






同步与异步
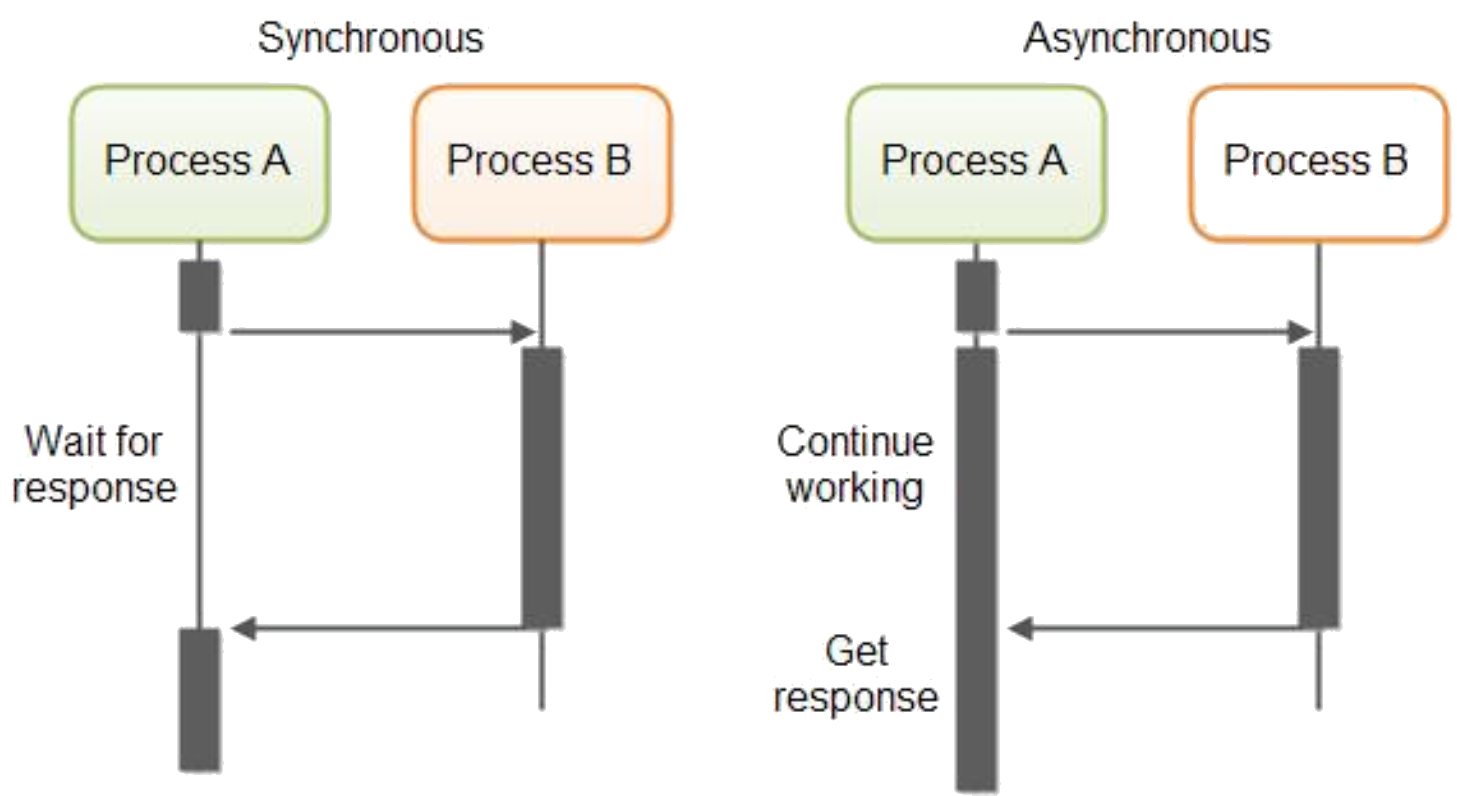
同步与异步的重点是在消息通知的方式上,也就是调用结果通知的方式上。同步方式是当一个同步调用发出后,调用者要一直等待调用结果的通知后,才能进行后续的执行。异步方式是当一个异步调用发出后,调用者不能立即得到调用结果的返回。异步调用要想获得结果一般有两种方式:主动轮询异步调用的结果、被调用方通过回调callback来通知调用方调用结果。
阻塞与非阻塞
阻塞与非阻塞的重点在于进程或线程等待消息时的行为,也就是在等待消息的时候,当前进程或线程是挂起状态还是非挂起状态。阻塞方式的阻塞调用在发出后,在消息返回之前,当前线程或进程是会被挂起的,直到有消息返回,当前进程或线程才会被激活。非阻塞方式的非阻塞消息在发出后,不会阻塞当前进程或线程,而会立即返回。
简单来说,同步与异步的重点在于消息通知的方式,阻塞与非阻塞的重点在于等待消息时候的行为。因此也就有了4种组合:同步阻塞、同步非阻塞、异步阻塞、异步非阻塞。
阻塞IO与非阻塞IO
一个IO操作实际上是分成两个步骤:
- 发起IO请求
阻塞IO和非阻塞IO的区别在于第一步,发起IO请求是否会被阻塞,如果阻塞直到完成,那就是传统的阻塞IO,否则就是非阻塞IO。 - 实际的IO操作
同步IO与异步IO的区别在于第二步是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO,因此阻塞IO、非阻塞IO、IO复用、信号驱动IO都是同步IO。如果不阻塞,而是操作系统帮助做完IO操作再将结果返回,那它就是异步IO。
多进程和多线程同步阻塞
最早的服务器程序都是通过多进程或多线程来解决并发IO的问题,进程模型出现的最早,从UNIX系统诞生之初就有了进程的概念。最早的服务器端程序一般都是Accept一个客户端连接就创建一个进程,然后子进程进入循环同步阻塞地与客户端连接交互,收发处理数据。

多线程模式出现要晚一些,线程与进程相比更轻量,而且线程之间是共享内存堆栈的,所以不同的线程之间交互非常容易实现。比如,聊天室程序中客户端连接之间可以交互,玩家可以任意的向其他人发消息。用多线程模型实现非常简单,线程中可以直接向某个客户端连接发送数据。如果使用多进程模式就需要使用到管道、消息队列、共享内存等进程间通信IPC的复杂技术才能实现。
多进程和多线程模型的操作流程
<?php
$address = "tcp://0.0.0.0:8000";
$svr = stream_socket_server($address, $errno, $errstr) or die("create server failed");
while(true)
{
$connect = stream_socket_accept($svr);
if(pcntl_fork() == 0)
{
$request = fread($connect);
fwrite($response);
fclose($connect);
exit(0);
}
}
- 创建一个
socket并绑定服务器端口,然后监听端口。 - 进入
while循环,阻塞在accept操作上,等待客户端连接进入。此时程序会进入休眠状态,直到有新客户端发起connect连接到服务器,操作系统才会唤醒此进程。 - 主进程在多进程模型下通过
fork创建子进程,多线程模型下可以使用pthread_create创建子线程。 - 子进程创建成功后进入
while循环,阻塞在recv调用上,等待客户端向服务器发送数据。当服务器收到数据后服务器程序进行处理,然后send向客户端发送响应。长连接的服务会持续与客户端交互,而短连接服务一般在收到响应后就会close。 - 当客户端连接关闭时,子进程退出并销毁所有资源,主进程会回收掉此子进程。
多进程和多进程模型的最大问题在于,进程和线程的创建和销毁开销很大,因此美哟u办法应用在非常繁忙的服务器程序上,对应的改进版也就是经典的Leader-Follower模型。
Leader-Follower模型
Leader-Follower模型的特点是程序启动后会创建n个进程,每个子进程进入Accept,等待新的连接的进入。当客户端连接到服务器时,其中一个子进程会被唤醒,开始处理客户端请求,并且不再接收新的TCP连接。当此连接关闭时,子进程会释放并重新进入Accept并参与处理新的连接。
<?php
$address = "tcp://0.0.0.0:8000";
$svr = stream_socket_server($address, $errno, $errmsg) or die("create server failed");
for($i=0; $i<32; $i++)
{
if(pcntl_fork() == 0)
{
while(true)
{
$connect = stream_socket_accept($svr);
if($connect == false)
{
continue;
}
$request = fread($connect);
fwrite($response);
fclose($connect);
}
exit(0);
}
}
Leader-Follower模型的优势在于完全可以复用进程,没有额外消耗,性能非常好。很多常见的服务器程序都是基于此模型的,如Apache、PHP-FPM。
当然,多进程模型也是存在缺陷的:
- 多线程模型严重依赖进程的数量解决并发问题,一个客户端连接就需要占用一个进程,工作进程的数量有多少,并发处理能力就有多少,但是操作系统可以创建的进程数量是有限的。
- 多进程模型启动的大量进程会带来额外的进程调度消耗,数百个进程时可能进程上下文切换调度消耗占CPU不到1%可以忽略不计,如果启动数千甚至数万个进程,消耗会直线上升。调度消耗可能占到CPU的100%。
- 在即时通讯程序中,单台服务器要同时维持上万、数十万、上百万的链接时,多进程模型就无法胜任了。
- 在Web服务器启动100个进程,如果一个请求消耗100毫秒,100个进程可以提供1000QPS,这样的处理能力还可以。但是如果请求内要调用外网HTTP接口,如QQ、微信、微博登录时,耗时会很长,一个请求如果需要10秒,那么一个进程1秒就只能处理0.1个请求,100个进程只能达到10QPS,这样的处理能力就太差了。
那么,有没有一种技术可以在一个进程内处理所有并发IO呢?答案是有,也就是IO复用技术。
IO复用
IO复用的历史和多进程一样长,Linux很早就提供了select系统调用,可以在一个进程内维护1024个连接,后来加入poll系统调用,poll做了一系列改进后解决了1024个连接的限制问题,可以维持任意数量的连接。但是select和poll存在一个问题是,它们需要循环检测连接是否有事件。这样问题就来了,如果服务器有100w个连接,在某一时间只有一个连接是向服务器发送了数据,select/poll就需要做100w次循环,而其中只会有1次命中,剩下99w9999次都是无效的,白白浪费CPU时间片资源。
直到Linux2.6内核开始提供新的epoll系统调用,可以维持无限数量的连接,而且无需轮询,这才真正解决了C10K问题。现在各种高并发异步IO的服务器程序都是基于epoll实现的,如Nginx、Node.js、Erlang、Golnag。像Node.js这样单进程单线程的程序,都可以维持超过100wTCP连接,这全部都要归功于epoll技术。
IO复用异步非阻塞
IO复用异步非阻塞使用经典的Reactor反应堆模型,它本身不处理任何数据收发,只是监视一个socket句柄的事件变化。
Reactor模型可以与多进程、多线程结合使用,即可以实现异步非阻塞IO,又可以利用到多核。目前流程的异步服务器程序都是使用这种方式:
- Nginx:多进程Reactor
- Nginx+Lua:多进程Reactor+协程
- Golang:单线程Rector+多线程协程
- Swoole:多线程Reactor+多进程Worker
协程是什么
协程从底层技术角度看实际上还是异步IO Reactor模型,应用层自行实现了任务调度,借助于Reactor切换各个当前执行的用户态线程,但用户代码中完全感知不到Reactor的存在。
Apache面对高并发为什么很无力
Apache处理一个请求是同步阻塞的模式,每到达一个请求,Apache都会去fork一个子进程去处理这个请求,直到这个请求处理完毕。面对低并发,这种模式没有什么缺点。但对于高并发就是这种模式的缺陷了。
因为一个客户端占用一个进程,也就是说进程数量有多少并发能力就有多少,但操作系统可以创建的进程数量是有限的。其次,多进程存在进程间的切换问题,进程间的切换调度势必造成CPU的额外消耗。当进程数量达到成千上万的时候,进程间的切换就会占用CPU大部分的时间片,而真正进程的执行反而占用了CPU的一小部分,这就得不偿失了。
例如:在即时通讯场景中,单台服务器可能要维持数十万的连接,那么就要启动数十万的进程来维持,这显然时不可能的。另外,在调用外部HTTP接口时,假设Apache启动100个进程来处理请求,每个请求消耗100毫秒,那么这100个进程能提供1000QPS。但是,在调用HTTP接口时,如QQ登录、微博登录,一般耗时较长,假设一个请求消耗10秒,也就是1个进程1秒处理0.1个请求,那么100个进程只能达到10QPS,这样的处理能力就未免太差了。
综上所述,由于Apache采用的是同步阻塞的多进程模式,在面对高并发场景时是无能为力的。
Nginx是如何处理高并发的
传统的服务器模型就是这样,因为同步阻塞的多进程模型无法面对高并发,那么有没有一种方式可以在一个进程中处理所有的并发I/O呢?当然是有的,这也就是I/O复用技术。
所谓的I/O复用也就是多个I/O可以复用一个进程,由于同步阻塞的方式不适合处理高并发,如果是非阻塞的方式呢?采用非阻塞的模式,当一个连接过来的时候,由于不阻塞住所以一个进程可以同时处理多个连接。
例如:一个进程接收1w个链接,这个进程每次从头到尾的询问每个连接:“你有I/O事件没?有的话就交给我来处理,没有的话我一会儿再来问你”。然后进程就一直从头到尾的问这1w个连接。如果这1w个连接都没有I/O事件,就会造成CPU的空转,如此效率很低。
那么能不能引入一个代理,这个代理可以同时观察许多I/O流事件呢?当没有I/O事件的时候,这个进程处于阻塞状态,当有I/O事件的时候,这个代理就去通知进程醒来呢?于是,早期就出现了两个代理:select和poll。
select和poll代理的原理是:当连接有I/O流事件产生的时候,就会去唤醒进程去处理。select和poll的区别在于select只能观察1024个链接,而poll可以观察无限个连接。
但是进程并不知道是哪个连接产生的I/O流事件,于是进程就挨个去问:“请问,是你有事情要处理吗?”,当问了9999遍后发现原来是第1w个进程有事情要处理。那么前面这9999次就白问了,白白浪费了宝贵的CPU时间片。由于select和poll不知道哪个连接有I/O流事件要处理,所以性能也不是很好。
如果存在一个代理,每次都能够知道哪个连接有I/O流事件,也就可以避免CPU无意义的空转了。于是,epoll出现了。epoll代理的原理是:当连接有I/O流事件产生的时候,epoll就会去告诉进程哪个连接有I/O流事件产生,然后进程就去处理这个进程。有了epoll,理论上一个进程就可以无限数量的连接,而且无需轮询,真正解决了C10K的问题。
Nginx是基于epoll的异步非阻塞的服务器程序,可以轻松的处理百万级并发连接。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









