







今天和大家分享一篇关于Stable Diffusion是如何工作的文章《How does Stable Diffusion work?》。
感兴趣可以直接阅读英文网页。
我对原文进行了精简并修改了部分内容使大家更容易理解,下面请看熟肉。
Stable Diffusion能做什么?
在最简单的形式中,Stable Diffusion是一种文本到图像的模型。给它一个文本提示,它将返回与文本匹配的图像。

扩散模型 Diffusion model
Stable Diffusion属于一类称为扩散模型的生成式深度学习模型。这意味着它们旨在生成类似于它们在训练中看到的新数据。在稳定扩散的情况下,数据是图像。
为什么叫扩散模型?因为它的数学形式看起来很像物理学中的扩散,让我们来看看这个想法。
假设我只用两种图像训练了一个扩散模型:猫和狗。在下图中,左边的两个峰代表猫和狗图像组。

前向扩散 Forward diffusion
前向扩散过程向训练图像添加噪声,逐渐将其变成不典型的噪声图像。前向过程会将任何猫或狗图像变成噪声图像。最终,你将无法分辨它们最初是狗还是猫。就像一滴墨水落入一杯水中,墨滴在水中扩散。几分钟后,它随机分布在整个水中,你不再能够判断它最初是落在中心还是边缘附近。
下面是进行前向扩散的图像的示例。猫图像变成随机噪声。

反向扩散 Reverse diffusion
现在到了令人兴奋的部分,如果我们可以逆转扩散呢?就像倒放视频一样,时间倒退,我们将看到墨滴最初添加的位置。

从嘈杂、无意义的图像开始,反向扩散恢复猫或狗的图像。从技术上讲,每个扩散过程都有两个部分:漂移和随机运动。反向扩散会偏向猫或狗图像,但不会偏向于两者之间。这就是为什么结果可以是猫或狗。
模型如何进行训练
反向扩散的想法无疑是巧妙而优雅的。但价值百万美元的问题是:“如何才能做到这一点?”。为了反向扩散,我们需要知道图像中添加了多少噪声。
答案是训练神经网络模型来预测添加的噪声。它在稳定扩散中被称为噪声预测器(Noise predictor),是一个U-Net模型。训练过程如下:
- 选择一张训练图像,例如猫的照片。
- 生成随机噪声图像。
- 通过将噪声图像添加到一定数量的步骤来破坏训练图像。
- 让噪声预测器告诉我们添加了多少噪声。(通过调整其权重并向其显示正确答案来完成)。

训练后,我们有了一个噪声预测器,能够估计添加到图像中的噪声。
使用噪声预测器
现在我们有了噪声预测器。如何使用它?
我们首先生成一个完全随机的图像,并要求噪声预测器告诉我们噪声。然后,我们从原始图像中减去这个估计的噪声。重复此过程几次,就可以得到一只猫或一只狗的图像。

稳定扩散模型 Stable Diffusion model
现在我要告诉你一些坏消息:我们刚才讨论的不是稳定扩散的工作原理!原因是上述扩散过程是在图像空间中进行的。它的计算速度非常非常慢。您将无法在任何单个GPU上运行,更不用说笔记本电脑上的蹩脚GPU了。
图像空间是巨大的。想想看:具有三个颜色通道(红、绿、蓝)的512×512图像是一个786432维的空间!像Google的Imagen和Open AI的DALL-E这样的扩散模型都在像素空间中。他们使用了一些技巧来使模型更快,但仍然不够。
潜在扩散模型 Latent Diffusion model
而Stable Diffusion就是用来解决这个问题。它是一种潜在扩散模型,它不是在高维图像空间中操作,而是首先将图像压缩到潜在空间中。潜在空间小了48倍,因此它获得了处理更少数字的好处。这就是为什么它要快得多。
变分自动编码器 Variational Autoencoder
而压缩的这个过程就是使用变分自动编码器这个技术来进行的。变分自动编码器 (VAE) 神经网络有两部分:编码器和解码器。编码器将图像压缩为潜在空间中的较低维表示,解码器从潜在空间恢复图像。

Stable Diffusion的潜在空间为4x64x64,比图像像素空间小48倍。我们谈到的所有前向和反向扩散实际上都是在潜在空间中完成的。
因此,在训练过程中,它不会生成噪声图像,而是在潜在空间(潜在噪声)中生成随机张量。它不是用噪声破坏图像,而是用潜在噪声破坏图像在潜在空间中的表示。正是这样的作法使得Stable Diffusion速度更快。
条件作用 Conditioning
即使这样还不够,文字提示在哪里进入图片?没有它,Stable Diffusion就不是文本到图像的模型。
这就是条件作用(Conditioning)的用武之地。条件作用的目的是引导噪声预测器,以便预测的噪声在从图像中减去后能够为我们提供想要的结果。
下面概述了如何处理文本提示并将其输入噪声预测器。分词器(Tokenizer,Stable Diffusion v1.5使用CLIP的分词器)首先将提示中的每个单词转换为一个称为token的数字。然后,每个标记都会转换为一个称为embedding的768个值向量。embedding随后由文本转换器进行处理,并准备好供噪声预测器使用。

但文本提示并不是调节稳定扩散模型的唯一方法。文本提示和深度图像都用于调节深度到图像模型,ControlNet使用检测到的轮廓、人体姿势等来调节噪声预测器,并实现对图像生成的出色控制。
这也是为什么Stable Diffusion不仅可以进行文生图,还可以图生图和局部重绘。以下就是Stable Diffusion的模型架构和文生图流程。
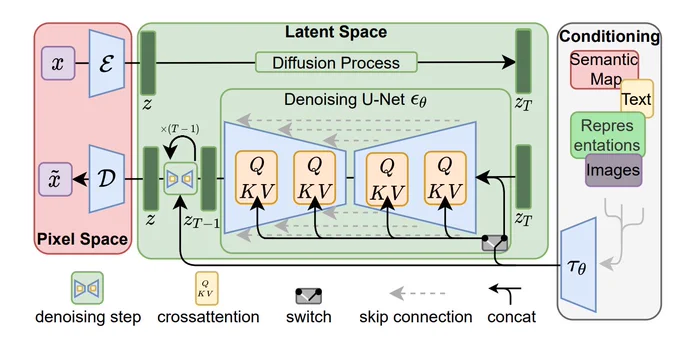

end~
看到这里你大概就弄懂了Stable Diffusion模型的运行过程了吧,如果觉得还不错的话,欢迎关注我😘。
也欢迎关注我的公棕号「ChaosstuffAI」,了解更多关于Stable Diffusion的知识与AIGC创作技巧!
















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









