










一、配置简介
windows10 + GTX 1050Ti 4GB显存
cuda 11.5
onnxruntime-gpu 1.11.1
visual studio 2019
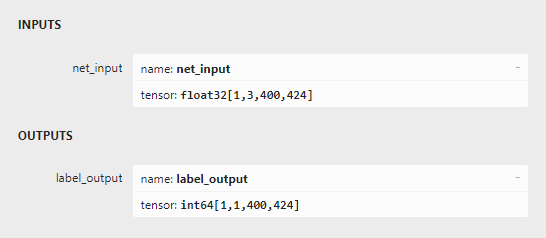
.onnx模型,input为float32的{1,3,400,424};output为int64的{1,1,400,424}
二、流程梳理
1.python下生成pytorch的模型.pth,并基于.pth模型进行推理
2.python下依据模型推理实现从.pth转向.onnx
3.python下基于.onnx进行推理,与1中的结果进行比较
4.基于已知的输入输出,在C++下部署.onnx模型,进行推理,与3中的结果进行比较
三、代码(仅列出C++下的部署程序示例)
class ModelInfo {
public:
ModelInfo() {};
~ModelInfo() {};
public:
size_t num_input_nodes; //输入节点的数量
std::vector<const char*> input_node_names; //输入节点的名称
std::vector<std::vector<int64_t>> input_node_dims; //输入节点的维度
std::vector<ONNXTensorElementDataType> input_types; //输入节点的类型
std::vector<OrtValue*> input_tensors; //输入节点的tensor
size_t num_output_nodes; //输出节点的数量
std::vector<const char*> output_node_names; //输出节点的名称
std::vector<std::vector<int64_t>> output_node_dims; //输出节点的维度
std::vector<ONNXTensorElementDataType> output_types; //输出节点的类型
std::vector<OrtValue*> output_tensors; //输出节点的tensor
public:
inline void InitialInput() {
this->input_node_names.resize(this->num_input_nodes);
this->input_node_dims.resize(this->num_input_nodes);
this->input_types.resize(this->num_input_nodes);
this->input_tensors.resize(this->num_input_nodes);
}
inline void InitialOutput() {
this->output_node_names.resize(this->num_output_nodes);
this->output_node_dims.resize(this->num_output_nodes);
this->output_types.resize(this->num_output_nodes);
this->output_tensors.resize(this->num_output_nodes);
}
};
bool CheckStatus(const OrtApi* g_ort, OrtStatus* status) {
if (status != nullptr) {
const char* msg = g_ort->GetErrorMessage(status);
std::cerr << msg << std::endl;
g_ort->ReleaseStatus(status);
throw Ort::Exception(msg, OrtErrorCode::ORT_EP_FAIL);
}
return true;
}
void GetModelInputInfo(const OrtApi* g_ort, OrtSession* session, OrtAllocator* allocator, ModelInfo* model_info) {
//**********输入信息**********//
CheckStatus(g_ort, g_ort->SessionGetInputCount(session, &model_info->num_input_nodes)); // Get input count for a session. 从会话中获取输入个数
model_info->InitialInput();
for (size_t i = 0; i < model_info->num_input_nodes; i++) {
// Get input node names
char* input_name;
CheckStatus(g_ort, g_ort->SessionGetInputName(session, i, allocator, &input_name)); // Get input name. 获取当前输入名称
model_info->input_node_names[i] = input_name;
// Get input tensor info
OrtTypeInfo* typeinfo;
CheckStatus(g_ort, g_ort->SessionGetInputTypeInfo(session, i, &typeinfo)); // Get input type information. 获取当前输入的类型信息
const OrtTensorTypeAndShapeInfo* tensor_info;
CheckStatus(g_ort, g_ort->CastTypeInfoToTensorInfo(typeinfo, &tensor_info)); // Get OrtTensorTypeAndShapeInfo from an OrtTypeInfo. 类型转换OrtTypeInfo->OrtTensorTypeAndShapeInfo
// Get input tensor type
ONNXTensorElementDataType type;
CheckStatus(g_ort, g_ort->GetTensorElementType(tensor_info, &type)); // Get element type in OrtTensorTypeAndShapeInfo. 从tensor info中获取元素类型
model_info->input_types[i] = type;
// Get input shapes/dims
size_t num_dims;
CheckStatus(g_ort, g_ort->GetDimensionsCount(tensor_info, &num_dims)); // Get dimension count in OrtTensorTypeAndShapeInfo. 从tensor info中获取维度数量
model_info->input_node_dims[i].resize(num_dims);
CheckStatus(g_ort, g_ort->GetDimensions(tensor_info, model_info->input_node_dims[i].data(), num_dims)); // Get dimensions in OrtTensorTypeAndShapeInfo. 从tensor info中获取维度
size_t tensor_size;
CheckStatus(g_ort, g_ort->GetTensorShapeElementCount(tensor_info, &tensor_size)); // Get total number of elements in a tensor shape from an OrtTensorTypeAndShapeInfo. 从tensor info中获取元素总数
if (typeinfo) g_ort->ReleaseTypeInfo(typeinfo);
}
}
void GetModelOutputInfo(const OrtApi* g_ort, OrtSession* session, OrtAllocator* allocator, ModelInfo* model_info) {
//***********输出信息****************//
CheckStatus(g_ort, g_ort->SessionGetOutputCount(session, &model_info->num_output_nodes)); // Get output count for session. 从会话中获取输出个数
model_info->InitialOutput();
for (size_t i = 0; i < model_info->num_output_nodes; i++) {
// Get input node names
char* input_name;
CheckStatus(g_ort, g_ort->SessionGetOutputName(session, i, allocator, &input_name)); // Get output name. 获取当前输出名称
model_info->output_node_names[i] = input_name;
// Get input tensor info
OrtTypeInfo* typeinfo;
CheckStatus(g_ort, g_ort->SessionGetOutputTypeInfo(session, i, &typeinfo)); // Get output type information. 获取当前输出的类型信息
const OrtTensorTypeAndShapeInfo* tensor_info;
CheckStatus(g_ort, g_ort->CastTypeInfoToTensorInfo(typeinfo, &tensor_info)); // Get OrtTensorTypeAndShapeInfo from an OrtTypeInfo. 类型转换OrtTypeInfo->OrtTensorTypeAndShapeInfo
// Get input tensor type
ONNXTensorElementDataType type;
CheckStatus(g_ort, g_ort->GetTensorElementType(tensor_info, &type)); // Get element type in OrtTensorTypeAndShapeInfo. 从tensor info中获取元素类型
model_info->output_types[i] = type;
// Get input shapes/dims
size_t num_dims;
CheckStatus(g_ort, g_ort->GetDimensionsCount(tensor_info, &num_dims)); // Get dimension count in OrtTensorTypeAndShapeInfo. 从tensor info中获取维度数量
model_info->output_node_dims[i].resize(num_dims);
CheckStatus(g_ort, g_ort->GetDimensions(tensor_info, model_info->output_node_dims[i].data(), num_dims));// Get dimensions in OrtTensorTypeAndShapeInfo. 从tensor info中获取维度
size_t tensor_size;
CheckStatus(g_ort, g_ort->GetTensorShapeElementCount(tensor_info, &tensor_size)); // Get total number of elements in a tensor shape from an OrtTensorTypeAndShapeInfo. 从tensor info中获取元素总数
if (typeinfo) g_ort->ReleaseTypeInfo(typeinfo);
}
}
const wchar_t* model_path = L"model.onnx";
int main()
{
/*
* 1.模型加载
*/
//创建ort环境
const OrtApiBase* ptr_api_base = OrtGetApiBase();
const OrtApi* g_ort = ptr_api_base->GetApi(ORT_API_VERSION);
OrtEnv* env = NULL;
OrtSession* session = NULL;
OrtSessionOptions* session_options = NULL;
OrtAllocator* allocator = NULL;
CheckStatus(g_ort, g_ort->CreateEnv(ORT_LOGGING_LEVEL_ERROR, "INFERENCE", &env)); // Create an OrtEnv. 创建环境
CheckStatus(g_ort, g_ort->CreateSessionOptions(&session_options)); // Create an OrtSessionOptions object. 创建会话选项
CheckStatus(g_ort, g_ort->SetIntraOpNumThreads(session_options, 0)); // Sets the number of threads used to parallelize the execution within nodes. 线程数量
CheckStatus(g_ort, g_ort->SetSessionGraphOptimizationLevel(session_options, ORT_ENABLE_ALL)); // Set the optimization level to apply when loading a graph. 设置优化等级
//CUDA 加速
if (USE_CUDA) {
//CUDA option set
OrtCUDAProviderOptions cuda_option;
cuda_option.device_id = 0;
cuda_option.arena_extend_strategy = 0;
cuda_option.cudnn_conv_algo_search = OrtCudnnConvAlgoSearchExhaustive;
cuda_option.gpu_mem_limit = SIZE_MAX;
cuda_option.do_copy_in_default_stream = 1;
CheckStatus(g_ort, g_ort->SessionOptionsAppendExecutionProvider_CUDA(session_options, &cuda_option)); // Append CUDA provider to session options. 会话选项增加cuda硬件支持
}
//创建会话
CheckStatus(g_ort, g_ort->CreateSession(env, model_path, session_options, &session)); // Create an OrtSession from a model file. 从模型创建会话
CheckStatus(g_ort, g_ort->GetAllocatorWithDefaultOptions(&allocator)); // Get the default allocator. 获取默认内存分配器
/*
* 2.模型信息概览
*/
ModelInfo* model_info = new ModelInfo;
GetModelInputInfo(g_ort, session, allocator, model_info);
GetModelOutputInfo(g_ort, session, allocator, model_info);
/*
* 4.构建输入输出
*/
//创建输入输出
float* host_input = nullptr;
void* host_output;// = new int64_t[imageHeight * imageWidth];
GetInputData(host_input, img_path);
float* dev_input;
cudaMalloc((void**)&dev_input, 400 * 424 * 3 * sizeof(float));
cudaMemcpyAsync(dev_input, host_input, 400 * 424 * 3 * sizeof(float), cudaMemcpyHostToDevice);
int input_tensor_size = 400 * 424 * 3;
OrtMemoryInfo* memory_info = NULL;
//CheckStatus(g_ort, g_ort->CreateMemoryInfo("CUDA", OrtDeviceAllocator, 0, OrtMemTypeCPU, &memory_info)); // Create an OrtMemoryInfo. 创建GPU内存信息
CheckStatus(g_ort, g_ort->CreateCpuMemoryInfo(OrtArenaAllocator, OrtMemTypeDefault, &memory_info)); // Create an OrtMemoryInfo for CPU memory. 创建CPU内存信息
OrtValue* input_tensor = NULL;
OrtValue* output_tensor = NULL;
for (size_t i = 0; i < model_info->num_input_nodes; i++)
{
CheckStatus(g_ort, g_ort->CreateTensorWithDataAsOrtValue(memory_info, dev_input, input_tensor_size * sizeof(float),
model_info->input_node_dims[i].data(), model_info->input_node_dims[i].size(), model_info->input_types[i], &input_tensor)); //Create a tensor backed by a user supplied buffer. 创建一个多维度张量input_tensor
// ToDo: input_tensor 容器
}
cudaDeviceSynchronize();
CheckStatus(g_ort, g_ort->Run(session, NULL, model_info->input_node_names.data(), (const OrtValue* const*)&input_tensor, model_info->num_input_nodes,
model_info->output_node_names.data(), model_info->num_output_nodes, &output_tensor)); // Run the model in an OrtSession. 执行模型流程
CheckStatus(g_ort, g_ort->GetTensorMutableData(output_tensor, (void**)&host_output)); // Get a pointer to the raw data inside a tensor. 获取输出tensor的指针位置,此步可以实现从device直接到host
delete[] host_input;
}注意事项:
1.GetInputData函数是读入图片,将数据放到host_input之中;model_path是模型路径
2.数据要与在python下的数据保持一致,例如是否需要做归一化等等
3.最终的数据存储在host_output之中,需要根据模型的输出类型从host_output中读取,利用。














 7363
7363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









