联,鼓励学习独立的特征
推理时使用全部连接
常用于全连接层,通常不与 BN 混用
数据增强
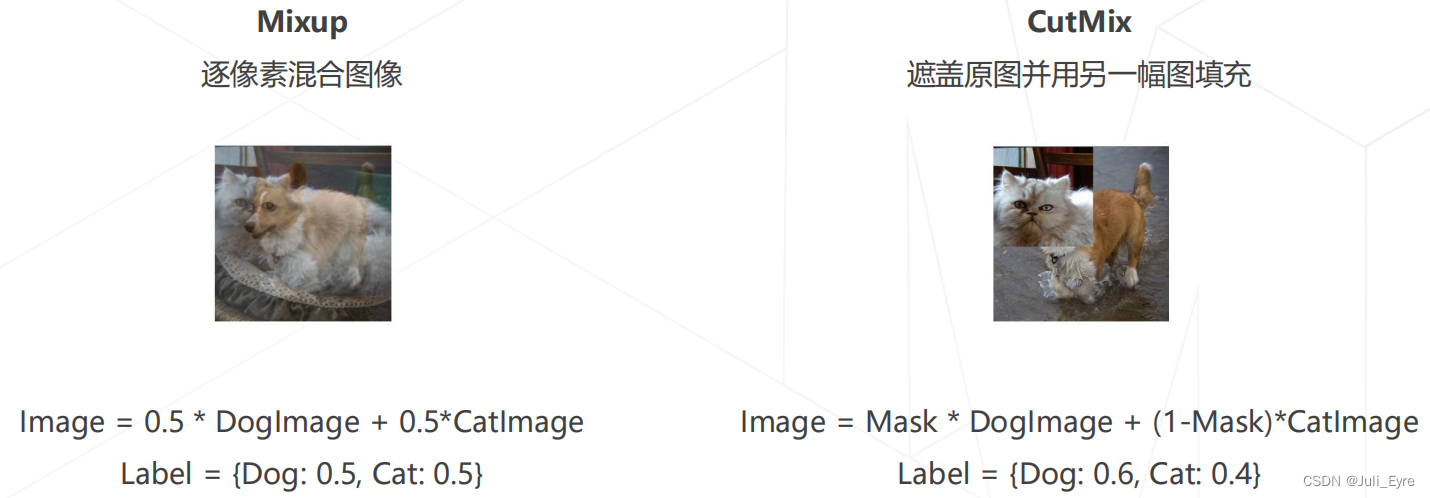
组合增强方法:数据增强操作可以组合,生成变化更复杂的图像

组合图像 Mixup & CutMix
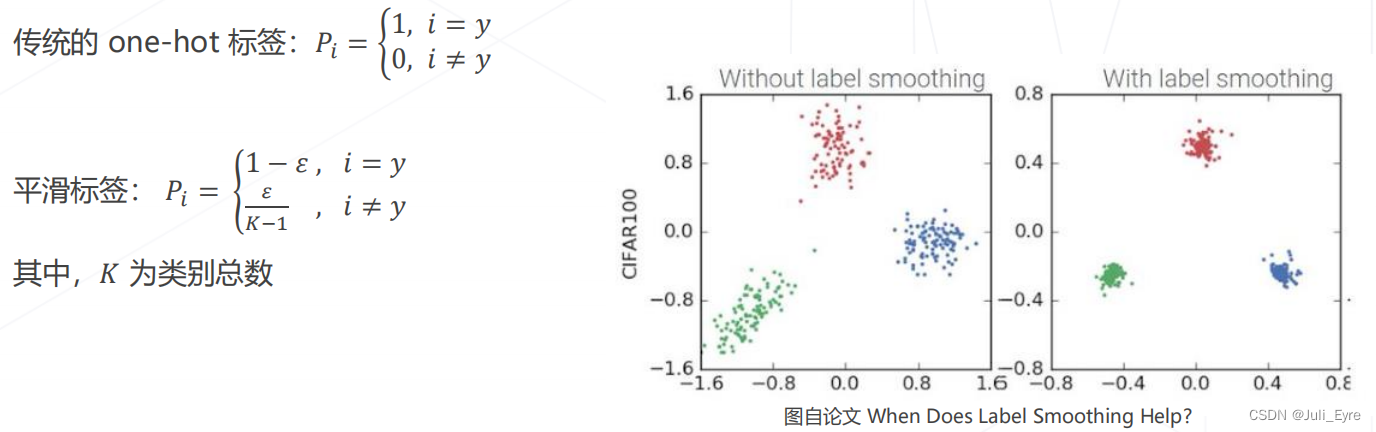
标签平滑 Label Smoothing:
动机:类别标注可能错误或不准确,让模型最大限度拟合标注类别可能会有碍于泛化性
做法:引入平滑参数 𝜀,降低标签的"自信程度
范式二:自监督学习
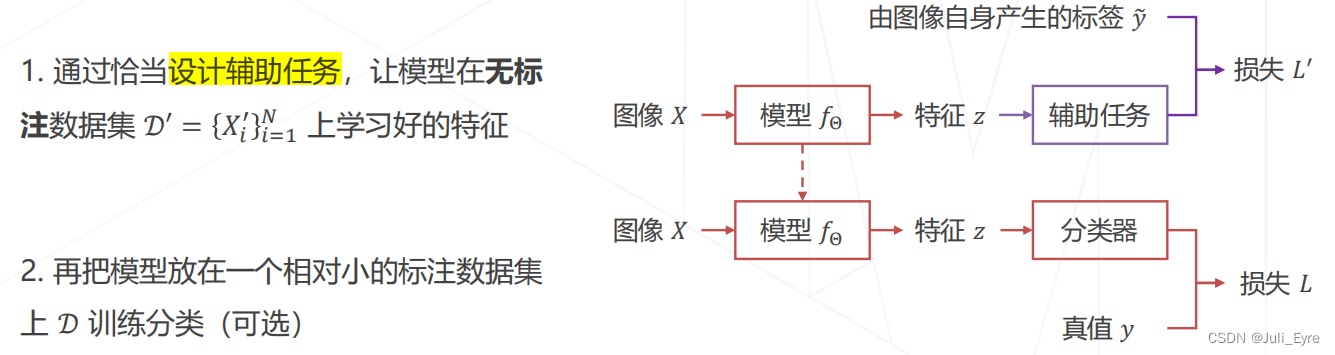
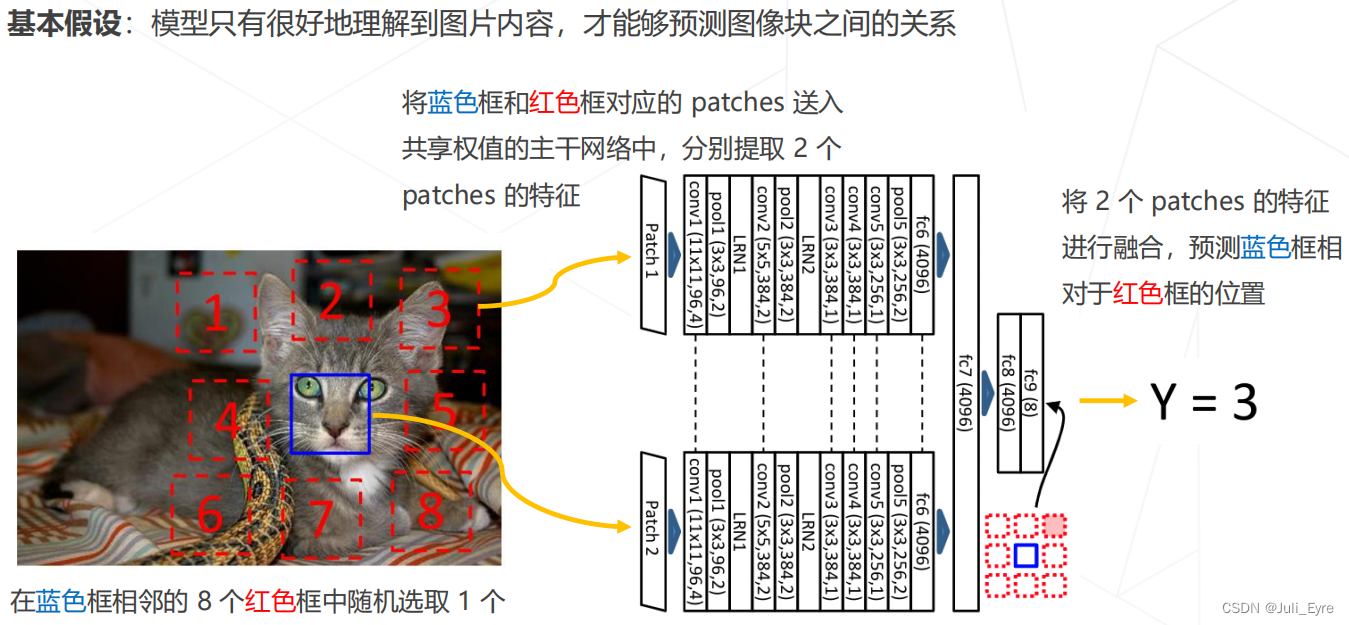
基于代理任务: 比如用预测颜色的任务产生标签(能预测就学习到了图像的一定特征),然后拿这些特征做分类
如Relative Location (ICCV 2015)
基于对比学习: SimCLR (ICML 2020)
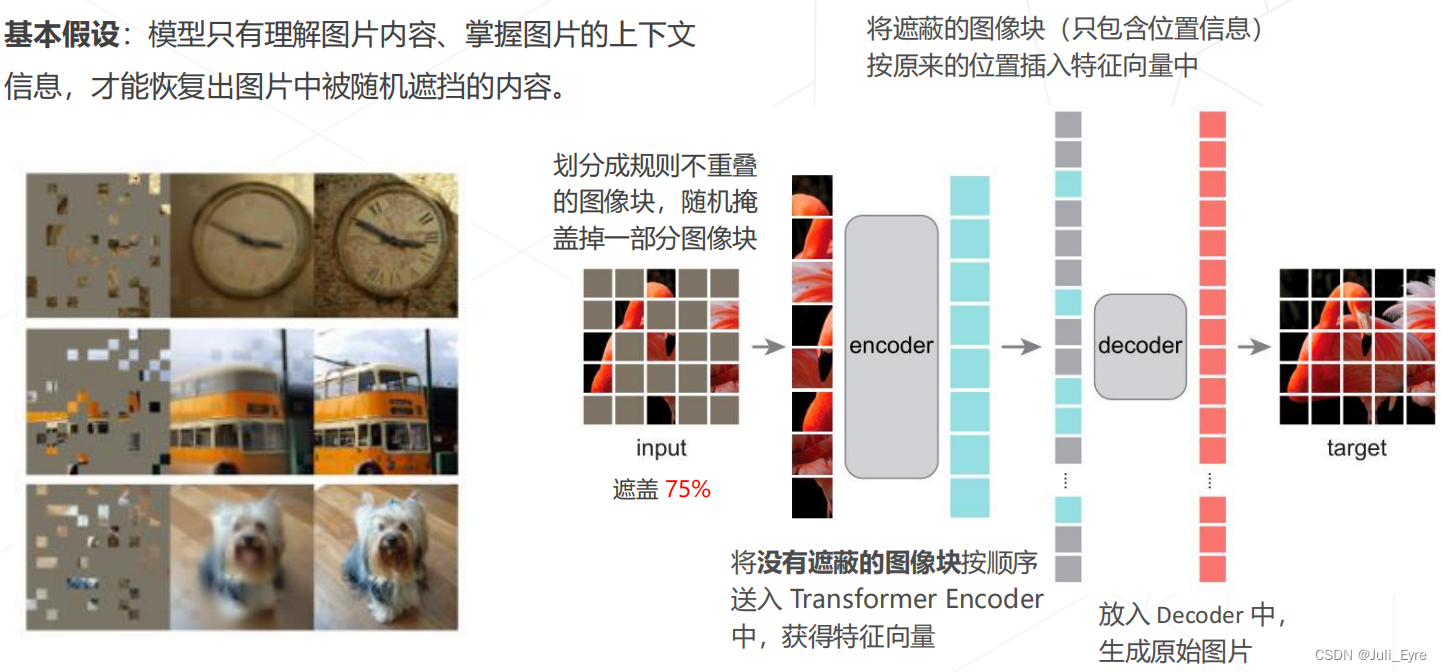
基于掩码学习
Masked autoencoders (MAE, CVPR 2022)














 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









