






这是PPQ的核心数据结构定义,其中的文件描述了PPQ软件的底层逻辑:
- ppq.core.common:ppq预定义常量,用户可以修改该文件从而配置软件的相应功能。
- ppq.core.config:ppq基础定义,包括版本号,软件名等内容。
- ppq.core.data:ppq基础数据类型,包含pytorch.Tensor,numpy.ndarray的数据类型转换。
- ppq.core.defs:ppq元类型及全局工具函数定义。
- ppq.core.ffi:ppq应用程序编程接口,包含调用c/c++,cuda代码的相关逻辑。
- ppq.core.quant:ppq核心量化数据结构定义【非常重要】。
- ppq.core.storage:ppq持久化操作的相关定义。
TensorQuantizationConfig(Tensor量化控制结构体)
PPQ使用量化控制结构体描述量化行为,该结构体被定义在ppq.core.quant中。该结构体由15项不同的属性组成。
1.QuantizationPolicy量化策略
在TensorQuantizationConfig中,首当其冲的内容是TQC.policy,这是一个QuantizationPolicy对象。policy属性用于描述量化的规则,一个完整的量化策略是由多个量化属性(QuantizationProperty)组合完成的;在PPQ中目前支持8种不同的量化属性,可以使用以下属性来组合形成自定义的量化规则:
- PER_TENSOR:以Tensor为单位完成量化,每个Tensor使用一个scale和offset信息。
- PER_CHANNEL:以Channel为单位完成量化,每个Channel使用一个scale和offset信息。
- LINEAR:线性量化,通常的INT8,INT16皆属于线性量化,在线性量化的表示中不存在指数位。
- FLOATING:浮点量化,包括FP8 E4M3,FP8 E5M2,FP16,BF16等格式,在浮点量化中数据由底数和指数两部分组成。(在FP8 E4M3中,整数部分占据4位,小数部分占据3位,剩余1位可以用来表示符号位或者进行舍入。这种表示方法可以将浮点数转换为一个8位的固定点整数。其范围可以是从最小值-8到最大值7,即-8.0到7.875。)
- SYMMETRICAL:对称量化,在量化计算中不启用offset。
- ASYMMETRICAL:非对称量化,在量化计算中启用offset完成量化偏移。
- POWER_OF_2:限制scale取值必须为2的整数次幂,这一量化行为多见于端侧以及浮点量化。
- DYNAMIC:启用动态量化策略,对于每一批次数据,scale与offset都将被动态地计算更新。
下图解释了浮点量化与线性量化的区别:
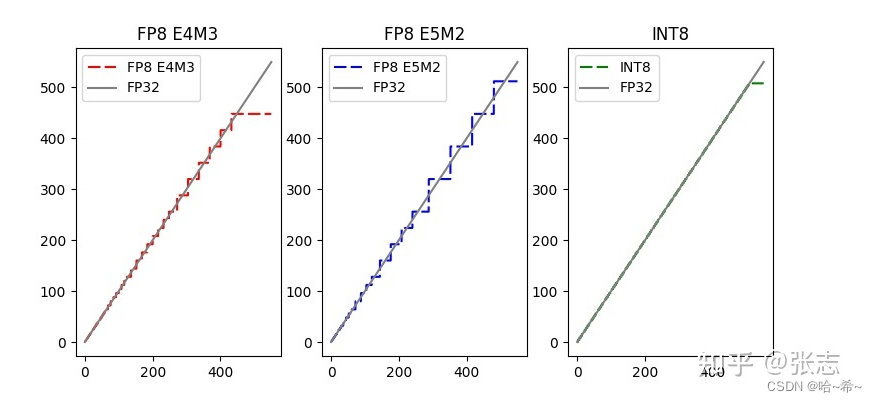
注:对于这张图的理解,FP32是不进行量化,第一张和第二张图都是浮点量化,第三张图示线性量化。
2.线性量化及相关属性
线性量化允许与下列属性进行组合:
QuantizationProperty.ASYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_CHANNEL,
QuantizationProperty.ASYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_TENSOR,
QuantizationProperty.SYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_CHANNEL,
QuantizationProperty.SYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_TENSOR,
QuantizationProperty.ASYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_TENSOR | QuantizationProperty.POWER_OF_2,
QuantizationProperty.SYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_TENSOR | QuantizationProperty.POWER_OF_2,
QuantizationProperty.ASYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_CHANNEL | QuantizationProperty.POWER_OF_2,
QuantizationProperty.SYMMETRICAL | QuantizationProperty.LINEAR | QuantizationProperty.PER_CHANNEL | QuantizationProperty.POWER_OF_2,
线性量化是最为常用的数值量化方法,有时也称其为均匀量化,在线性量化中,量化操作的计算方法为:
- Unscaled FP32 = (FP32 / scale) - offset
- INT8 = Clip(Round(Unscale FP32),quant_min,quant_max)
- Dequantized FP32 = (INT8 + offset) * scale
其中Round函数行为由TQC.rounding(RoundingPolicy)属性确定,PPQ支持7种不同的取整策略,其中ROUND_HALF_EVEN是最常见的取整策略。
quant_min,quant_max分别由TQC.quant_min,TQC.quant_max属性确定,对于线性量化而言它们是整数,通常为[-128,127]。部分框架使用[-127,127]作为截断值,在部分场景下如此定义有优势,但在Onnx的Q/DQ算子定义中不允许使用[-127,127]作为截断。
PPQ可以模拟1-32bit的任意位宽量化,但若以部署为目的,不建议使用8bit之外的配置。用户需知高位宽量化可能造成Scale过小,以至于浮点下溢出。
3.浮点量化与相关属性
浮点量化允许与下列属性进行组合:
QuantizationProperty.SYMMETRICAL | QuantizationProperty.FLOATING | QuantizationProperty.PER_CHANNEL | QuantizationProperty.POWER_OF_2,
QuantizationProperty.SYMMETRICAL | QuantizationProperty.FLOATING | QuantizationProperty.PER_TENSOR | QuantizationProperty.POWER_OF_2,
在浮点量化中,量化函数的计算方法为:
- Unscaled FP32 = (FP32 / scale)
- FP8 = Convert(Unscale FP32,quant_min,quant_max)
- Dequantized FP32 = FP8 * scale
其中Convert函数行为复杂,其转换过程分为三种不同的情况:
- 当Unscaled FP32大于quant_max,或者小于quant_min,则直接进行截断
- 当Unscaled FP32幅值大于FP8能够表达的最小值,此时需要移去多余的底数位,并对底数进行四舍五入
- 当Unscaled FP32数据小于规范化FP8能够表达的最小值,此时浮点下溢出,此时我们计算FP8=Round(Unscaled FP32 / FP8_MIN) * FP8_min
其中FP8_min是非格式化FP8能够表达的最小值。对于FP8 E4M3标准而言,其能表示的最大值为448.0,最小值为-448.0.
quant_min,quant_max分别由TQC.quant_min,TQC.quant_max属性确定,对于FLOATING量化,引入一个新的属性TQC.exponent_bits(int)。使用这个属性来指定总位宽中有多少数位用于表示指数(相应地,底数位为总位宽-指数位-1)。
在浮点量化中,尺度因子的选取对量化效果的影响不大,因此可以使用constant校准策略将所有尺度因子设置为1。
4.其他量化控制属性
- TQC.num_of_bits(int):量化位宽,对于INT8,FP8量化,量化位宽是8。对于INT16,FP16量化,量化位宽为16。
- TQC.state(QuantizationStates):量化状态,在PPQ中目前共计有8中不同的量化状态,该属性极大地丰富了PPQ量化信息的语义,使得我们能够更加灵活的控制量化行为。该属性可以被用于切换量化 / 非量化状态;执行量化联合定点;执行参数烘焙(也称为模型烘焙(model baking)或权重融合(weight fusion),是指将训练好的模型的参数从浮点数格式转化为定点数格式或其他低精度格式的过程。通过参数烘焙,可以将模型的参数压缩为更小的存储空间,并且可以在推理阶段加速模型的运行)。
- TQC.channel_axis(int):量化轴,对于PER_CHANNEL量化,使用这个属性来指定沿着哪一维度展开量化,如执行Per-tensor量化,该属性被忽略,可以将其设置为None。
- TQC.observer_algorithm(str):observer算法,其中observer是用于确定scale和offset的对象,使用这个属性指明要使用何种类型observer确定scale和offset。
- TQC.dominator(TensorQuantizationConfig):一个指向父量化信息的指针。在PPQ中TQC和TQC之间并不是独立的,他们之间可以存在父子关系。所有子量化信息与父量化信息共享scale和offset
- TQC.visibility(QuantizationVisibility):导出可见性,使用这个属性来告知ppq的导出器是否需要导出当前的TQC。
5.量化控制结构体的初始化
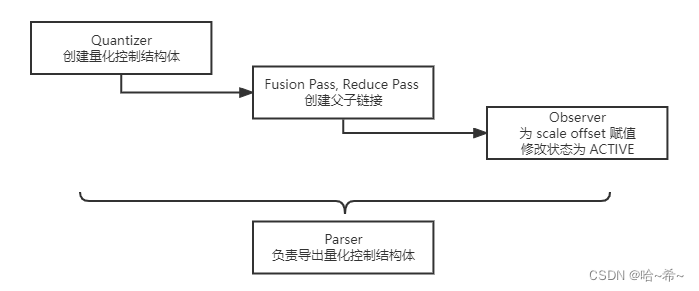
TensorQuantizationConfig是PPQ中的核心数据结构,它总是由Quantizer对象完成创建的:
# 下面这段代码为一个指定的算子创建了相应的Tensor Quantization Config
quantizer = PFL.Quantizer(paltform=TargetPlatform.TRT_INT8,graph=graph) # 取得TRT_INT8所对应的量化器
quantizer.quantize_operation(op_name=op.name,platform=diapatching[op.name])在PPQ中,Quantizer的职责是为算子初始化他们的量化控制结构体。不同的量化器将按照不同的规则创建控制结构体,如TRT_FP8所对应的量化器,只会为Conv,Gemm算子创建量化信息,要求他们的输入按照对称-浮点-Per Channel的方式完成量化。而DSP_INT8所对应的量化器为几乎所有的算子创建量化信息,要求他们按照非对称-线性-Per Tensor的方式完成量化。
手动创建量化结构体,使用ppq.lib中的接口:
# 创建一个默认的线性量化控制结构体(对称,per-tensor)
from ppq.lib import LinearQuantizationConfig
TQC = LinearQuantizationConfig()
# 创建一个默认的浮点量化控制结构体(FP8 E4M3)
from ppq.lib import FloatingQuantizationConfig
TQC = FloatingQuantizationConfig()6.量化控制结构体的校准
绝大部分的TensorQuantizationConfig在完成初始化之后都无法使用-它们的scale和offset均为空值,且Quantizer在初始化他们时会将其状态(TQC.state)置为INITIAL,处于这个状态的量化信息在计算过程中不会被启用。
我们必须送入一定量数据,进行必要Calibration操作后才能为网络中的量化信息确定合理的scale和offset值,这一过程是由种类繁多的Observer完成的:
# PPQ目前支持的8种不同的Observer
OBSERVER_TABLE = {
'minmax': TorchMinMaxObserver,
'kl': TorchHistObserver,
'percentile': TorchPercentileObserver
'mse': TorchMSEObserver
'isotone': TorchIsotoneObserver
'constant': ConstantObserver
'floating': DirectMSEObserver
'isotone': ...
}这些Observer会负责在网络计算过程中收集必要的统计信息,并为TQC的scale与offset赋予有效的值。在完成一切之后,Observer还会负责将TQC的状态(TQC.state)修改为ACTIVED。此时量化信息将被正式启用,从而在网络前向传播模拟量化计算。
7.量化控制结构体的父子链接
在讨论量化时,对于那些存在着多个输入的算子,例如add,concat,它们的所有输入总是被要求有着相同的scale。为了表达这种语义,为TQC添加了TQC.dominator属性,这一属性可以指向另一个量化控制结构体。
假设存在两个不同的量化控制结构体A,B:
- 语句A.dominator=B表示A将共享B的scale与offset(A.policy,A.num_of_bits等属性仍将使用自己的)。与此同时A.state将被修改为OVERLAPPED(A将不再启用)
- 语句A.master=B表示A将共享B的scale与offset(A.policy,A.num_of_bits等属性仍将使用自己的)。与此同时A.state将被修改为PASSIVE(A将仍然启用,但不具有独立的量化参数)
如果A已经是其他量化结构体C的父节点,则上述过程将级联地使得B成为A,C共同的父节点,A,C都将共享B的scale与offset。
下图简述了在量化控制结构体的生命周期中,量化状态是如何变迁的(量化优化过程负责修改量化控制信息的状态):
PPQ.Core.Common(PPQ全局控制常量)
PPQ全局控制常量被定义在ppq.core.common.py文件中,用户可以修改其中的定义以调整PPQ程序功能。截止PPQ0.6.6版本,共计38个常量可以被设置。这些常量将影响网络解析过程,校准过程与导出逻辑。在这里阐述部分常用的修改项:
- OBSERVER_MIN_SCALE - 校准过程Scale的最小值,迫于实际部署的需要,Int8量化的尺度因子不能过小,否则将导致浮点下溢出等数值问题。这个参数决定了所有PPQ Calibration可以提供的最小尺度因子值。该参数只影响校准,不影响训练过程(训练过程仍然可能产生较小的Scale)。该参数不适用于FP8量化。
- OBSERVER_KL_HIST_BINS - 校准过程中kl算法的参数,该参数将影响kl算法的效果,用户可以调整为1024,2048,4096,8192或其他。
- OBSERVER_PERCENTILE - 校准过程中Percentile算法的参数,该参数影响percentile算法的效果,用户可以调整其为0.999,0.9995,0.9999,0.99995,0.99999或其他。
- OBSERVER_MSE_HIST_BINS - 校准过程中mse算法的参数,该参数影响mse算法的效果,用户可以调整其为1024,2048,4096,8192或其他。
- FORMATTER_FORMAT_CONSTANT_INPUT - 读取Onnx图时,是否将图中所有以Constant算子作为输入的参数转换为Constant Variable,部分推理引擎不识别Constant算子,PPQ的优化过程也没有对Constant算子进行适配(特指那些卷积的参数是以Constant算子输入的情况),因此建议开启此选项。
- FORMATTER_FUSE_BIAS_ADD - 读取Onnx图时,是否尝试合并Bias Add。部分情况下,导出Onnx时前端框架会把Conv,ConvTranspose,Gemm等层的Bias单独拆分成一个Add算子,这将造成后续处理逻辑的错误,因此建议开启该选项。
- FORMATTER_REPLACE_BN_TO_CONV - 是否将单独的Batchnorm替换为卷积,因为我们无法判断Batchnorm的维数,PPQ会将所有孤立的(无法进行BN-Fusion的)Batchnorm替换成Conv2d,对于三维或一维网络而言,这可能会导致错误的结果。
- FORMATTER_REMOVE_IDENTITY - 是否移除图中所有的Identity算子。
- FORMATTER_REMOVE_ISOLATED - 是否移除图中的所有孤立的节点。
- PASSIVE_OPERATIONS - 一个集合,如果一个算子的类型出现在该集合中,PPQ对该算子执行输入-输出联合定点。即保证该算子的输入变量与输出变量共享Scale,如果算子有多个输入-输出变量,该操作只影响第一个输入和第一个输出变量。















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









