




欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
视频推荐系统
1. 问题描述
目标是为YouTube用户构建一个视频推荐系统,以最大化用户参与度并建议新的内容类型。系统目标包括:
- 增加用户参与度。
- 向用户介绍新的多样化内容。

2. 指标设计和要求
指标
离线指标:
- 精准率 (Precision): 推荐的相关视频与推荐的总视频数之比。
- 召回率 (Recall): 推荐的相关视频与总相关视频数之比。
- 排序损失 (Ranking Loss): 用于衡量推荐视频顺序预测误差的指标。
- 对数损失 (Logloss): 用于衡量概率预测准确性的指标。
在线指标:
- 点击率 (CTR): 点击推荐视频的用户数与看到推荐的总用户数之比。
- 观看时间 (Watch Time): 用户观看推荐视频的总时间。
- 转化率 (Conversion Rates): 用户在观看推荐视频后执行预期操作(例如订阅频道)的比例。
要求
训练:
- 频率: 多次训练模型以捕捉时间变化,因为用户行为可能难以预测,视频可能会迅速走红。
- 吞吐量: 确保训练过程能够高效处理大量数据。
推断:
- 延迟: 每次用户访问主页时,推荐必须在200ms内生成,理想情况下在100ms以下。
- 平衡: 在探索(展示新内容)和利用(展示历史相关内容)之间找到适当的平衡。过度利用历史数据会阻止新视频展示给用户。
总结
| 类型 | 期望目标 |
|---|---|
| 指标 | 合理的精准率,高召回率 |
| 训练 | 高吞吐量,能够频繁重新训练 |
| 推断 | 延迟在100ms到200ms之间,灵活的探索与利用平衡 |
推荐系统应确保在提供相关内容和介绍新内容之间取得平衡,以保持用户参与并发现新视频。系统需要对快速变化的用户偏好和流行趋势做出响应和适应。
3. 多阶段模型
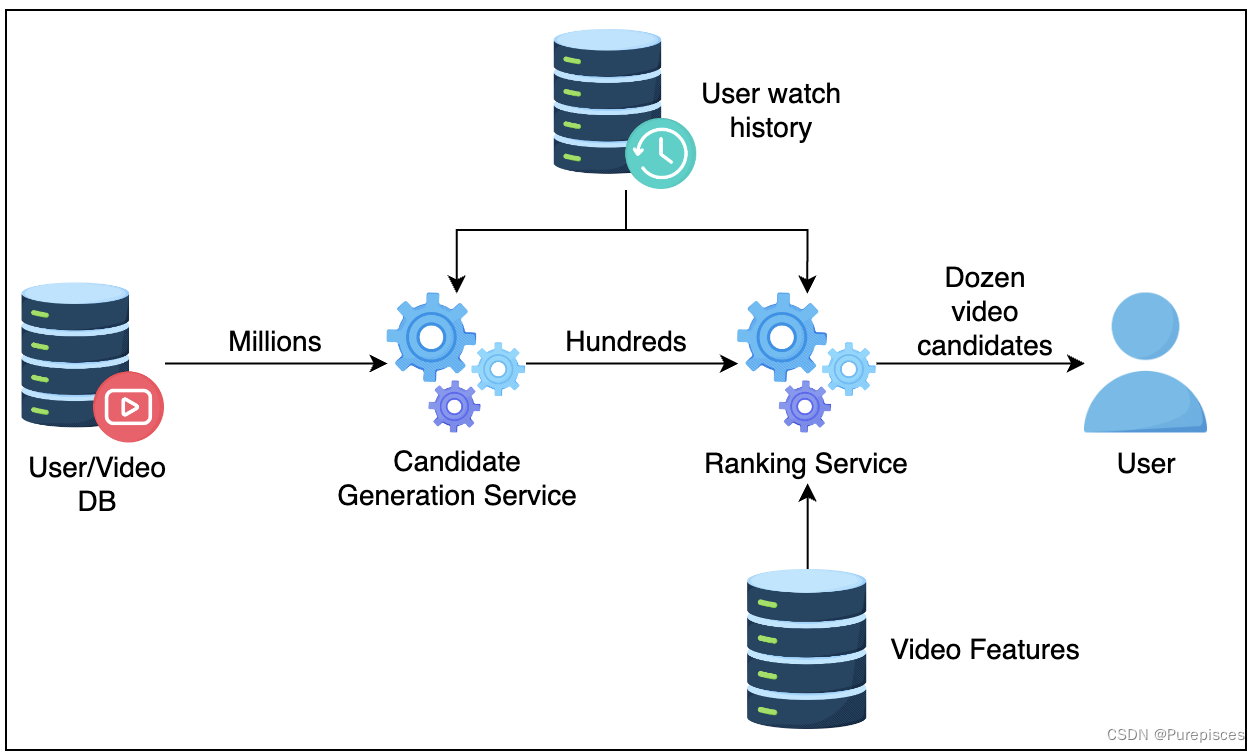
视频推荐系统的架构分为两个主要阶段:候选生成和排序。这种两阶段方法有助于高效地扩展系统。
这是许多机器学习系统中常见的模式。
我们将在下面的部分中探讨这两个阶段。
候选生成模型
候选模型将根据用户观看历史和用户观看的视频类型找到相关视频。
用户观看历史
该术语包含了用户在平台上与视频互动的所有详细信息。包括:
- 观看视频列表:用户观看的具体视频。
- 观看时长:用户观看每个视频的时长。
- 观看频率:用户观看视频的频率。
- 观看时间:用户观看每个视频的时间戳。
- 观看模式:如狂看或在特定时间段观看视频的模式。
用户观看的视频类型
该术语更侧重于用户参与的视频的特征或类别。包括:
- 类型:如喜剧、剧情、动作、纪录片等类别。
- 主题:具体的主题或主题,如烹饪、技术、体育等。
- 内容属性:如视频长度(短片 vs. 全长电影)、语言、制作质量和格式(如直播、预录视频)。
- 元数据标签:描述视频内容的关键词。
特征工程
每个用户都有一个观看视频列表(视频,观看时长)。
示例:
- 用户 A:
- “烹饪大师班”: 30分钟
- “科技评测”: 15分钟
- “旅行视频日志”: 45分钟
训练数据
用户-视频观看空间:使用选定期间的数据(如上个月,过去6个月)来平衡训练时间和模型准确性。
模型
-
候选生成可以通过矩阵分解来完成。候选生成的目的是根据用户的观看历史生成“某种程度上”相关的内容。候选列表需要足够大,以捕捉潜在的匹配,使模型在期望的延迟下表现良好。
-
一种解决方案是使用协同算法,因为推理时间快,能够捕捉用户在用户-视频空间中的品味相似性。
协同过滤是一种广泛的算法类别,利用用户互动(如评分、点击)来进行推荐。包括基于用户和基于项目的协同过滤。这些算法计算用户或项目之间的相似性以生成推荐。
类型:
- 基于用户的协同过滤:基于相似用户的偏好推荐项目。
- 基于项目的协同过滤:推荐类似于用户之前喜欢的项目。
矩阵分解是一种揭示用户与项目之间互动的潜在特征的技术。它在协同过滤中常用于通过将用户-项目交互矩阵分解为低维矩阵来增强推荐过程。
实际上,对于大规模系统(如Facebook, Google),我们不使用协同过滤,而是更偏向于低延迟的方法来获取候选者。一个例子是利用倒排索引(常用于Lucene, Elastic Search)。另一个强大的技术是FAISS或Google ScaNN。
排序模型
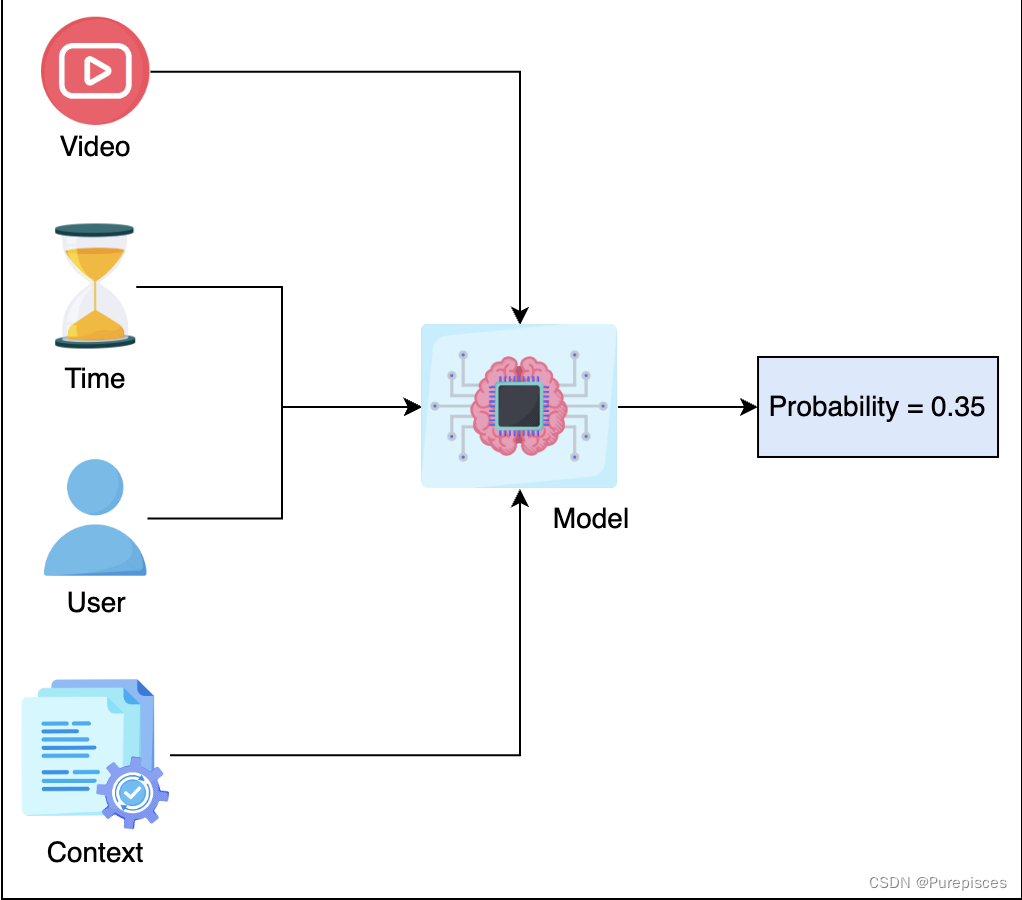
在推断过程中,排序模型接收由候选生成模型提供的视频候选列表。对于每个候选视频,排序模型估计该视频被观看的概率。然后,它根据该概率对视频候选进行排序,并将列表返回给上游过程。
特征工程
| 特征 | 特征工程 |
|---|---|
| 观看的视频ID | 视频嵌入 |
| 历史搜索查询 | 文本嵌入 |
| 位置 | 地理位置嵌入 |
| 用户相关特征:年龄,性别 | 标准化或归一化 |
| 之前的展示 | 标准化或归一化 |
| 时间相关特征 | 月份,年份周,假日,星期几,一天中的小时 |
训练数据
我们可以使用用户观看历史数据。通常,观看与未观看的比例为2/98。因此,大多数时间用户不会观看视频。
模型
起初,我们需要从简单模型开始,因为我们可以在后期增加复杂性。
-
一个全连接的神经网络简单而强大,适合表示非线性关系,并且可以处理大数据。
-
我们从一个全连接的神经网络开始,最后一层使用Sigmoid激活函数。原因是Sigmoid函数返回的值在[0, 1]范围内,因此非常适合估计概率。
对于深度学习架构,我们可以使用ReLU(修正线性单元)作为隐藏层的激活函数。在实践中非常有效。
- 损失函数可以使用交叉熵损失。
4. 计算与估算
假设
为了简化,我们可以做以下假设:
- 每月视频观看量为1500亿。
- 观看的视频中有10%来自推荐,共150亿视频。
- 在主页上,用户会看到100个视频推荐。
- 平均而言,用户从100个视频推荐中观看两个视频。
- 如果用户在给定时间内(如10分钟)未点击或观看某视频,则该推荐视为未被观看。
- 总用户数为13亿。
数据规模
- 1个月内,我们收集了150亿个正标签和7500亿个负标签。
- 一般来说,我们可以假设每个数据点都收集了数百个特征。为了简化,每行数据需要500字节存储。一个月内,我们需要存储8000亿行数据。
- 总大小:
500 * 800 * 10^9 = 4 * 10^14字节 = 0.4PB。为了节省成本,我们可以在数据湖中保留最近六个月或一年的数据,将旧数据存档在冷存储中。
带宽
- 假设每秒我们需要为1000万用户生成推荐请求。每个请求将为1k-10k个视频生成排名。
规模
- 支持13亿用户
5. 系统设计
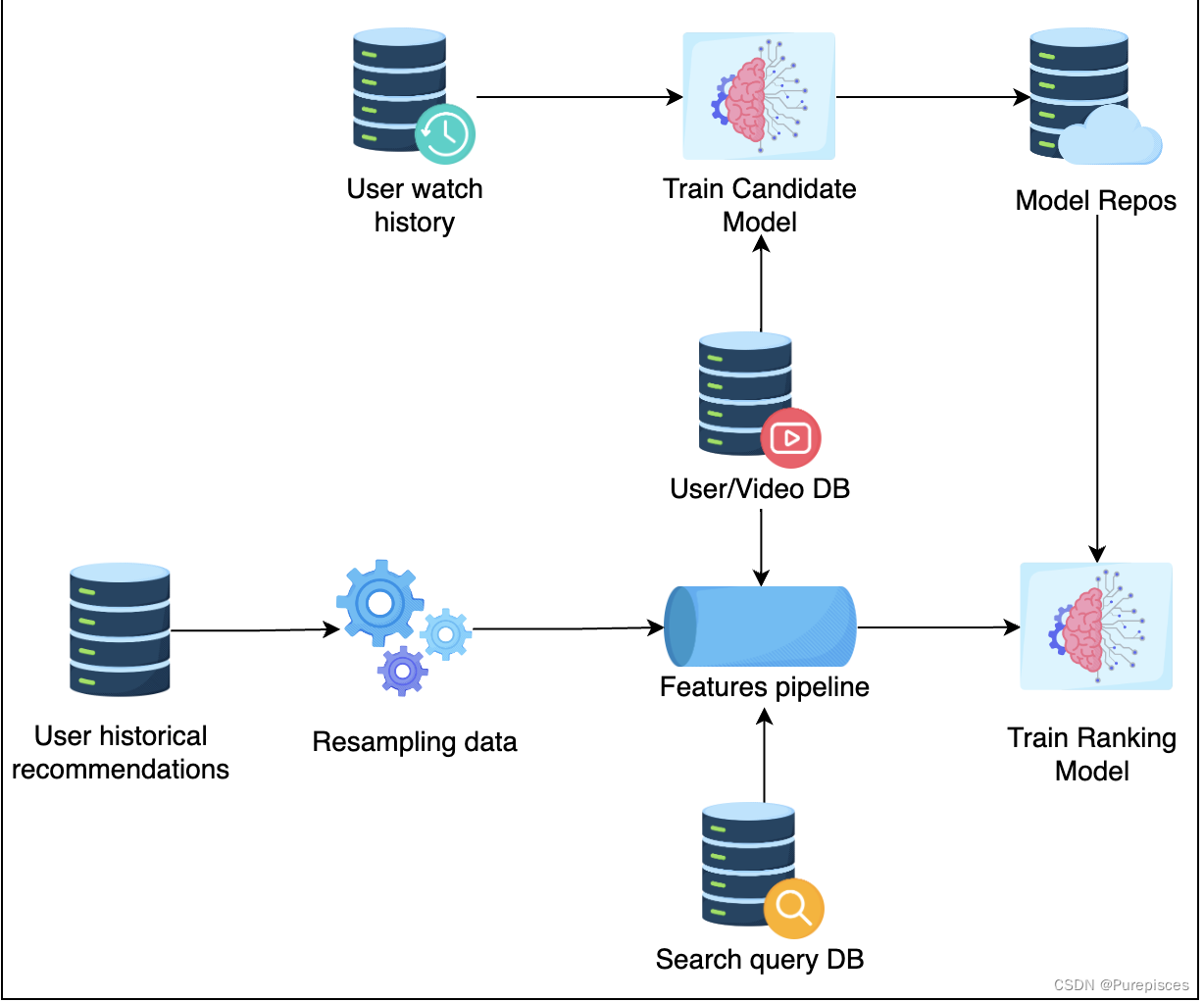
高级系统设计
-
数据库
- 用户观看历史:存储特定用户随时间观看的视频。
- 搜索查询数据库:存储用户过去搜索的历史查询。
- 用户/视频数据库:存储用户列表及其资料以及视频元数据。
- 用户历史推荐:存储特定用户的过去推荐。
-
重采样数据:这是流水线的一部分,通过下采样负样本来帮助扩展训练过程。
-
特征流水线:一个生成所有训练模型所需特征的流水线程序。特征流水线需要提供高吞吐量,因为我们需要多次重新训练模型。可以使用Spark或Elastic MapReduce或Google DataProc。
高吞吐量 vs. 带宽
吞吐量:单位时间内处理的数据量或完成的任务量。它是系统在特定时间内可以执行的工作量的度量。
带宽:网络在单位时间内传输数据的能力,通常以每秒比特数(bps)来衡量。它更多的是关于网络可以传输数据的最大速率。
虽然吞吐量和带宽是相关的概念,但它们并不相同。吞吐量衡量系统的实际数据处理能力,而带宽则衡量网络的潜在数据传输速率。
- 模型库:用于存储所有模型,使用AWS S3是一个常见的选择。
实际上,在推断过程中,我们希望能够近乎实时地获取最新模型。一个常见的模式是推断组件根据时间戳频繁从模型库中拉取最新模型。
挑战
巨大的数据规模
- 解决方案:选择最近1个月或6个月的数据。
数据不平衡
- 解决方案:执行随机负样本下采样。
高可用性
- 解决方案1:使用模型即服务,每个模型将在Docker容器中运行。
- 解决方案2:使用Kubernetes自动扩展pod数量。
Pod是Kubernetes对象模型中最小和最简单的单位。它表示集群中运行过程的单个实例。Pod是Kubernetes应用程序的基本构建块,每个Pod封装了一个或多个容器(通常是Docker容器),以及共享的存储/网络资源和容器运行规范。
让我们检查系统的流程:
系统流程
-
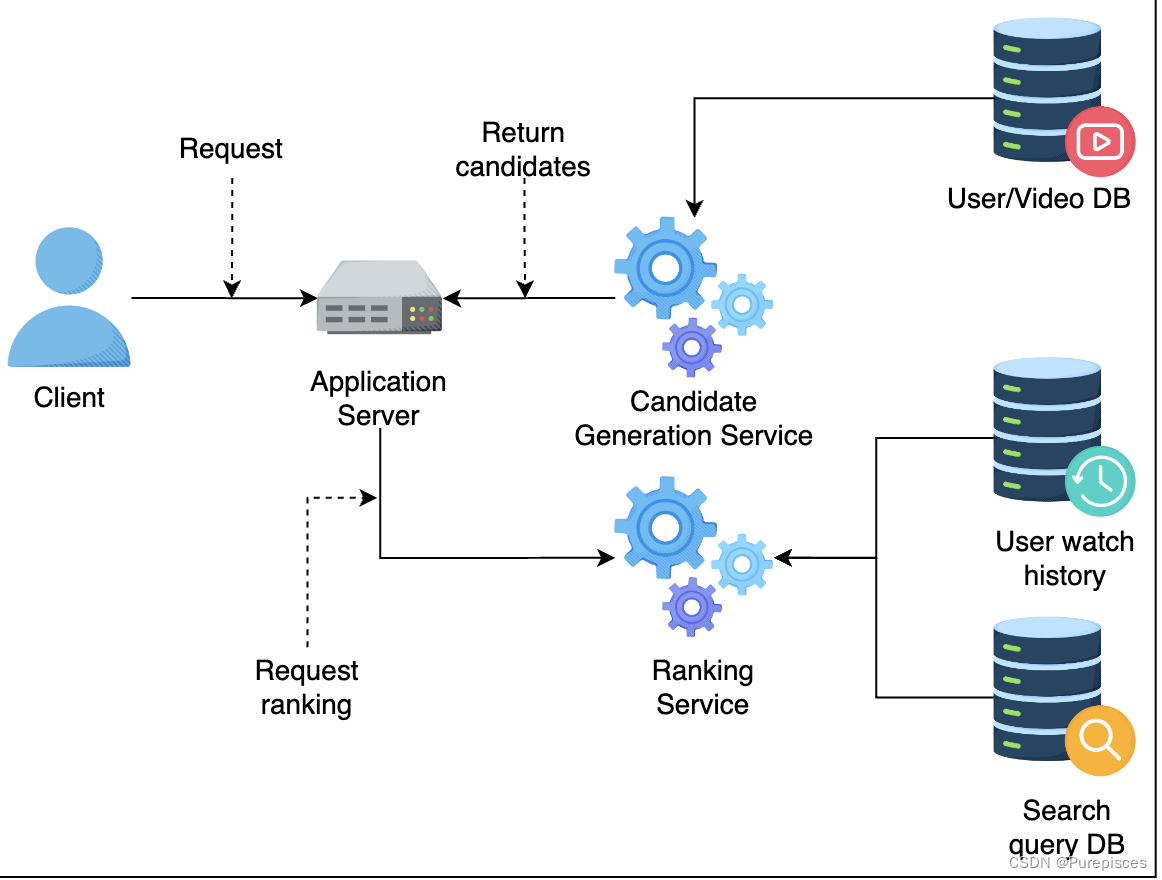
用户向应用服务器发送视频推荐请求。
-
应用服务器向候选生成服务发送推荐请求。
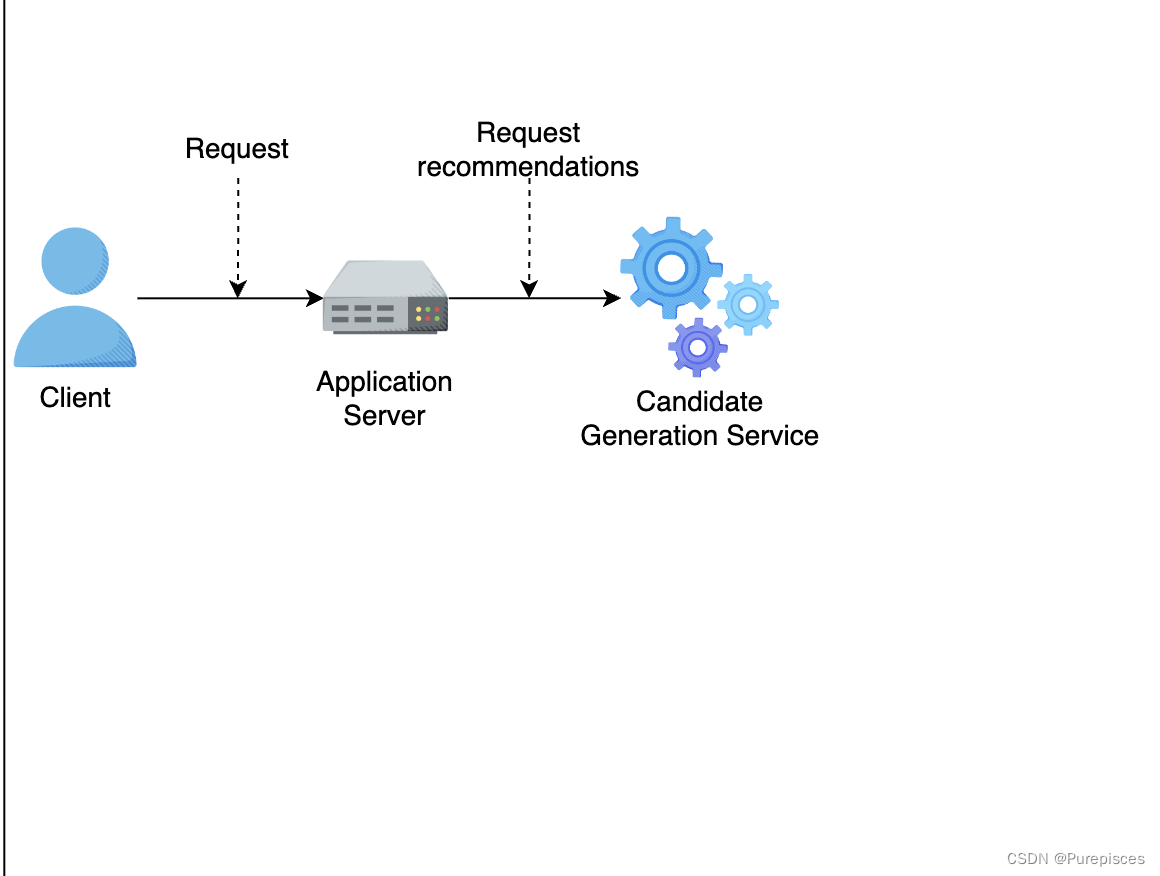
-
候选生成服务从数据库获取用户元数据和视频。
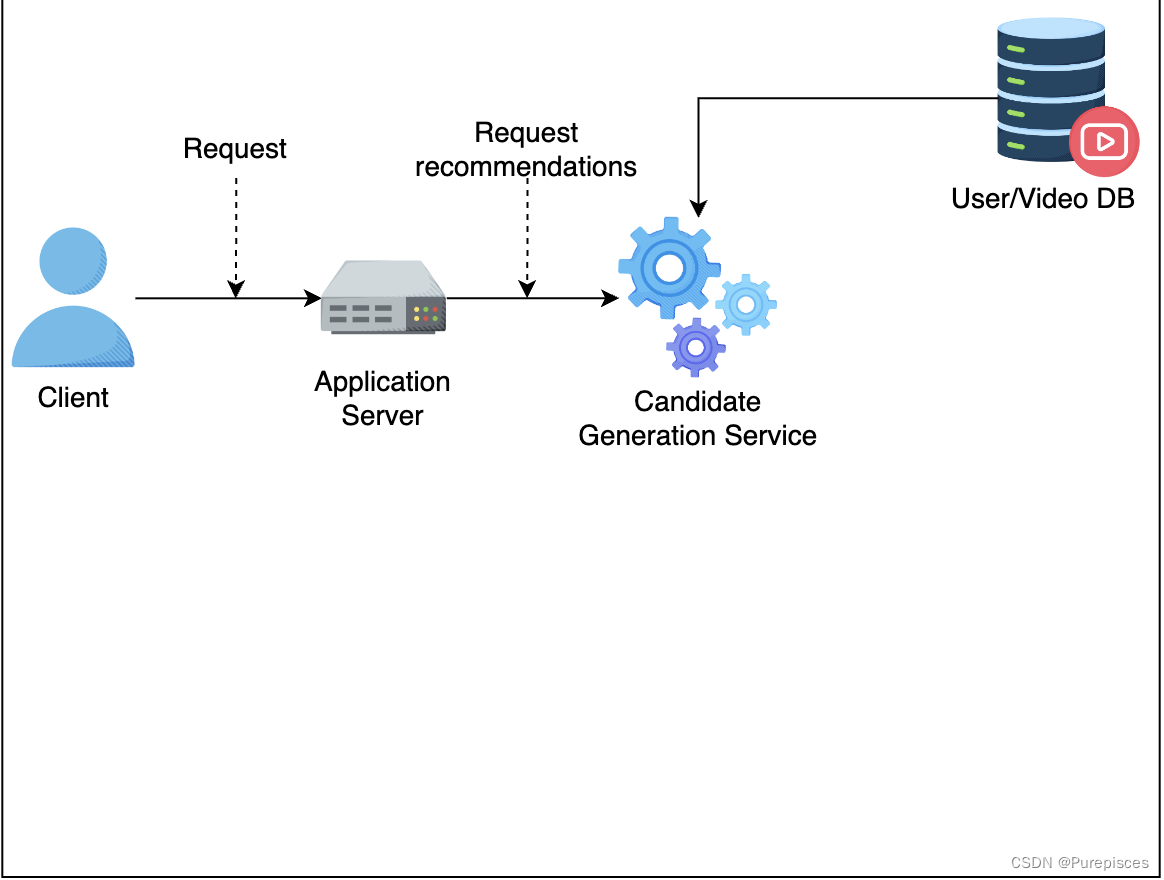
-
候选生成服务返回视频候选列表给应用服务器。
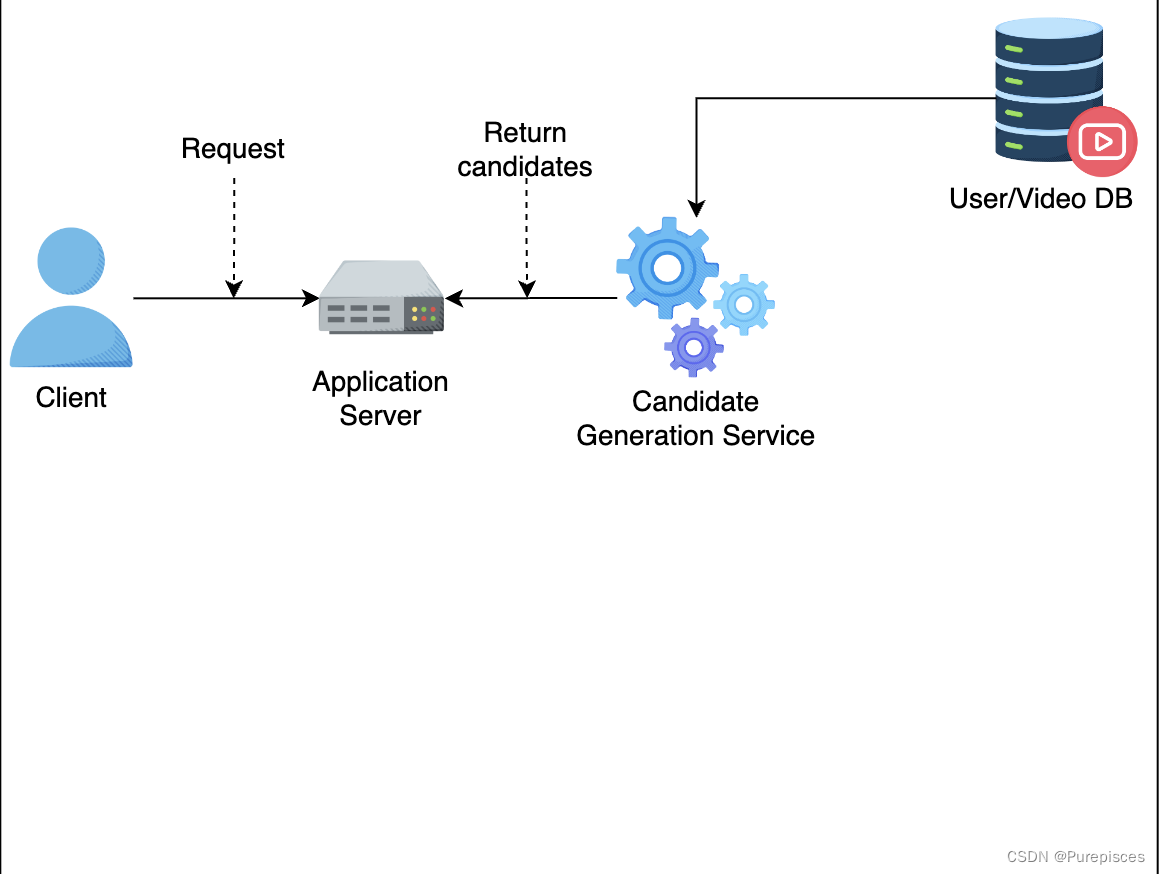
-
应用服务器将候选列表发送到排序服务进行评分。
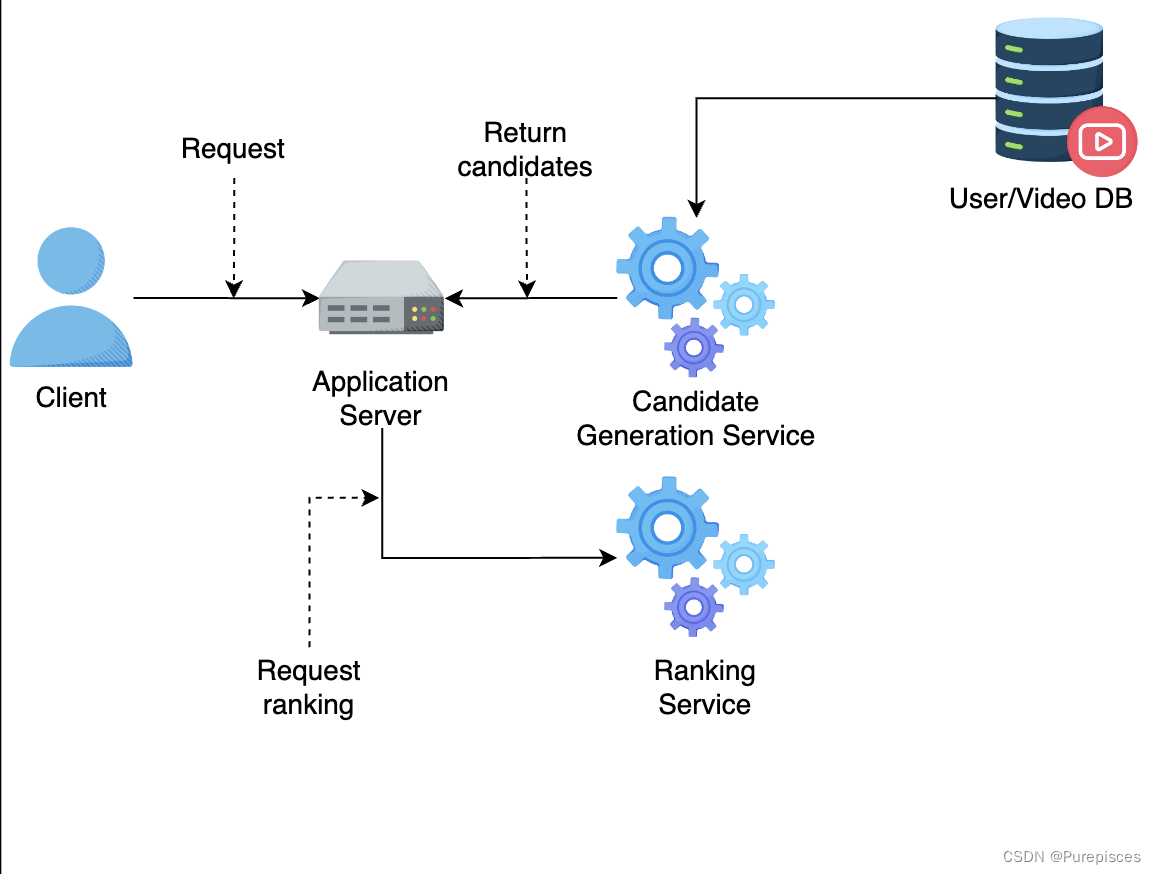
-
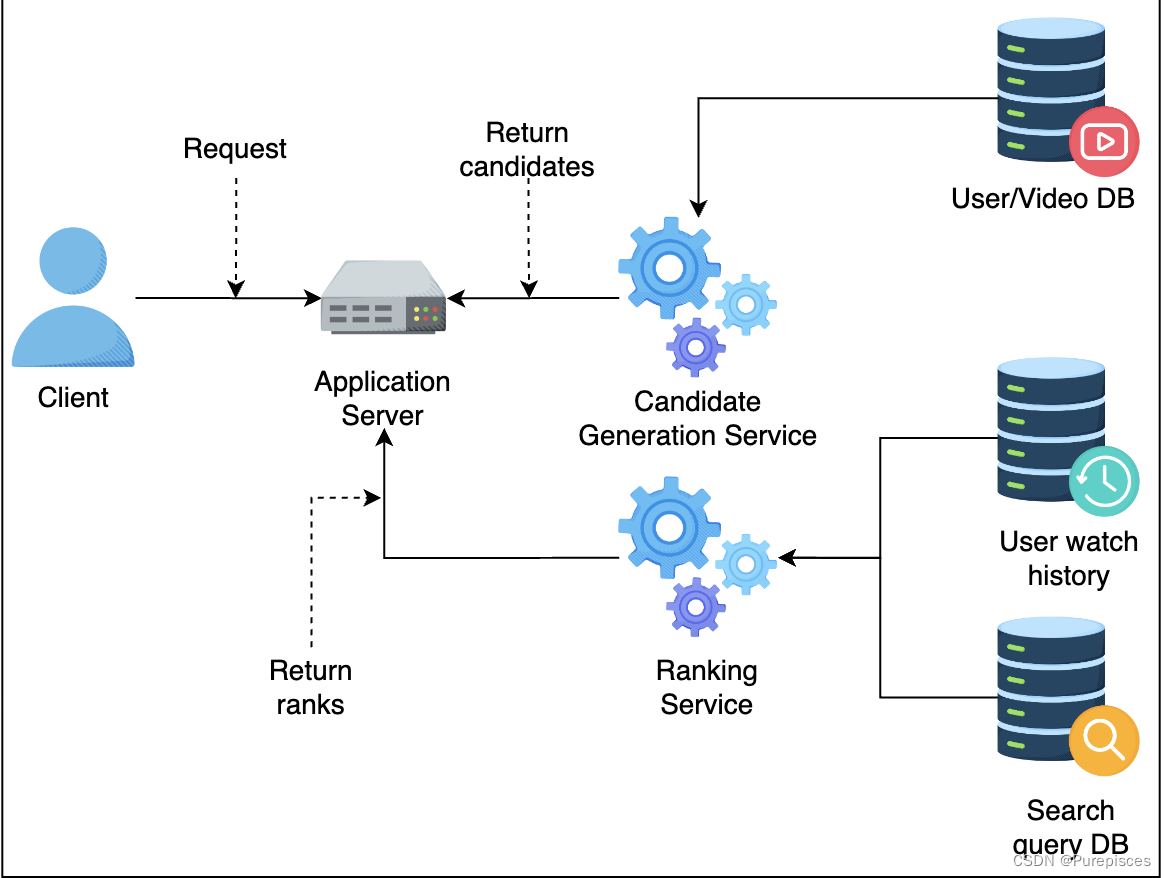
排序服务从数据库获取用户观看历史和用户搜索查询历史。
-
排序服务为每个视频候选评分,并将评分返回给应用服务器。
-
应用服务器选择前100个视频候选并返回给用户。
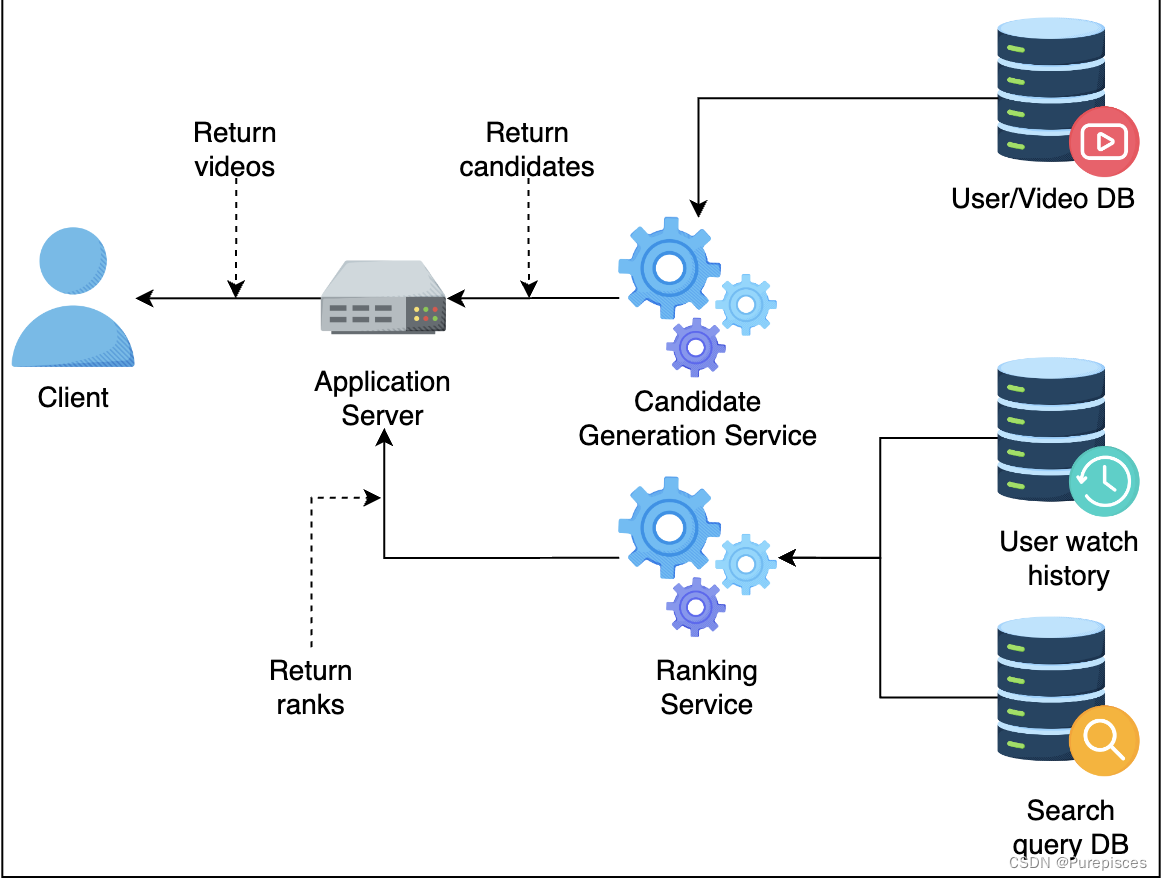
当用户请求视频推荐时,应用服务器向候选生成模型请求视频候选。一旦收到候选列表,它会将候选列表传递给排序模型以获取排序顺序。排序模型估计观看概率并将排序列表返回给应用服务器。然后,应用服务器返回用户应该观看的顶级视频。
6. 扩展设计
- 横向扩展多个应用服务器,并使用负载均衡器来平衡负载。
- 横向扩展多个候选生成服务和排序服务。
通常会将这些服务部署在Kubernetes Pod中,并利用Kubernetes Pod Autoscaler自动扩展这些服务。
实际上,我们还可以使用Kube-proxy,使候选生成服务可以直接调用排序服务,从而进一步减少延迟。
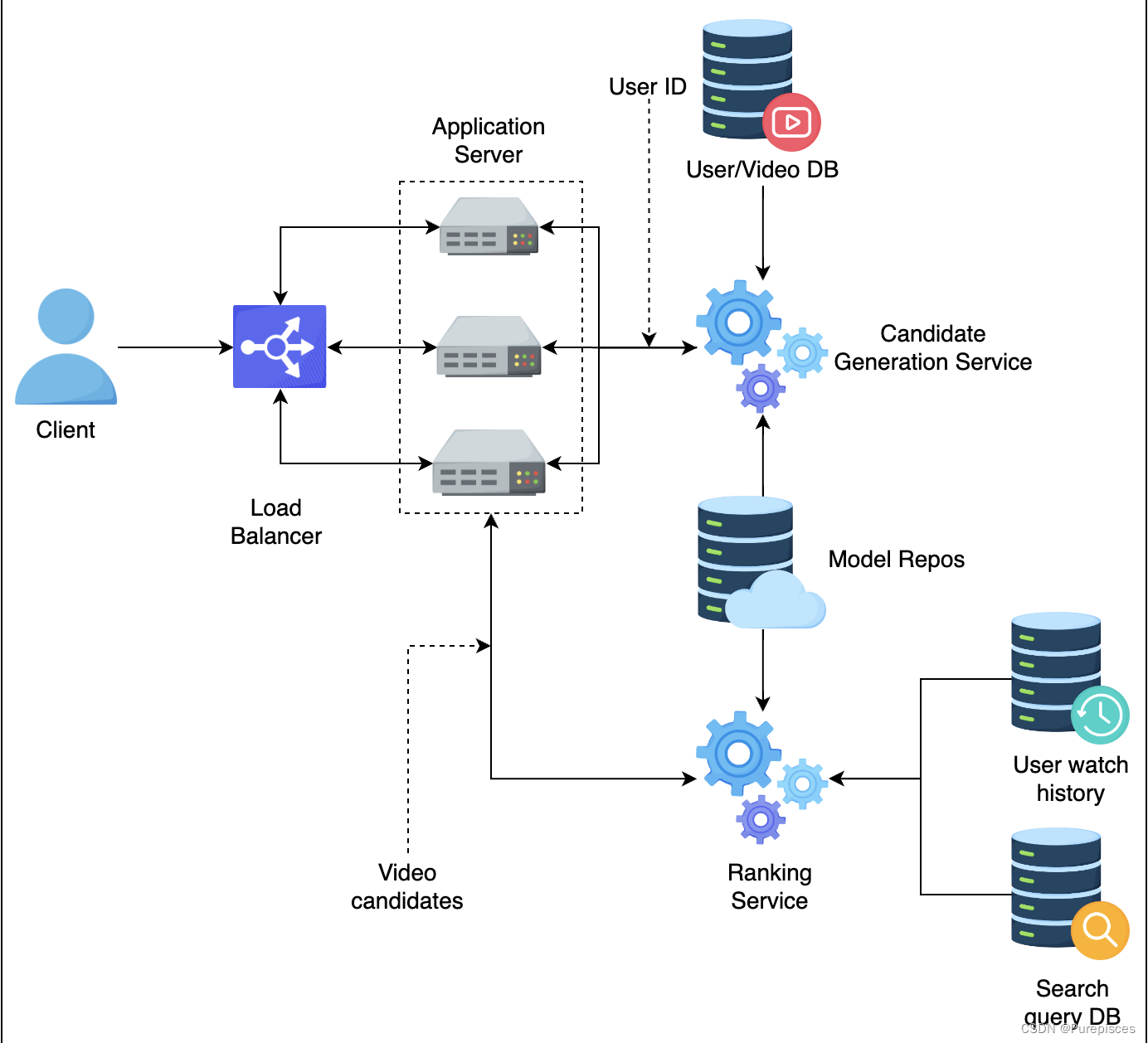
- 横向扩展(Scale Out):增加服务的实例数量。例如,不是使用一个具有16GB RAM的服务器,而是使用四个具有4GB RAM的服务器。通常提供更好的容错性,因为多个实例意味着如果一个实例失败,其他实例可以接管。在云环境中可能更具成本效益,因为较小的实例可能比单个大实例更便宜。
- 纵向扩展(Scale Up):增加单个实例的资源。例如,将服务器从8GB RAM升级到16GB RAM。在容错性方面可能更有风险,因为如果单个实例失败,则没有备份实例。可能会达到一个极限,在添加更多资源变得非常昂贵或技术上不可行。
负载均衡器是一个系统,它将传入的网络流量分配到多个服务器或实例,以确保没有单个服务器负载过重。
7. 后续问题
我们如何适应用户行为随时间变化?
- 进一步了解多臂强盗算法。
- 使用贝叶斯逻辑回归模型,以便我们可以更新先验数据。
- 使用不同的损失函数,以减少对点击率等的敏感性。
多臂强盗算法:
- 解释:多臂强盗算法用于平衡探索和利用。它们有助于根据用户互动动态调整推荐,以最大化长期回报。
- 例子:想象你有多个视频推荐可供选择。多臂强盗算法将帮助你在初期探索不同的推荐,然后利用那些表现最佳的推荐,并随着时间的推移不断学习和适应用户偏好的变化。
贝叶斯逻辑回归模型:
- 解释:贝叶斯逻辑回归结合了先验知识,并在有新数据到来时更新这些知识。该模型特别适用于用户行为可能变化的场景,因为它允许连续学习和更新。
- 例子:假设你有关于用户偏好的先验数据。当发生新的用户互动时,贝叶斯逻辑回归模型会更新先验数据,优化推荐以更好地匹配当前的用户行为。
不同的损失函数:
- 解释:使用不同的损失函数可以帮助模型减少对某些指标(如点击率)的敏感性。这在试图捕捉长期用户参与度而不仅仅是短期点击时非常有用。
- 例子:与其专注于最大化点击率,不如使用一个平衡点击率与其他指标(如观看时间或用户满意度)的损失函数,从而提供更符合用户长期兴趣的推荐。
我们如何处理排序模型的探索不足?
我们可以在排序服务中引入随机化。例如,2%的请求将获得随机候选,而98%的请求将获得排序服务返回的排序候选。
8. 总结
- 我们首先学习了将推荐系统分为两个服务:候选生成服务和排序服务。
- 我们还学习了使用深度学习全连接层作为基线模型,以及如何处理特征工程。
- 为了扩展系统并减少延迟,我们可以使用kube-flow,使候选生成服务可以直接与排序服务通信。
附录
这是一个很好的问题!让我们澄清一下为什么我们使用矩阵分解来生成预测评分矩阵 (R’),而不是直接使用原始的交互矩阵 ® 进行预测。
使用矩阵分解的关键原因
原始矩阵的稀疏性
- 原始交互矩阵 ® 通常非常稀疏。这意味着大多数用户只观看或评分了总可用视频中的一小部分。例如,在一个大型视频流媒体平台上,一个用户可能只观看了几打视频,而平台上有数百万个视频。
- 矩阵分解通过识别用户和项目之间的模式和相似性来填补这些缺失值。这使我们能够预测用户尚未观看的视频的交互。
潜在因子
- 矩阵分解将交互矩阵分解为捕捉用户偏好和视频特征的潜在因子。这些潜在因子可以表示诸如用户对某些类型或主题的偏好等抽象概念,这些在原始数据中是不可直接看到的。
- 通过学习这些潜在因子,模型可以概括并对未见过的交互进行更准确的预测。
降维
- 原始交互矩阵可以非常大,其维度等于用户数量乘以视频数量。矩阵分解将其减少到低维表示,使得计算效率更高。
稀疏矩阵示例
让我们回顾一下简化的例子:
原始交互矩阵 ®:
| 视频 1 | 视频 2 | 视频 3 | |
|---|---|---|---|
| 用户 1 | 5 | 3 | 0 |
| 用户 2 | 4 | 0 | 0 |
| 用户 3 | 1 | 1 | 0 |
注意,许多条目是零,表示这些交互是未知的。
预测评分矩阵 (R’)(矩阵分解后):
| 视频 1 | 视频 2 | 视频 3 | |
|---|---|---|---|
| 用户 1 | 4.8 | 3.1 | 2.0 |
| 用户 2 | 4.1 | 2.5 | 1.7 |
| 用户 3 | 1.2 | 1.1 | 0.9 |
- 用户 1 和 视频 3:在原始矩阵 ® 中,我们没有用户 1 对视频 3 的评分。然而,在预测矩阵 (R’) 中,我们有一个预测评分 2.0,这表示基于潜在因子的估计偏好。
- 填补空白:预测矩阵为所有用户-视频对提供了评分,包括那些在原始矩阵中未明确评分的。
为什么不直接使用 R?
- 不完整的数据:原始矩阵 ® 对许多用户-视频对缺乏信息。直接使用它意味着我们无法为用户未交互过的视频提供推荐。
- 偏好的发现:矩阵分解揭示了从稀疏数据中无法直接看出的隐藏模式和偏好。
- 概括能力:它允许模型从已知交互中概括,预测未知的交互,提高推荐质量和用户体验。
总之,矩阵分解利用不完整的交互数据生成全面的预测评分集,使推荐系统能够为用户尚未观看的视频提供相关的推荐。
矩阵分解与SGD的工作原理
初始化:
- 最初,用户和物品矩阵用随机值填充。这些矩阵代表用户和物品的潜在因子。矩阵的维度取决于我们选择使用的潜在因子的数量。
优化:
- 该算法通过迭代调整这些值,以最小化观测交互(原始矩阵R)和预测交互(预测矩阵R’)之间的差异。
学习潜在因子:
- 用户矩阵 (U):用潜在因子表示用户。
- 物品矩阵 (V):用潜在因子表示物品(视频)。
分解可以用数学公式表示为:
R ≈ U × V T R \approx U \times V^T R≈U×VT
其中 U U U 是用户矩阵, V V V 是物品矩阵, R R R 是交互矩阵。
优化过程
目标是最小化重建误差,即观测评分(在R中)和预测评分(在R’中)之间的差异。通常使用均方误差(MSE)作为损失函数:
Loss = ∑ ( i , j ) ∈ observed ( R i j − ( U i ⋅ V j ) T ) 2 + λ ( ∣ ∣ U ∣ ∣ 2 + ∣ ∣ V ∣ ∣ 2 ) \text{Loss} = \sum_{(i, j) \in \text{observed}} (R_{ij} - (U_i \cdot V_j)^T)^2 + \lambda (||U||^2 + ||V||^2) Loss=(i,j)∈observed∑(Rij
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









