






Day20:串联所有单词的子串
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,不需要考虑 words 中单词串联的顺序
输入: s = “barfoothefoobarman”, words = [“foo”,“bar”]
输出:[0,9]
解释:从索引 0 和 9 开始的子串分别是 “barfoo” 和 “foobar” 。输出的顺序不重要, [9,0] 也是有效答案
题目地址

from collections import Counter
def findSubstring( s, words):
if not s or not words: return []
w_num = len(words)
w_len = len(words[0]) # 由题目知单词长度相同
res = []
window = len(s)-w_num*w_len+1 # 设置滑窗范围为从起始到只剩下不够words的长度
for i in range(window):
temp_s = s[i:i+w_num*w_len]
temp_sl = [temp_s[i:i+w_len] for i in range(0, len(temp_s), w_len)] # 按照单词的长度切割字符串
if Counter(words) == Counter(temp_sl):
res.append(i)
return res
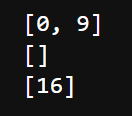
print(findSubstring('barfoothefoobarman',['foo','bar']))
print(findSubstring('wordgoodgoodgoodgoodbestword',['word','good','best','word']))
print(findSubstring('wordgoodgoodgoodgoodbestword',['good','best','word']))














 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









