









前言
并查集一般用于多元素,多集合的查找问题;
听说很有用,但是平时好像确实没有怎么见过。。
leetcode典型例题:岛屿数量
一、原理
- 其实并查集的每个小集合就是一张有向图,只不过是所有子节点指向父节点的图结构。
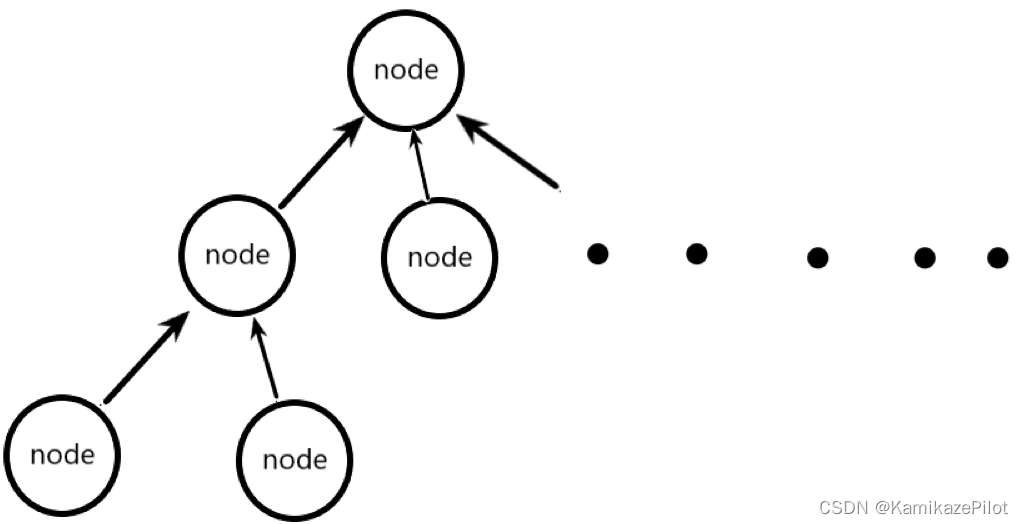
他之所以能够高效的合并和查找,是因为它在查找过程中,一直在动态更改所有走过节点的父节点。
主要结构:
这里先定义一个节点结构:
template<class T>
class EleNode
{
public:
T value;
EleNode<T>* father;
EleNode(T val)
{
value = val;
father = nullptr;
}
};
- 该节点结构非常类似于链表
只不过它里面存的指针指向自己的爸爸
主结构中:
nodeMap根据用户数据存储对应节点数据,所有被创建出来的节点都被存放在里面numMap仅用于记录该集合的元素数量(只记录头部元素,因为这个数据只需要一条)void createNode(T val)函数中,创建节点需要在nodeMap和numMap中初始化
template<class T>
class UnionFindSet
{
//节点记录
unordered_map<T, EleNode<T>*> nodeMap;
//元素集数量记录
unordered_map<EleNode<T>*, int> numMap;
public:
UnionFindSet(){}
//构造函数
UnionFindSet(const vector<T>& list)
{
for (int i = 0; i < list.size(); i++)
{
createNode(list[i]);
}
}
//销毁节点
~UnionFindSet()
{
for (auto ele : nodeMap)
{
delete ele.second;
}
}
// 新建一个节点
void createNode(T val)
{
if (nodeMap.find(val) != nodeMap.end()) return;
EleNode<T>* newNode = new EleNode<T>(val);
nodeMap.insert(make_pair(val, newNode));
numMap.insert(make_pair(newNode, 1));
}
}
主要方法:
有三个方法,分别为:
// 判断是否在同个集合中
bool isSameSet(const T& v1, const T& v2);
// 执行联合,即合并节点
void doUnion(EleNode<T>* t1, EleNode<T>* t2);
//找头节点
EleNode<T>* findHead(EleNode<T>* node);
- 判断是否在同个集合中
判断两个节点的头节点是不是同一个。
为啥要找到头节点?
其实根据刚才的那张图就很显而易见
- 如果两个节点在同一个集合中,那么他们两个一直执行查找父亲的操作;最后绝对能找到同一个头节点
- 如果两个节点不在同集合中,那么执行该操作过后;最后绝对找到不同的头节点
// 是否为同个集合
bool isSameSet(const T& v1, const T& v2)
{
assert(nodeMap.find(v1) != nodeMap.end() && nodeMap.find(v2) != nodeMap.end());
return findHead(nodeMap[v1]) == findHead(nodeMap[v2]);
}
- 合并节点
- 将节点数量较小的那个集合,它的头部节点的指针指向节点数量较大集合的头节点。
这实际上也是两个图结构的合并。至于为啥要选出节点少的一边,这个跟并查集的优化逻辑有关,放在下面的方法说。
1> 首先判断他们是否已经在同个集合中,在同集合中就跳出。
2> 再分别找到他们两个的集合数量中的较大值和较小值
3> 将数量较小的一方并入数量较大的一方,通过将较小集合头节点的father指向改为较大集合头部
4> 更新集合数量值

- 比如上图中,用户输入2和4时,应该怎么操作?
实际上就是直接将1号指针指向3号。
改完以后:

// 执行联合
void doUnion(EleNode<T>* t1, EleNode<T>* t2)
{
// 判断头节点并保存
EleNode<T>* head1 = findHead(t1);
EleNode<T>* head2 = findHead(t2);
if (head1 == head2) return;
//找较大较小集合
EleNode<T>* big = numMap[head1] >= numMap[head2] ? head1 : head2;
EleNode<T>* small = numMap[head1] >= numMap[head2] ? head2 : head1;
//改头
small->father = big;
//数值更新
numMap[big] = numMap[big] + numMap[small];
numMap.erase(small);
}
public:
// 执行联合外部接口
void doUnion(const T& v1, const T& v2)
{
assert(nodeMap.find(v1) != nodeMap.end() && nodeMap.find(v2) != nodeMap.end());
doUnion(nodeMap[v1], nodeMap[v2]);
}
- 找头节点
- 找头节点的操作不仅仅是找到头部,还包含了一个重要的优化
- 这个优化就是将所有走过的,非头节点全部直接连在头结点上
- 并查集中,一个集合(图)最理想的状态就是所有子节点全部直接指向头节点,这种情况下,从子节点向上寻找头节点的代价是
O(1)
例:从2位置开始,找到集合头部
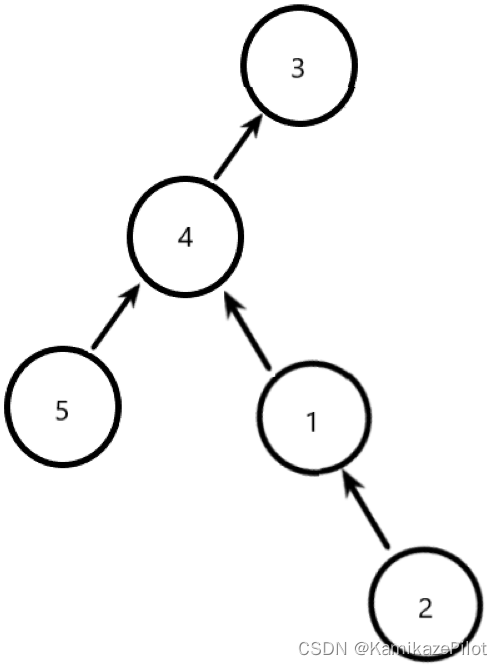
执行后:
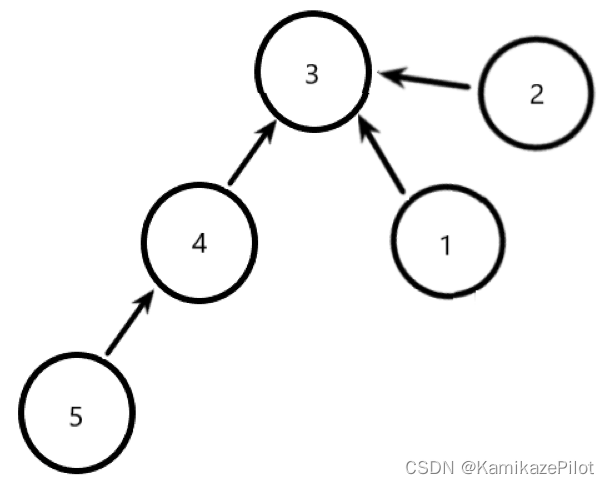
- 此时集合内节点数量未改变不需要调整,只需要调整结构即可
下面的函数中,将所有走过的路径全部压入栈内,并在找到头节点后,挨个将他的父亲改为头节点,最后返回头部。
//找头
EleNode<T>* findHead(EleNode<T>* node)
{
stack<EleNode<T>*> path;
while (node->father != nullptr)
{
path.push(node);
node = node->father;
}
while (!path.empty())
{
path.top()->father = node;
path.pop();
}
return node;
}
二、全部代码
#include<vector>
#include<stack>
#include<unordered_map>
#include<iostream>
#include<cassert>
using namespace std;
template<class T>
class EleNode
{
public:
T value;
EleNode<T>* father;
EleNode(T val)
{
value = val;
father = nullptr;
}
};
template<class T>
class UnionFindSet
{
//节点记录
unordered_map<T, EleNode<T>*> nodeMap;
//元素集数量记录
unordered_map<EleNode<T>*, int> numMap;
//找头
EleNode<T>* findHead(EleNode<T>* node)
{
stack<EleNode<T>*> path;
while (node->father != nullptr)
{
path.push(node);
node = node->father;
}
while (!path.empty())
{
path.top()->father = node;
path.pop();
}
return node;
}
// 执行联合
void doUnion(EleNode<T>* t1, EleNode<T>* t2)
{
EleNode<T>* head1 = findHead(t1);
EleNode<T>* head2 = findHead(t2);
if (head1 == head2) return;
//合并
EleNode<T>* big = numMap[head1] >= numMap[head2] ? head1 : head2;
EleNode<T>* small = numMap[head1] >= numMap[head2] ? head2 : head1;
small->father = big;
numMap[big] = numMap[big] + numMap[small];
numMap.erase(small);
}
public:
UnionFindSet(){}
//构造函数
UnionFindSet(const vector<T>& list)
{
for (int i = 0; i < list.size(); i++)
{
createNode(list[i]);
}
}
//销毁节点
~UnionFindSet()
{
for (auto ele : nodeMap)
{
delete ele.second;
}
}
// 新建一个节点
void createNode(T val)
{
if (nodeMap.find(val) != nodeMap.end()) return;
EleNode<T>* newNode = new EleNode<T>(val);
nodeMap.insert(make_pair(val, newNode));
numMap.insert(make_pair(newNode, 1));
}
// 判断是否在同个集合中
bool isSameSet(const T& v1, const T& v2)
{
assert(nodeMap.find(v1) != nodeMap.end() && nodeMap.find(v2) != nodeMap.end());
return findHead(nodeMap[v1]) == findHead(nodeMap[v2]);
}
// 执行联合外部接口
void doUnion(const T& v1, const T& v2)
{
assert(nodeMap.find(v1) != nodeMap.end() && nodeMap.find(v2) != nodeMap.end());
doUnion(nodeMap[v1], nodeMap[v2]);
}
};
















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











