









范雪雪 1 王志荣 1 徐 晤 1 梁 银 2 马小虎 3
1
(徐州医学院临床学院 徐州 221004)
https://kns.cnki.net/reader/flowpdf?invoice=q5lRWqDSFtSb9lYCdj54HrIZ4cA57vDU%2BJd4feWODw0Q%2FuwemZzte9PntM%2BaghAOM1SU5KOQjy9B1s%2FNRY3WpL1ua%2FhRaS%2FzrwWlZz4%2F5RPe6nnJrUmfHlpYdbNfM%2FD%2FMSHqvJ7M8O2%2FIGPkXYphXtOta4I0jHjEjBcfIjLDwHk%3D&platform=NZKPT&product=CJFQ&filename=XDTQ201512013&tablename=cjfdlast2016&type=JOURNAL&scope=trial&dflag=pdf&pages=&language=CHS&trial=&nonce=7F2AEEA8631246DF9FA2FC24066EBF1B&cflag=pdf
摘要: 【目的】借助大型的医学本体, 提升医学术语相似度计算精度。
【方法】依据 SNOMED CT 和 MeSH 两个医学本体的层级结构和语义关系, 提取概念术语的深度、距离等语义参数, 并用概念密度对其加权得到深度系数和距离系数, 构造相似度函数进行术语相似度计算。
【结果】该算法能在两个医学本体中进行术语相似度计算, 较传统算法更加接近人工评分标准。【局限】该方法较为依赖本体结构。
【结论】该方法能够提高以医学本体为基础的术语相似度计算精确度。
关键词: 语义相似度 医学术语 医学本体 SNOMED CT MeSH
分类号: TP391 G351
引 言
词语语义相似度计算是自然语言处理的一项基础性工作, 在信息检索[1]、词义消歧[2-3]、机器翻译[4]、自动问答、信息提取[5]、文本分类和聚类[6-7]、语义标注等领域有广泛的应用。在医疗领域, 随着全民电子健康记录和电子病历等信息技术在医疗领域的大规模应用, 提高海量医疗文本资源的检索效率和利用率成为一项重要的研究课题。医疗术语相似度计算对于提高医疗文本资源的检索、聚类和挖掘的效率具有重要意义[8-9]。在传统的数字图书馆领域, 语义检索还是要借助交互式的术语提示来实现概念之间的检索, 而不考虑概念之间的其他属性关系, 检索结果往往不能满足用户需求[10]。基于本体的语义相似度计算可以解决这个 问 题 。 医 学 系 统 命 名 法 – 临 床 术 语 (SystematizedNomenclature of Medicine-Clinical Terms, SNOMEDCT)和医学主题词表(Medical Subject Headings, MeSH)是目前世界上应用最为广泛的医疗领域术语表和主题词表, 它们都拥有庞大的概念术语集和复杂的结构。
我国医学界也对这两个本体进行了大量的研究, 但以它们为基础的术语语义相似度计算研究还不够充分,计算方法往往直接移植自基于通用本体的方法, 缺少针对性, 计算精度不高, 且在不同本体中计算结果差异较大, 无法满足需求。本文依据本体的结构特征和概念间的语义关系,将概念的语义距离、语义深度和密度等语义特征进行融合, 提出深度系数和密度系数的概念并采用加权的方法进行计算, 最后构造了新的相似度计算函数。
在实验阶段, 以 Pedersen 和 Hiaoutakis 两种评估标准进行测试, 结果表明本文提出的算法与传统算法相比和人工评分有更高的相关系数, 且在两本体中的计算结果接近, 能够在一定程度上弥补本体未收录术语问题。
2 相关研究
词语语义相似度(Semantic Similarity)是指词语在分类上的相似程度, 在本体中一般表现为具有上下义关系。比如心脏病和心肌梗死。此外, 词语之间还存在 着 其 他 更 为 广 泛 的 关 系 , 叫 做 词 语 语 义 相 关 度Semantic Relatedness)。如硝酸甘油有助于治疗心绞痛, 它们具有相关度而不存在上下义关系。相似度是相关度的一种特殊情况[11] , 本文主要对相似度进行研究。
词语语义相似度算法可根据背景知识的来源不同分为两种类型: 一种是基于语料库的方法, 这类方法
以非结构化或者半结构化的文本语料(如病人的电子病历等)、Web 网页等为基础, 用统计学的方法计算出词语的分布特征并构造相似度函数[12-15] ; 另一种是基于本体(Ontology)的方法, 通过本体中概念之间的关系、属性或者层级结构对词语进行相似度计算[11-12]。前者对语料库要求很高, 数据稀疏和词语歧义问题严重影响计算精度。后者基于本体, 概念之间语义逻辑关系清晰, 但也存在较为依赖本体的问题。随着 SNOMEDCT、MeSH 等医学本体越来越完备, 为基于本体的医学术语相似度计算的研究奠定了坚实的基础。
基于本体的语义相似度算法按照计算理论的不同可以分为 4 种类型: 基于信息量(Information Content,IC)的方法、基于语义距离的方法、基于属性的方法、混合方法。
Lord 等[16]和 Resnik[17]提出以概念最近公共祖先节点(Least Common Subsume, LCS)的信息量度量词语语义相似度, 但该算法对所有拥有相同祖先的概念计算出的相似度都相同。Lin[18] 和 Jiang 等[19] 在Resnik 的基础之上提出改进, 但算法精度受语料库影响较大。近年来, 有学者提出基于纯本体信息量的算法[20-22] , 但由于不能充分体现概念之间的语义关系,精度受到影响[11]。
基于语义距离的算法首先由 Rada等[23]提出, 将本体看做一个由概念组成的语义网, 提出用概念节点之间的最短距离来计算相似度。
Leacock等[24]和 Wu 等[25]对 Rada 等的方法进行改进, 尽管该种算法理论简单, 但是精度不高[11]。
基于属性方法则是直接通过概念属性的重合程度进行计算, 代表方法如文献[26-29]。该类方法是一种将相似度和相关度混合计算的方法, 但由于没有充分利用本体结构信息, 计算结果精确度受到限制[11]。
混合算法是以上三种方法的综合考虑, 具有代表性的是 Li 等[30]提出的方法。由于充分利用了概念的语义信息, 该类方法近年来涌现出大量的研究成果[11]。以上算法大部分都是基于通用本体, 由于通用本体只包含了非常有限的医学词汇,因此直接应用到医学本体中会受到限制。
3 基于医学本体的相似度算法
3.1 SNOMED CT 和 MeSH
目 前 , 在 医 学 领 域 使 用 最 为 广 泛 的 本 体 包 括SNOMED CT 和 MeSH。SNOMED CT 2014 版涵盖311 000 多条活跃概念, 它包含 1 个根概念和 19 个顶层概念, 每个顶层概念又分为若干子层, 概念从一般到具体逐级分类, 形成层级结构。SNOMED CT 的核心是概念, 每个概念具有唯一的标识符、名称和概念描述。其中, 概念描述包括一条首选术语和一条或多条同义词。概念和术语之间形成一对多的关系。概念之间通过“关系”逻辑被形式化地组织在层级结构中。
在 SNOMED CT 中存在很多种关系, 其中最重要的就是上下义关系, 其他还有概念模型属性关系等。
MeSH则将主题词按照范畴和学科属性将它们划分为 16 个大类, 每个大类再层层划分, 逐级展开。在 MeSH 中,每个主题词都拥有唯一的标识符和一个主题词详解,拥有一个或多个入口词(可以理解为同义词)。每个主题词都按照分类和逻辑关系安排在树形结构的某一节点上, 上下义关系也是 MeSH 中最主要的关系。
3.2 基于本体的相似度计算
在本体中, 概念之间的相似程度可以利用它们在层级结构中的距离、深度和所处部分的密度等参数衡量。一般来说, 概念间的距离和它们的相似度成反比,距离越小则概念之间的相似度越高; 对于语义距离相同的两个概念来说, 其所处位置越深, 表示概念越具体, 相似度越高; 所处区域的密度越大, 表示概念细化程度越大, 相似度越高[11-12, 23-25, 30-31]。
本文算法也采用了上述语义参数, 并进一步提出深度系数、距离系数的概念和计算方法, 同时提出以密度作为参数对语义距离和语义深度进行加权, 最后构造了新的术语相似度计算函数。
定义 1 深度系数。若概念 c1, c2 的最近公共祖先节点(LCS)在本体中的深度为 dept(lcs), 经过 LCS 和两概念节点的路径的长度分别为 dept(t)1 和 dept(t) 2, 令
dept(t) = max[dept(t)1, dept(t) 2], dept(lcs)与 dept(t)的比值定义为深度系数, 记为 depf(LCS(c1, c2)), 可表示为:
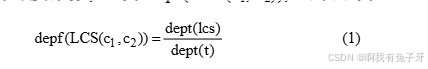
定义 2 距离系数。令从概念 c1 到 c2 且经过它们最近公共祖先节点的最短路径的长度为 path(c1, c2),
若 path(c1, c2 )≠0, 则定义距离系数为 path(c1, c2)的倒数, 用 q 表示, 即 q=1/path(c1, c2)。当 path(c1, c2 )=0 时,表示 c1 , c2 完全相同。概念节点所在区域的密度也会影响相似度, 表现
如图 1 所示:
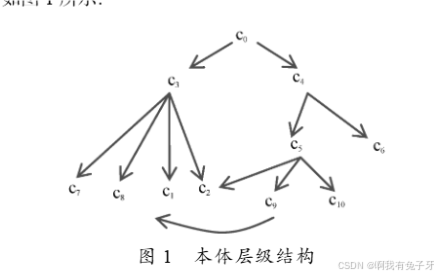
若不考虑密度因素, 概念 c1, c2 和 c5, c6 的深度和距离相等, 相似度应该相等。但因 c1, c2 所处区域概念密度大, 其相似程度应该大于 c5, c6。这种现象映射到边上就是密度大的区域其概念对应边的长度应该小于密度小的。同样, 深度对相似度的影响映射到边上就是层次较深的概念对应的边的长度应该小于深度浅的。为此,本文构造权值函数来满足以上要求。若



其中, 公式(4)中的分母对应公式(1)中的 dept(t),
为其不加权的长度 m2。
在本体中概念是不存在歧义的, 但是由于概念存
在多种不同的分类, 往往存在多继承的情况。如图 1
所示, 概念 c1, c2 继承自 c3 和 c5 两个最近公共祖先节点
(LCS), 但两个 LCS 在本体结构中所处的深度不同, 最
短路径也不相同。由于缺乏具体语境, 本文认为这些
情况出现的概率是相同的, 因此对各种情况的相似度
进行平均。
若概念 c1, c2 存在 n 个最近公共祖先节点, 则它们
就存在 n 个深度系数。根据深度系数的概念, 选取几
种情况下长度最长的 dept(t)用 dept(t) max 表示(如图 1 中
的 dept(t) max 即为路径(c0 c4 c5 c9 c1)的不加权长度)。则
概念 c1, c2 的

[dept(lcs)]=1, 则二者不相似。
同样地, 若概念 c1, c2 存在 n 个最近公共祖先节点,
则它们就存在 n 条最短路径, 其中第 i 条最短路径的加
权长度用 path(c1, c2) i 表示, 距离系数用 q i 表示。
综合以上


本文讨论的是概念的相似度, 但为了与更多的算法比较, 对于仅具有相关度而不具有相似度的概念,
借鉴文献[27-29]的方法: 分别搜索 c1 和 c2 的概念描述或者相关概念中是否出现另外一个概念, 若出现,则判断二者是相关词, 且令其相似度为一定值。根据两本体结构特点和人工评分结果, 取该定值为 3。
由于本文算法的主要运算是查找运算和简单的线性运算, 且多为一次性运算, 仅仅在计算权值时使用
简单的迭代。整个算法仅依赖本体局部结构信息, 且不需要反复遍历整个本体, 算法时间复杂度较低。
4 实验结果和分析
4.1 实验方案
对算法精度评价的方法一般是将算法结果与人工评分相比较。在医学领域有 Pedersen 等[32]和 Hiaoutakis等[33]创建的两种评估标准。前者是由 Pedersen 和梅奥诊所(Mayo Clinic)的医师们合作, 组织 9 名医学编码员和 3 名医学专家分成两个小组, 对 30 对术语进行评分, 1 表示不相似, 4 表示完全相同。该评估标准和SNOMED CT 能准确地比较出评估结果, 近年来已经成为医学界应用最为广泛的评估标准[20-21, 32, 34-35]。
Hiaoutakis 等[33]的评估标准是从 MeSH 中选出 36 对术语, 由 8 位医学专家进行人工评分, 0 表示不相似, 1 表示完全相同。本文首先实现了上述算法, 以 SNOMEDCT 2014 和 MeSH 2014 作为本体, 对这两种评估标准中的术语进行相似度计算, 并与常用算法进行比较。
4.2 实验结果
(1) 与 Pedersen 评估标准比较
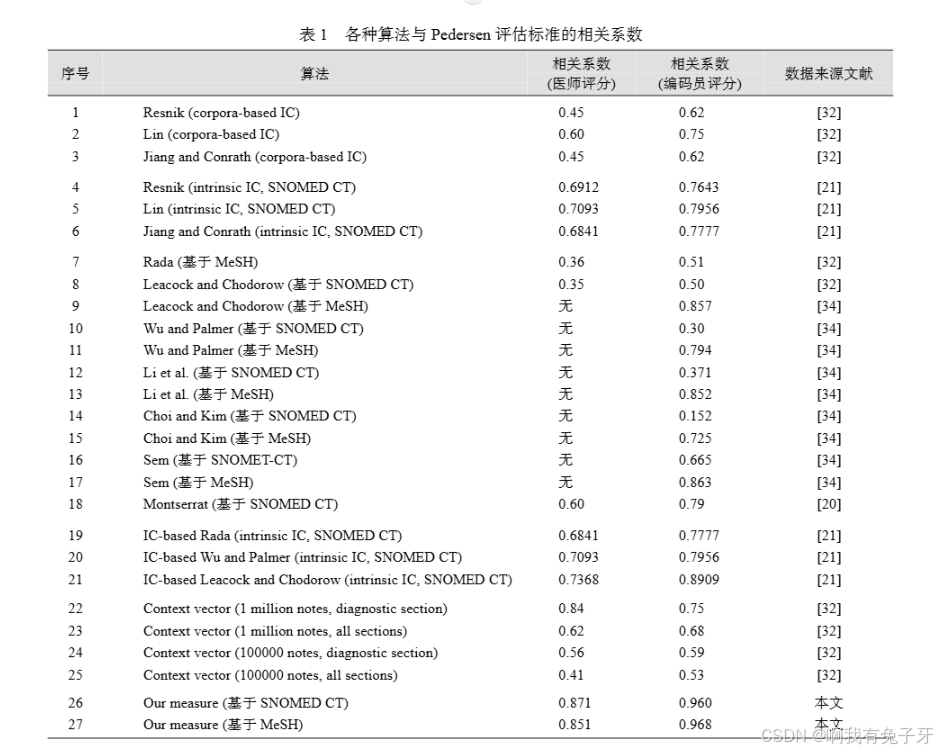
Pedersen 评估标准共有 30 对术语, SNOMED CT2014 中收录了 29 对, MeSH 2014 中收录了 25 对。对于未收录的术语, 文献[34]的处理方法是在本体中找到与其最为相近的概念代替, 然后再进行相似度计算。参考这种做法, 本文最终计算了 29 对术语的相似度。由于两本体结构存在很大差异, 经实验, α、β 在SNOMED CT 中取值为 α=1, β=1, 在 MeSH 中取值为α=0.8, β=0.8 时结果最接近人工评分。一般采用皮尔逊相关系数衡量各种算法的效果, 将文献[20-21, 32, 34]中测评的算法及本文算法同 Pedersen 评估标准的相关系数进行比较, 结果如表 1 所示。
表 1 囊括了目前大部分常用的词语相似度和相关度算法。其中基于本体的方法均以 SNOMED CT 或MeSH 作 为 本 体 , 基 于 语 料 库 方 法 均 使 用 MayoClinical Corpus of Clinic Notes[32]
(MCCCN)语料库, 因此具有可比性。
其中, 第 1-3 行是经典的基于信息量的算法, 第 4-6 行是基于纯本体信息量的算法, 第 7-18
行是基于语义距离的算法和混合算法, 第 19-21 行是基于信息量的语义距离改进算法。第 22-25 行是基于内容向量的方法, 这是一种基于语料库的方法。其中第 22、24 行所用语料选自于 MCCCN 语料库的诊断术语部分, 选取规模分别为 100 万条和 10 万条词语,第 23、25 行选自整个语料库, 规模与前者相同。第26-27 行是本文提出的算法。
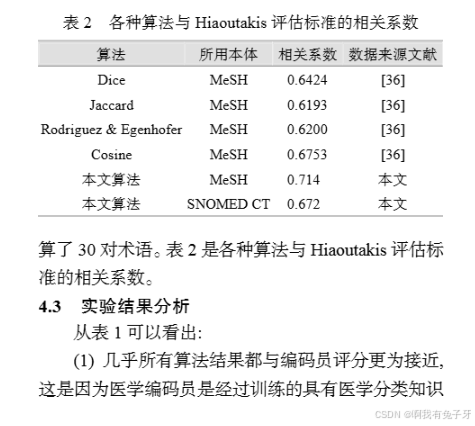
(2) 与 Hiaoutakis 评估标准比较
Hiaoutakis 评估标准中包含 36 对从 MeSH 中挑选的概念术语, 由人工从 0-1 进行打分。文献[36]选取其中的 32 对术语并列举了以 MeSH 为本体的 Dice,Jaccard, Rodriguez & Egenhofer 以及 Cosine 算法的计算结果。笔者同样选用这 32 对术语并首先以 MeSH为本体进行计算。此外, 也以 SNOMED CT 作为本体进行了计算, 但由于其中有两对术语未被收录且无相概念可代替, 因此在以 SNOMED CT 为本体时仅计
从表 1 可以看出:
(1) 几乎所有算法结果都与编码员评分更为接近,这是因为医学编码员是经过训练的具有医学分类知识的专业人员, 对于医学词汇的分类能做到更加客观准确, 文献[34]则只与编码员评分结果进行比较。
(2) 经典的基于信息量的算法(第 1-3 行)和基于语料库的算法(第 22-25 行)受语料库的规模和专业程度影响较大。
(3) 经典的基于距离的方法与混合算法(第 7-18行)在不同的本体中表现差异较大, 尤其在 SNOMED
CT 中表现不佳。
(4) 改进的基于纯本体信息量算法(第4-6行, 第19-21行)比经典信息量算法表现有所提升, 这从一个
方面说明基于领域本体的方法精确度优于基于语料库的方法。
(5) 本文算法(第 26-27 行)在两个本体中均能得到更高的相关系数且结果相近, 两本体结果相关系数为0.978(见本篇论文网络版本支撑数据), 这说明本文算法具有更高的精确度与更好的通用性。
从表 2 可以看出, 由于评分专家采用的标准和打分区间的不同, 本文算法计算结果与人工评分有一定差异, 但从相关系数值可以看出本文算法较其他算法在以 MeSH 为本体时计算结果更加接近人工标准。对于 SNOMED CT 而言, 由于目前还没有以之为本体的30 对术语相关测评结果因而无法进行比较, 但本文算法在两本体中计算结果的相关系数为 0.983(见本篇论文网络版本支撑数据)。
5 结 语
本文提出一种基于复杂医学本体的术语相似度算法。该算法依据医学本体的结构特征, 运用加权的深度系数、距离系数等语义特征变量计算医学术语相似度。采用 Pedersen 评估标准和 Hiaoutakis 评估标准并分别以 SNOMED CT 和 MeSH 为本体进行测试, 该算法得到了比传统算法更高的相关系数, 同时也证明了该算法能够运行在 SNOMED CT 和 MeSH 两个本体中, 且表现较为相近, 能够在一定程度上弥补单一本体中因未收录术语而无法进行计算的问题。由于该算法依赖本体结构, 当本体结构发生改变时, 需要重新计算。但该算法中的运算多为线性运算, 且不存在反复遍历本体的问题, 能够较为快速地重新完成计算。由于任何一个单独的本体都无法收录所有术语, 如果能够联合不同的本体(包括一般领域本体)进行术语相似度计算, 则能够在更大程度上解决未收录术语的问
题, 这是今后需要进一步研究的工作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









