







因为社交媒体课程的作业,阅读了发表在2018年INFOCOM上的一篇有关事件推荐的工作。

摘要
基于事件的社交网络(EBSNs)是新兴的用户社交平台,能够线上发布活动,吸引用户线下参加。事件的具体内容在事件推荐中发挥着重要作用。然而,因为聚焦于利用从事件角度的内容信息,现存于事件推荐系统的基于内容的方法不能完全表示每个用户对于事件的偏好。同时方法中常用的词袋模型,只能捕捉词频,忽略了词序以及句子的结构。在这篇文章中,我们转变聚焦于事件的视角,关注用户视角,针对事件推荐提出了一个深度用户建模的框架(Deep User Modeling framework for
Event Recommendation (DUMER))。通过利用用户已经参加的事件的内容信息来捕捉用户的偏好。具体来说,我们利用CNN和词嵌入深入挖掘用户感兴趣的事件的内容信息,并为每一个用户构建用户潜在模型。然后我们将用户潜在模型融合到概率矩阵分解模型(PMF)中提升推荐准确性。我们在一个典型的EBSN——meetup.com中抓取的真实数据集上进行了实验。实验结果表明DUMER表现优于benchmarks。
概念
- Event-based social network
- Event recommendation
- Event 事件,活动
INTRODUCTION
Event-based social networks,是新兴的社交平台。用户可以线上发布活动吸引本地其他用户线下参与活动。这种线上社交网络和线下社交互动的特殊组合为用户建立和加强社会关系提供一种新方法,在近年来吸引了成百上千的用户并使得EBSN获得了发展势头。依据Meetup中的统计,平台中有来自180个国家的约3千万注册用户,并每月组织超过58万活动。
由于EBSN中的事件数量非常庞大,需要个性化的事件推荐来解决信息过载问题并向用户推荐最感兴趣的事件。虽然推荐系统已经广泛研究,但是相较于传统推荐,事件推荐的独特性质使其更具有挑战性。第一个独特性质是EBSN中的每个事件生命周期较短,需要系统在活动开始前就进行了该活动的推荐。这与传统推荐中的item不同,这些item不需要考虑到时间段信息。更重要的是,将要在不久的将来中举办的全新的活动,可能只有一点或者没有历史的参与信息,用户对于其的反馈只能通过活动结束获得。换句话说,在传统的推荐中经常使用的用户反馈信息,对于EBSN是无效的。因此,这种特殊的冷启动问题让活动推进啊在EBSN中很有挑战性,传统的推荐算法无法直接应用于EBSN中的事件推荐。
(用户角度)目前开发了一些活动推荐系统来推荐用户最感兴趣的活动。在活动推荐中,活动的内容发挥着重要作用,因为其包含很多重要信息,比如标题或者位置。基于其重要性,现有的事件推荐系统普遍采用基于内容的方法来计算事件相似度得分。然而,由于EBSN中新活动冷启动性质,基于内容的方法是实际上对于活动推荐并不适用有效。此外,和活动短暂的生命周期相比,EBSN中的用户有更长的活动时间并且一般会参加很多活动。这促使我们来探索用户的兴趣而不是计算活动之间的相似度。基于此,我们认为从用户的角度利用内容信息来挖掘用户对于活动的偏好,相较于利用新活动和旧活动的相似性来进行推荐是更合理的。
(deep learning方法)词袋模型是一种常见的文本表示模型,应用于现存的推荐系统中。然而,这种模型无法完全捕获内容中的文本信息,因为它只能表示词频,忽略了内容中的句子结构和语序。近年来,深度学习的方法,例如RNN和CNN,展示出从文本内容中学习有效的特征表示的优秀潜力。在本文中,我们利用CNN来从用户视角深入挖掘活动的文本信息,并将它们融合到概率矩阵分解框架中完成活动推荐。
(总的方法)在这篇文章中,我们转变聚焦于事件的视角,关注用户视角,针对事件推荐提出了一个深度用户建模的框架(Deep User Modeling framework for Event Recommendation (DUMER))。通过利用用户已经参加的事件的内容信息来捕捉用户的偏好。我们利用CNN和词嵌入深入挖掘用户感兴趣的事件的内容信息,并为每一个用户构建用户潜在模型。然后我们将用户潜在模型融合到概率矩阵分解模型(PMF)中提升推荐准确性。请注意,ConvMF也将CNN整合到概率矩阵分解种俩捕捉文档的文本信息并增强预测准确性。但EBSN中传统推荐不同的特殊性质使得ConvMF不能直接应用在活动推荐中。再者,和从活动的角度挖掘事件文档不同,我们的工作将视角转化为用户角度然后利用CNN在用户内容中来更好的捕捉用户偏好。
贡献如下:
- 我们利用用户角度的活动内容,通过深入挖掘用户所参加的活动的文本信息,描述了用户潜在偏好。
- 我们提出了DUMER框架,将CNN融合进PMF中向用户准确推荐新活动。具体地说,我们应用CNN来提取用户内容的高级别特征,形成用户的潜在向量,然后将用户向量融合进PMF模型中来预测用户对于一个活动的偏好。(CNN用来提取用户偏好,user latent factor)
- 实验验证模型的有效性。
PROBLEM FORMULATION
主要是对活动推荐这一任务进行问题定义。
符号说明:
- E u = { e 1 , e 2 , … , e m } E_{u} =\left \{ e_1,e_2,\dots,e_m \right \} Eu={e1,e2,…,em},用于u参与过的活动的序列
- E ^ = { e 1 ^ , e 2 ^ , … , e φ ^ } \hat{E} = \left \{\hat{e_1},\hat{e_2},\dots,\hat{e_\varphi } \right \} E^={e1^,e2^,…,eφ^}, 还没有发生的活动,可以看作推荐候选集
- RSVP history构成的矩阵,相当于RS中的交互矩阵
- The number of users is K, the number of events is M.
- A A A是RSVP矩阵。 A i j A_{ij} Aij=1,当用户i参加了活动j。attendance matrix
- user latent factor, U ∈ R K ∗ D U \in \mathbb{R}^{K*D} U∈RK∗D
- event latent factor, V ∈ R D ∗ M V \in \mathbb{R}^{D*M} V∈RD∗M
- D D D 是隐向量的维度
问题建模:后验概率最大化问题
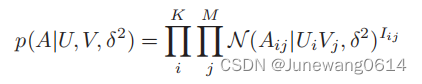
这里有概率矩阵分解的一些假设,比如
A
i
j
A_{ij}
Aij服从正态分布。用户i和将要发生的活动j的
A
i
j
A_{ij}
Aij,即象征着用户i对事件j的偏好。
Method
high-level overview
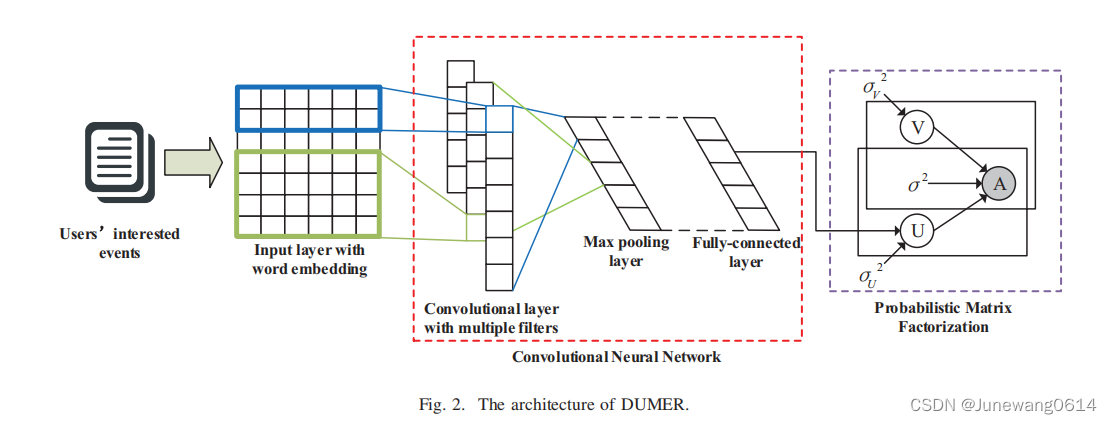
- 利用CNN编码用户的感兴趣的活动的上下文信息,将其作为用户的潜在因素表示。
- 在PMF中利用CNN获取的用户潜在表示,进行矩阵A的近似
- 训练好的模型用于生成预测出席矩阵A,选择TOP-N作为向用户推荐的活动。
word embedding
采用word embedding的原因是,用户感兴趣的活动,不是和用户参加过的活动的描述表面上相似的活动,而是含义上相似的活动。而词袋模型只能捕捉表面相似的关系,所以采用word embedding来获得对活动内容更好的描述。
采用的Glove模型,每篇描述对应一个特征矩阵[seq_len,embedding_size],用 X i X_{i} Xi表示
CNN
文中利用CNN来深入挖掘用户感兴趣的活动的上下文信息,特别是从用户的角度描述用户对这些活动的偏好。
-
the convolutional layer
基于滑动窗口的特征提取
实验中卷积核总数为300,滑动窗口长度分别为3,4,5.每种各100个。这样获得300个长度不同的卷积特征vector。
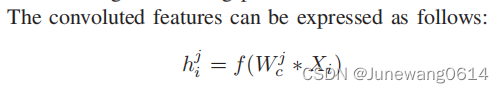
-
the pooling layer
将变长的卷积特征vector固定大小,并为了降维。采用最大池化的方法。
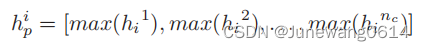
-
the fully-connected layer
将最大池化的输出过一层多层感知机,获得最终的用户特征向量。
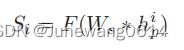
PMF
PMF部分主要参考博文学习
PMF主要有两点假设:
- 观测噪声服从零均值的高斯分布
E ∼ N ( 0 , σ 2 ) E \sim N(0,\sigma^{2}) E∼N(0,σ2), σ \sigma σ是人为设定的。
从而延伸得到:
R ∼ N ( R ^ , σ 2 ) R \sim N(\hat{R},\sigma^{2}) R∼N(R^,σ2)- 用户潜在特征矩阵U和物品潜在特征矩阵V服从一个均值为0的高斯先验
p ( U ∣ σ u ) ∼ ∏ u = 1 N N ( 0 , σ u 2 I ) p(U|\sigma_{u}) \sim \prod_{u=1}^{N}\mathrm{N}(0,\sigma_{u}^2\mathrm{I}) p(U∣σu)∼∏u=1NN(0,σu2I)
p ( U ∣ σ v ) ∼ ∏ v = 1 M N ( 0 , σ v 2 I ) p(U|\sigma_{v}) \sim \prod_{v=1}^{M}\mathrm{N}(0,\sigma_{v}^2\mathrm{I}) p(U∣σv)∼∏v=1MN(0,σv2I)
由假设1可以获得以下关系:
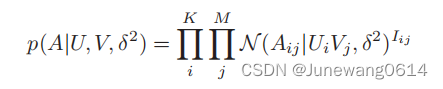
在本文中,不同的是user的潜在向量不单单是一个均值为0的高斯先验。而是通过CNN提取上下文信息获得,这样的话也采用噪声服从均值为0的高斯先验的思想,将用户的潜在特征表示为CNN提取的向量+高斯噪声。用公式表示关系则变成如下所示:
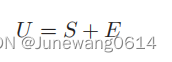
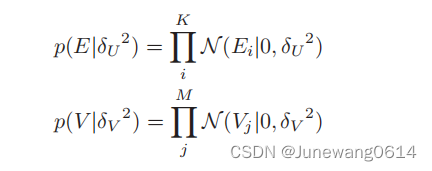
同样的,目标函数也由原先的
min
U
,
V
[
1
2
I
∥
R
−
U
V
∥
+
λ
V
2
∥
V
∥
+
λ
U
2
∥
U
∥
]
\min_{U,V} \left [ \frac{1}{2}I\left \| R-UV \right \| +\frac{\lambda _{V}}{2}\left \|V \right \| + \frac{\lambda _{U}}{2}\left \|U \right \| \right ]
U,Vmin[21I∥R−UV∥+2λV∥V∥+2λU∥U∥]
变为
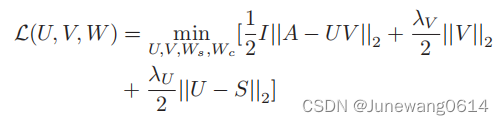
主要是用户潜在因素U的目标的不同。
优化
- U,V通过坐标下降算法进行优化,其更新公式分别为:
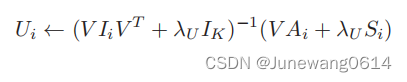
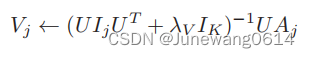
- W s W_s Ws, W c W_c Wc使用梯度下降进行优化。
- 推理阶段,对于得分的计算可以表示为:
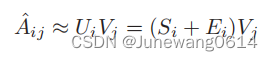
以上是整篇论文的所做的工作。















 1972
1972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









