






TLDR: 本文综述了推荐系统中使用的负采样技术。具体的,首先讨论了负采样在推荐中的作用。然后,对现有推荐中的负采样策略进行了综述,并将它们归为五类。最后,详细说明了在不同推荐场景中的负采样策略。

论文:https://arxiv.org/abs/2409.07237
推荐系统旨在从海量的用户行为数据中捕捉用户的个性化偏好,对于缓解信息过载问题至关重要。推荐系统通过分析用户行为,提供个性化的内容和商品推荐,改善人们的数字内容选择和导航方式。尽管推荐算法取得了显著成就,但用户偏好的动态性、信息茧房现象以及推荐系统中的固有反馈循环,使得用户与项目之间的交互非常受限,最终导致数据稀疏性问题。
传统的推荐算法通常只关注用户历史上的正面行为,而忽略了负反馈在理解用户兴趣中的关键作用。如下图所示,在大多数推荐数据集中明显缺乏负样本。通常需要在只提供正反馈的数据集中负采样一些负样本用于平衡模型训练。因此,在推荐系统中,深入探索能够揭示用户偏好中固有真实负面因素的负采样策略成为了一个不可避免的过程。
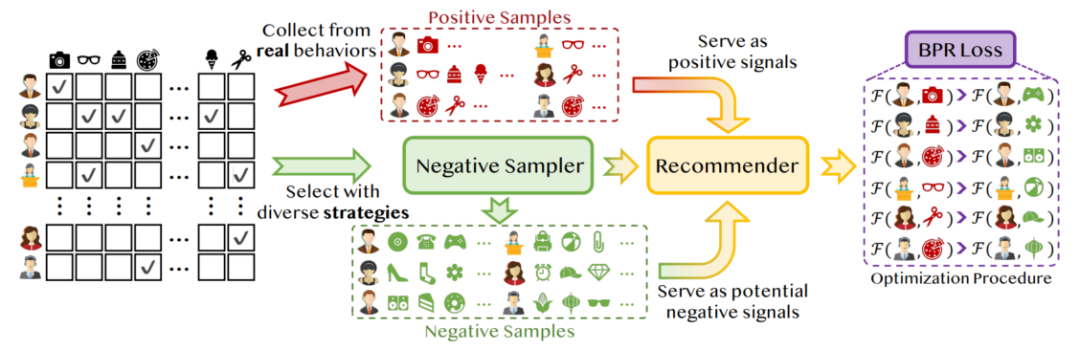
负采样技术能够揭示用户行为中固有的真实负面偏好,是推荐系统中不可或缺的一部分。负采样面临的挑战包括假阴性问题(即错误地将用户实际感兴趣的项目标记为负样本)、在准确性、效率和稳定性之间的权衡,以及在不同任务、目标和数据集之间的普遍性问题。尽管负采样对于推荐系统至关重要,但目前缺乏一个系统的分类和介绍现有研究的综述。本文旨在填补这一空白,提供一个关于负采样算法在推荐系统中应用的全面概述。
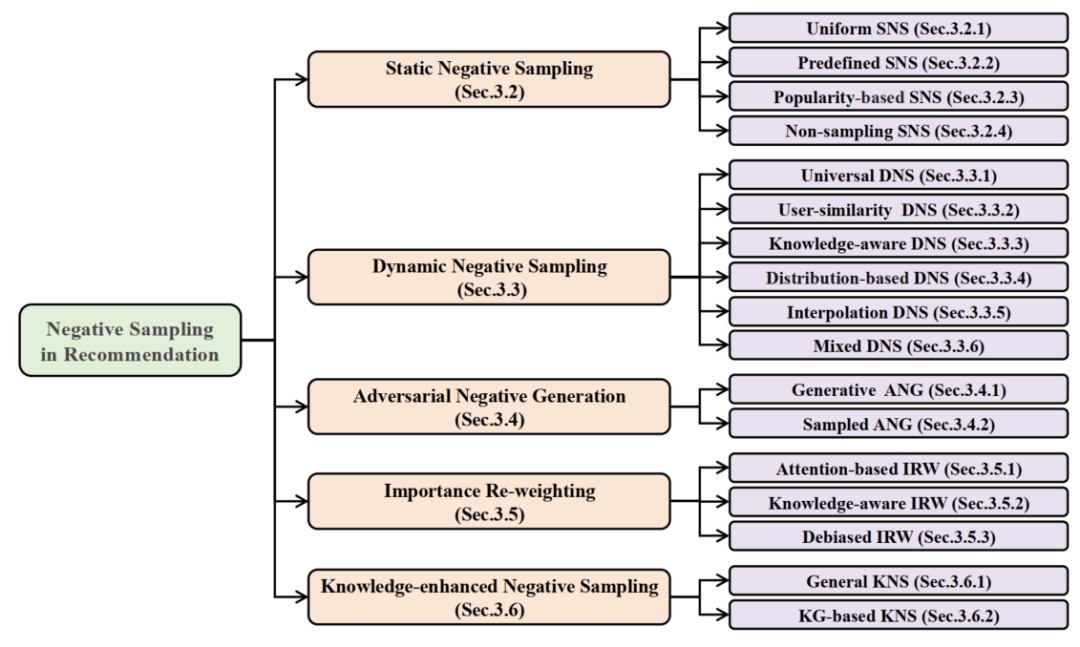
通过对现有推荐系统中的负采样策略进行了全面的文献综述,并根据它们的技术路径将其归类为五个类别:
静态负采样策略,其通常以静态概率采样负样本;
动态负采样策略,其尝试根据预先建立的采样标准动态选择负样本;
对抗负样本生成策略,其利用对抗学习范式来采样或生成看似合理的项目作为负样本;
重要性重加权策略,其旨在识别每个样本的重要性,并以数据驱动的方式为它们分配不同的权重;
知识增强负采样策略,其专注于通过挖掘辅助知识中的隐含关联来采样负样本
静态负采样策略
在深度推荐系统的初期阶段,传统方法依赖于静态负采样策略(SNS)方法,从用户的未观察到的项目中选择负样本。静态负采样策略的主要目标是提供多样化的的负样本,并通过推荐系统促进获取更全面的用户偏好模式。本文将现有的静态负采样策略研究分为四个类别:均匀静态负采样、预定义静态负采样、基于流行度的静态负采样和非采样静态负采样。它们的行为依赖性、优势和挑战在下表中进行总结。
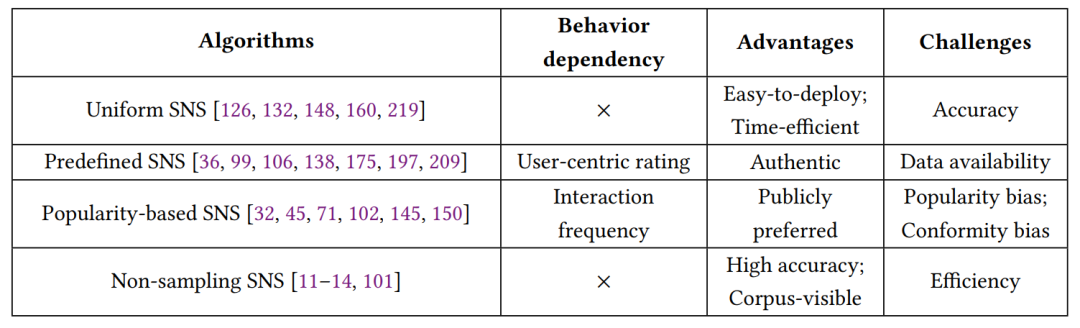
其中,均匀静态负采样以其易于部署和时间效率高的特点成为最广泛使用的静态负采样方法。然而,采样中固有的随机性为其推荐性能引入了可变性。预定义静态负采样利用真实的以用户为中心的评分来选择负样本。尽管它的实施简单直接,但它严重依赖于用户行为的可访问性。在将大多数用户的主流偏好纳入训练过程的同时,基于流行度的静态负采样也引入了固有的流行度偏差和一致性偏差。非采样静态负采样结合了整个训练数据中每个用户的未观察到的项目。保持对数据集整体的可见性提高了推荐系统的性能,但在计算效率上遇到了挑战。
动态负采样策略
为了捕捉相对有信息量的负样本,近年来出现了一波动态负采样(DNS)策略。动态负采样指的是从动态选择的项目候选者中,选择与正样本表示(或用户表示)更相关的项目作为负样本。例如,先驱性的动态负面采样策略通常从随机选择的项目候选者中选择最难的项目。后续的工作主要集中在建模用户和项目之间的关系,或精确调整候选集的采样难度。特别地,动态负采样在不同的推荐目标和场景中已经超越了大多数现有的负采样方法。本文将现有的动态负采样策略归类为六组:通用动态负采样、用户相似性动态负采样、知识感知动态负采样、基于分布的动态负采样、插值动态负采样和混合动态负采样。它们的优势和挑战详细记录在下表中。
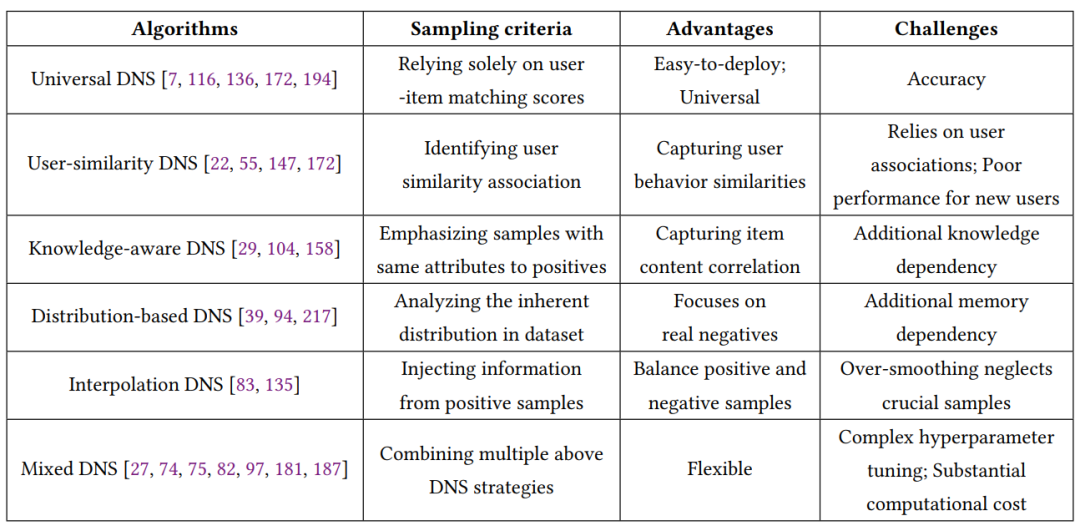
在这些方法中,通用动态负采样作为一种易于部署和通用的方法脱颖而出。然而,它依赖于用户-项目匹配分数,这对准确性构成了挑战。用户相似性动态负采样优先识别用户相似性关联并捕捉用户行为相似性,同时面临用户关联依赖的挑战,尤其是对于新用户。知识感知动态负采样强调具有与正面样本相似属性的样本,以捕捉它们的内容相关性,引入了对知识的额外依赖。基于分布的动态负采样分析数据集中的固有分布,专注于真正的负面样本,但增加了对空间复杂性的依赖。插值动态负采样通过注入正面信息平衡正面和负面样本,但面临过度平滑问题,忽略了关键样本。混合动态负采样通过结合多种策略表现出显著的灵活性,但复杂的超参数调整和大量的计算成本为这些策略带来了新的挑战。在后续部分,我们将介绍现有的动态负面采样策略的实施细节和有效机制,以检测有信息量的负面样本,以提高准确性和效率,促进模型优化。
对抗负样本生成策略
对抗负样本生成(ANG)是一种旨在增强推荐系统鲁棒性和性能的复杂技术。与其他负面采样策略一样,对抗负样本生成的核心是解决训练数据不平衡的挑战,其中正样本往往占主导地位,而真正的负面实例相对较少。现有的对抗负样本生成研究可以基本上分为两种不同的范式:生成式对抗负样本生成和采样式对抗负样本生成。每种策略的重点、优势和挑战都在下表中系统地概述。
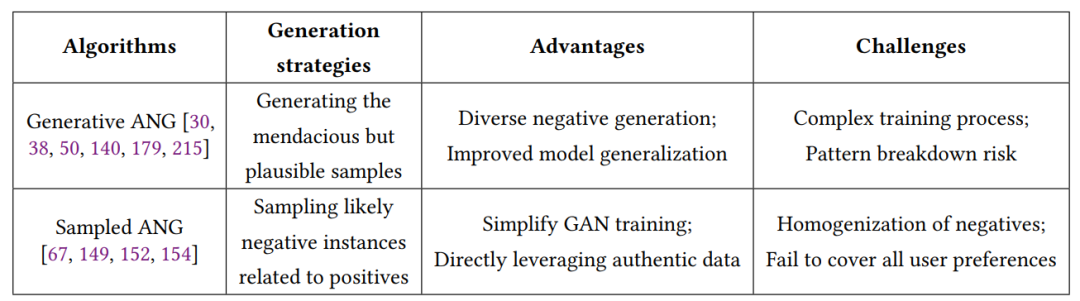
生成式对抗负样本生成利用生成式对抗网络或其他生成式模型来生成高质量的负样本,这些样本能够代表用户潜在的不喜欢。这种方法能够增加模型的泛化能力,但生成过程可能需要大量的计算资源。采样式对抗负样本生成则侧重于从现有的候选集中选择或加权负样本,以创建更具挑战性的负样本。这种方法可以更有效地利用可用数据,但可能难以捕捉到用户偏好的复杂性和多样性。两种方法都旨在通过引入更具挑战性的负样本来提高推荐模型的区分能力和鲁棒性,但它们在实施和优化方面面临着不同的挑战。
重要性重加权策略
重要性重加权策略(IRW)是数据挖掘和机器学习中使用的一种复杂统计技术。它的核心是微妙地调整样本权重,以优先考虑给定数据集中某些负样本的重要性。对重要性重加权算法的可以归类为基于注意力的重要性重加权、基于知识的重要性重加权和去偏重要性重加权。这些策略的关键方面、优势和挑战在下表中系统地描述。
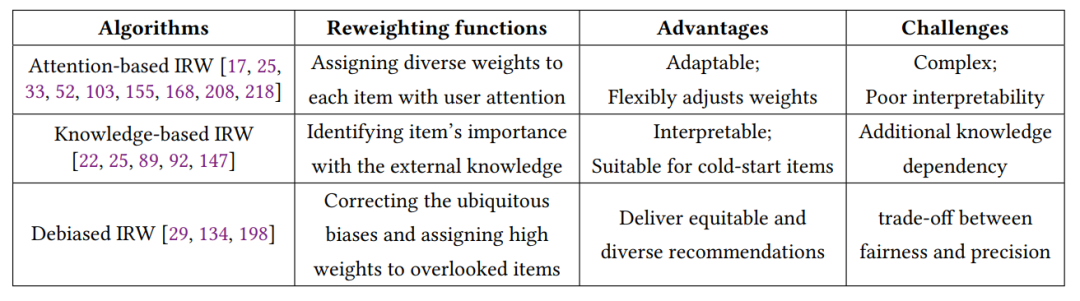
基于注意力的重要性重加权强调为每个项目分配不同的重视程度,以用户兴趣关注为依据,使其适应性强,能够灵活地调整权重。然而,它由于其复杂性和相对较差的可解释性而面临挑战。基于知识的重要性重加权侧重于利用外部结构化知识确定每个项目的重要性,适合于冷启动问题,但引入了对知识的额外依赖。去偏重要性重加权旨在纠正普遍存在的偏见,为被忽视的项目分配更高的权重,以提供公平和多样化的推荐。尽管如此,它涉及到公平性和精确度之间的权衡。
知识增强负采样策略
知识增强负采样(KNS)是推荐系统中的一种关键负采样策略,它利用辅助信息知识的可用性,如辅助信息(即,用户的社交环境和项目的异构知识)和知识图谱,来完善负样本的选择。知识增强负面采样的核心在两个不同的维度上展开:通用知识增强负采样和基于知识图谱的知识增强负采样。他们的知识源、优势以及挑战总结在下表中。
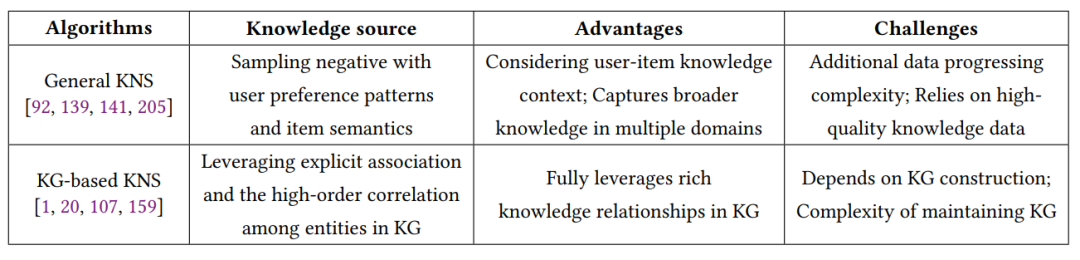
通用知识增强负采样侧重于使用用户和项目的辅助信息来识别和选择与用户偏好更接近的负面样本,这有助于提高推荐系统的准确性和用户满意度。基于知识图谱的知识增强负采样利用知识图谱中的实体和关系来发现用户和项目之间的潜在联系,从而选择更相关的负面样本。这种方法可以帮助推荐系统更好地理解复杂的用户偏好,并提供更准确的推荐。
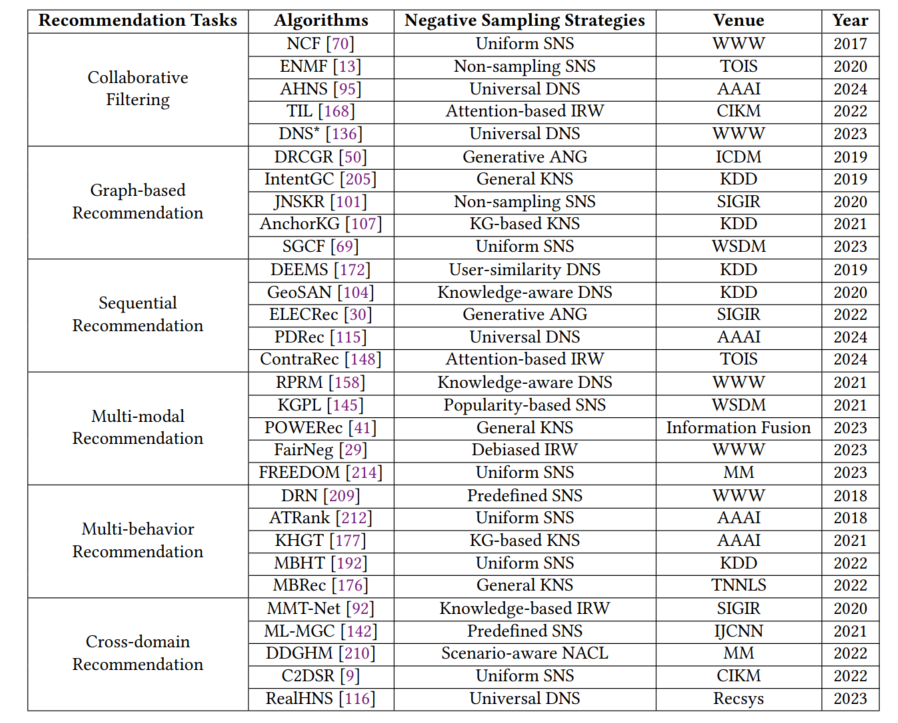
下表总结了在6类经典推荐模型(协同过滤、图推荐、序列推荐、多模态推荐、多行为推荐以及跨域推荐)上具有代表性的5个方法所使用的负采样策略。
最后,本文给出了对于负采样技术在推荐系统场景中的未来研究方向,比如进一步探索假负例问题、困难负采样上的课程学习、利用因果推理理解负样本、缓解负采样中的偏差等。
更多技术细节请阅读原始论文。
欢迎干货投稿 \ 论文宣传 \ 合作交流
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









