







Semantic Video Segmentation by Gated Recurrent Flow Propagation
Abstract
作者提出了一种深度的端到端可训练的视频分割方法,除了稀疏标记的帧之外,该方法还能利用未标记数据中存在的信息,以改进语义估计。该模型结合了卷积架构和时空变换循环层,该层能通过光流在时间上传播标记信息,并基于其局部估计的不确定性进行自适应门控。
Introduction
作者围绕在视频中计算准确且时间一致的语义分割的系统是场景理解的核心这一重点,讲述了现有模型的一些缺陷,而作者采用一种明确的建模方法,依靠现有的单帧cnn增强空间变压器结构,实现沿光流场的扭曲。同时结合自适应循环单元来学习未来单个帧的估计与从附近帧临时传播的标记信息融合在一起,并根据其不确定性进行适当门控。
Related Work
作者回顾了早期语义分割的相关文献,从早期基于时间扩展的方法到归一化分割、随机场模型和跟踪、运动分割或高效的基于分层图的公式等等。
Methodology
作者从前一个时间步ht-1的语义分割开始,通过计算wt=&t-1,t(ht-1)将其沿光流弯曲,使其与时刻t的分割对齐,其中&是沿光流的标签映射。这被作为隐藏状态送到一个门控循环单元,其中另一个输入是由单帧CNN计算的用于语义分割的估计xt.
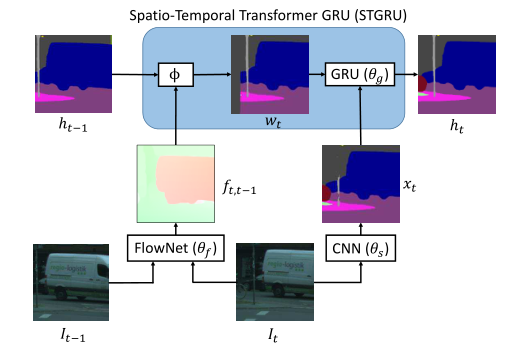
图1 STGRU结构图
因此模型的主要组成部分:时空变压器扭曲和门控循环单元。
Experiments
作者将自己的方法与其他语义分割方法进行比较,所使用的是具有挑战性的cityscape和CamVid数据集。
Conclusions
作者的模型可以成功地将信息从标记的视频帧传播到附近未标记的视频帧,从而提高语义视频分割的准确性和时间标记的一致性,而不需要额外的注释成本,并且需要很少的补充计算。
















 6167
6167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











