






Node2Vec【图神经网络论文精读】_哔哩哔哩_bilibili
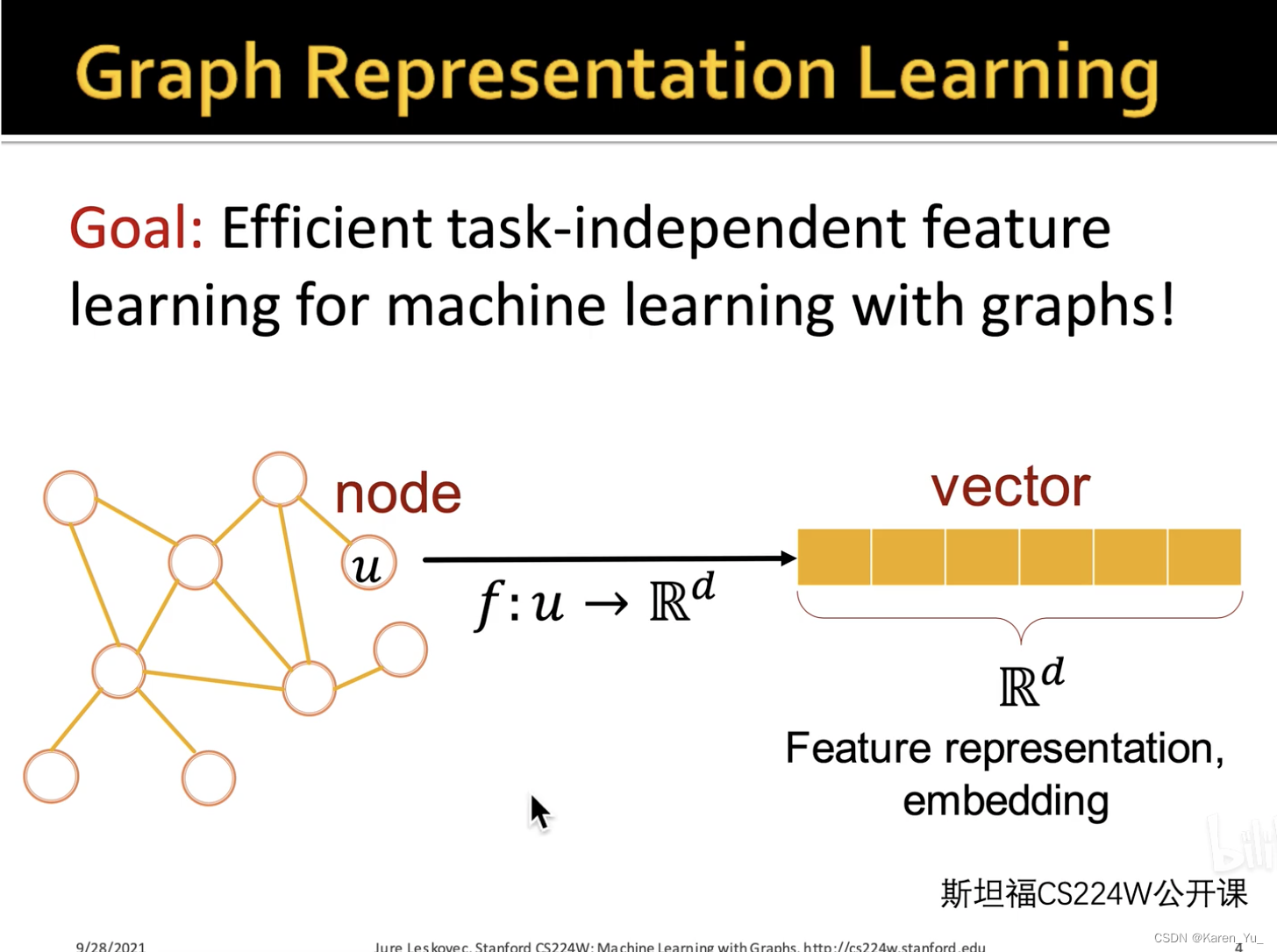
解决的问题:图嵌入
把每一个节点编码成一个d维的低维、稠密(不是one-hot)、连续(不是离散的,是实数->有助于保存更多的信息)向量,并且,这个向量应该包含原来节点的一些信息,特别是语义信息,同时还有结构信息、社群信息、邻域信息。
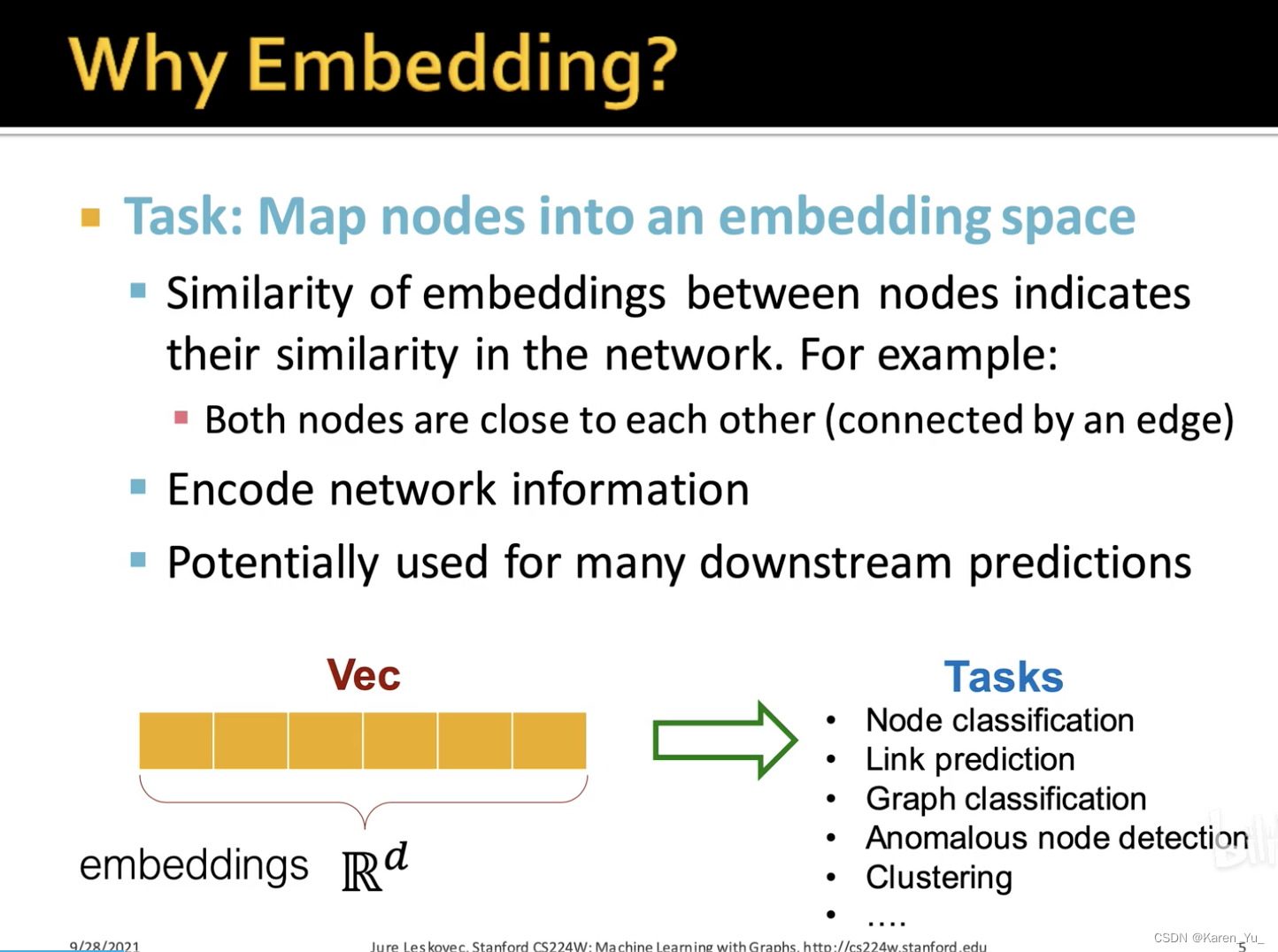
embedding之后,就可以正常ML了。

不仅仅节点可以做embedding。这里的node2vec是对节点做embedding。
手工构造的特征有很好的可解释性,但是不一定是很好的特征。node2vec和deepwalk都是基于随机游走的方法。

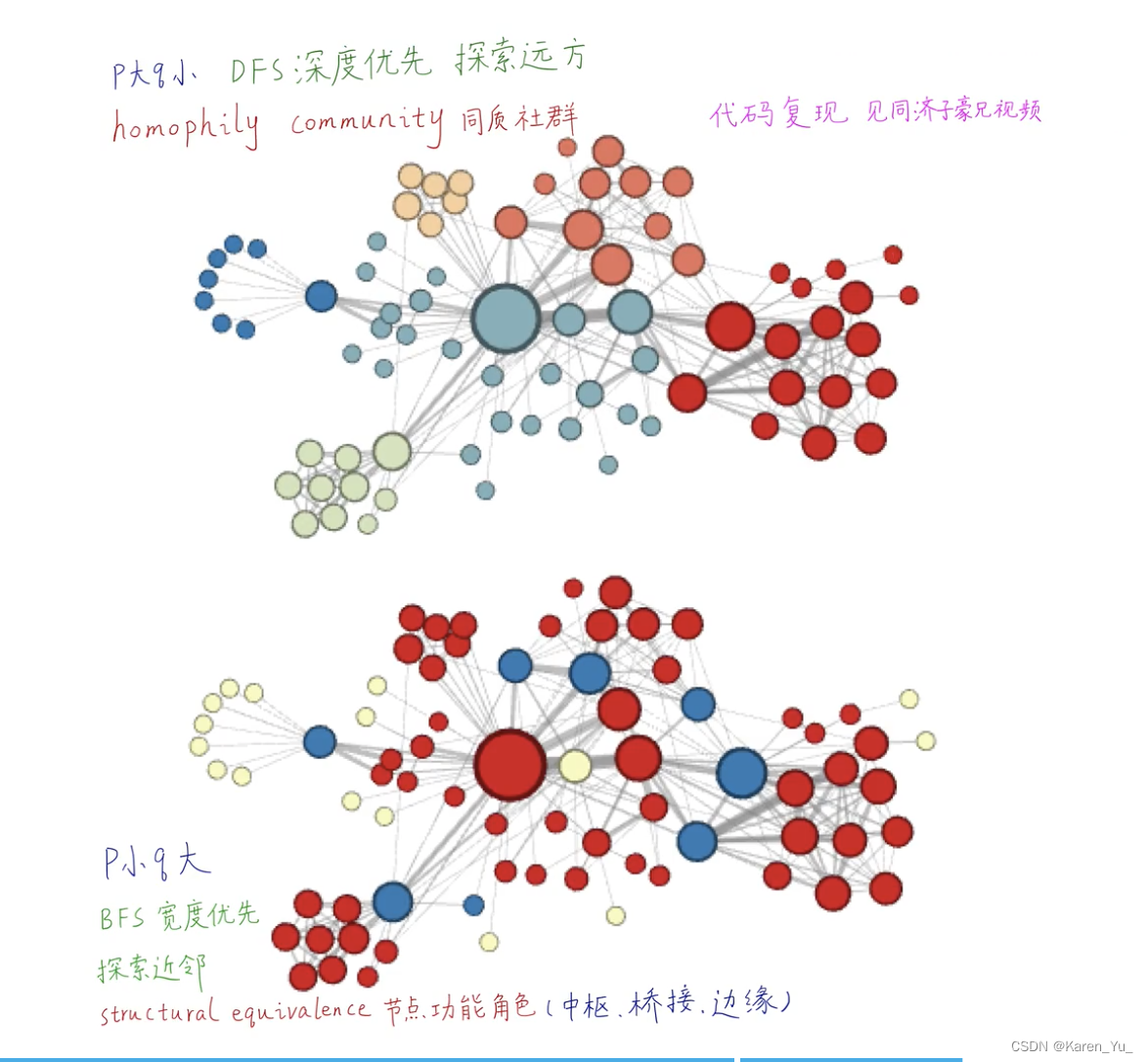
deepwalk只能把相邻或者相近的点聚在一起,但是其他的不可以,比如苏伊士运河和巴拿马运河的功能类似,但是离得远,就没办法放在一起。

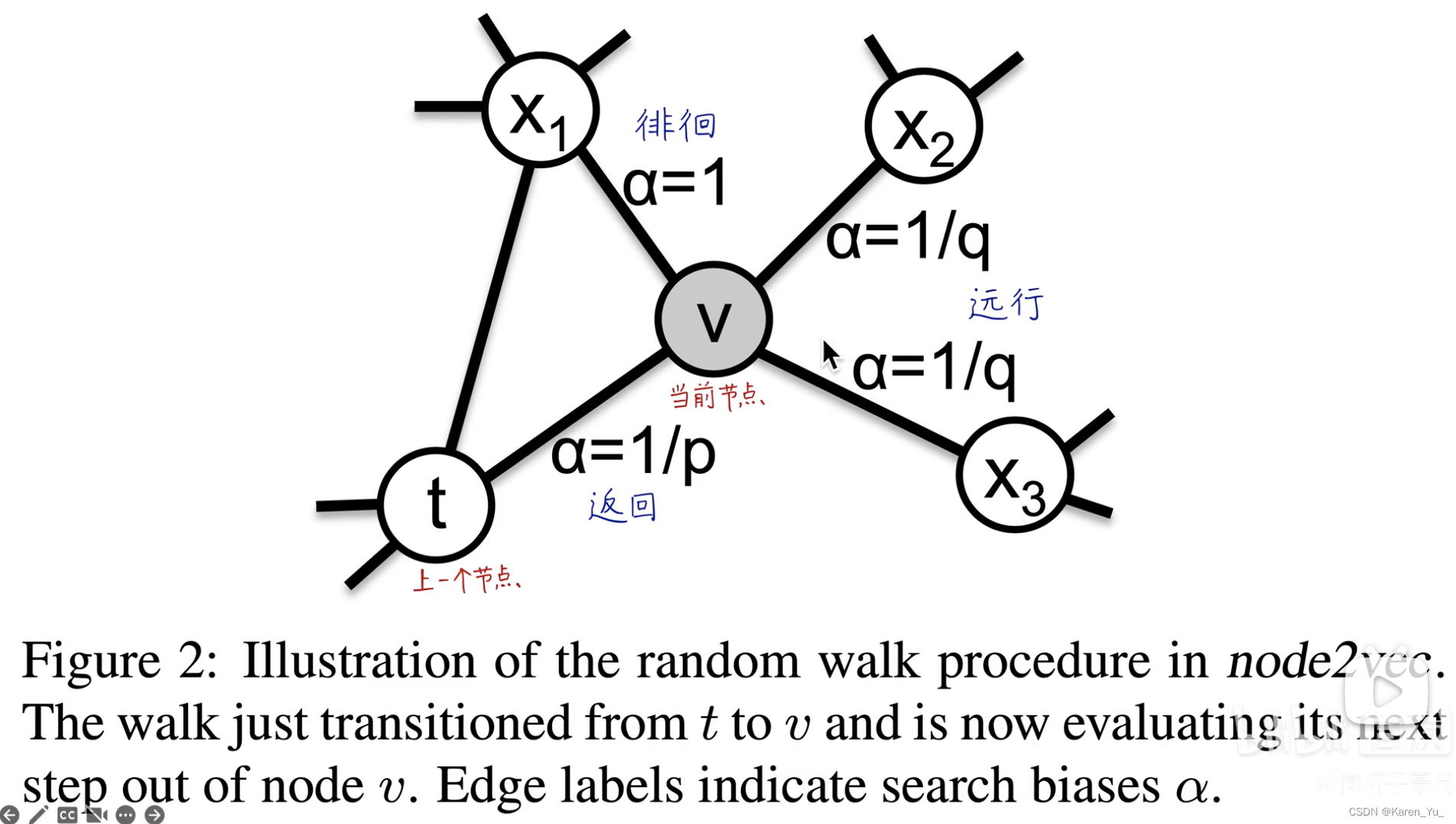
而对于node2vec,这里的随机游走就不再是完全的随机游走了,而是有偏随机游走。上图中,我们是从节点t走到了节点v,现在,我们要决定下一步向哪里走,这个时候我们有三个选择,返回(t节点),绕圈,走出去(离t更远了)。通过调整p q参数,来影响下一步往哪儿走。
(弹幕:这个功能相似性直观上好像是有偏游走的概率分布的相似性体现的)


不同的搜索策略会捕捉节点的不同特征。

这里的随机游走时2阶随机游走,而不是deepwalk中的1阶。在deepwalk中,下一个节点的采样仅取决于当前点的位置,而在node2vec中下一个节点不仅取决于当前节点,还要取决于上一个节点。->二阶随机游走/二阶马尔可夫
deepwalk可以看作是node2vec在情况下的特例->可以通过调整p q值


 优缺点
优缺点

第二个优点纠正:节点分类->embedding
Node2Vec论文逐句精读_哔哩哔哩_bilibili
(这里并不是完全的笔记,仅包含自己翻译的部分和视频中觉得有必要记下来的部分)
可扩展的图嵌入表示学习算法->可扩展:可以用在整个互联网规模的图上,并且可以用有限的时间、空间的成本。
解决的是图嵌入问题,是把图中的节点编码、映射成一个低维、连续、稠密的向量,而这个向量反应了这个节点在原图中的连接、社群、结构、角色等语义特征。
表示学习:用ML方法(数据驱动的方法)做的映射,而非人工构造特征,也不是矩阵分解的方法。
abstract
对于网络中的节点和边来做预测,首先需要做特征工程,把他们变成向量,有了这些向量之后才能输入到后续的机器学习算法当中,继续做下游的预测、分类任务。但是当时表示学习(ML)在图中的应用(如deepwalk、line)的表示能力不够高->无法反应出节点更丰富的特征和更丰富的连接属性。
提出node2vec,一个更好的做node embedding的方法。
node2vec是使用极大似然估计来实现训练。定义了一个非常灵活的,有偏随机游走方法,可以有效的探索多样的属性(邻居?),得到更丰富的表示。
introduction
任何监督ML都需要内涵丰富语义、有分类区分行、相互独立的特征。对于网络(图)而言,我们需要先把节点和边表示成特征向量(用特征向量表示节点和边)。
有监督的,针对特定任务的->找到针对下游任务的特征
无监督->通用的,与下游任务无关的特征
同一社群&同一功能角色的点应该具有相近的embedding
node2vec—>一种对于网络中可扩展的特征的半监督学习方法
二阶随机游走
feature learning framework
给定网络,我们的目标是学习一个映射
,把每一个节点映射成一个d维的实数向量
是一个大小为
的矩阵(就是一张表格,每个节点对应的d维的嵌入)。
对于每一个节点,我们定义
为节点
通过邻居采样策略(neighborhood sampling strategy)
产生的网络邻居(network neighborhood)
(讲人话就是这个N表示的是通过策略S得到的邻居)

同样采用skip-gram方法,用中间节点去预测周围节点,让红框中的值最大化
为了简化问题,这里做了两个基本假设:
- 条件独立。假设观察到一个邻居节点与观察到任意其他邻居节点之间是独立的(周围节点互不影响)

因此上面的红框可以简化成连乘的形式
softmax计算方法⬆️
- 特征空间对称性。一个节点与其邻居节点对彼此的印象是对称的(两个节点之间相互影响的程度是一样的)。
怎么知道谁是邻居:
idea1:搜索

真实的图是两种策略的mix
BFS提供的是一种微观视角,采样出来方差小,而DFS是宏观视角,采样出来方差大(就难以表达局部特征)
(弹幕:其实按照up主举的皇帝和运河的例子可以看出,确实DFS是找宏观的同质性。而BFS只关注微观邻近的结构。)
->设计一个灵活的邻域采样策略,让我们能够平滑的在BFS和DFS之间插值(私以为就是类似通过调整参数控制l1, l2)。
首先定义随机游走:
起始节点为u,上一个节点为t,当前节点为v,下一个节点为x

现在我们已经在v节点了,在此情况下,我们要去下一个节点x。若v和x之间没有连接,就是0,如果是有连接的话,就按照某个概率给每个连接赋予权重。上图中是权重,下面的Z是归一化常量。
接下来就是确定p q。
idea:用连接的权重作为游走的概率->如果是带权重的图,那么就可以直接用权重作为概率,即:,如果是无权图,那就是
这样久和deepwalk一样没办法调节游走策略
idea:直接用BFS或者DFS->太极端了
->提出一个二阶随机游走策略
使用两个参数来引导游走。

假设我们刚刚穿过边,现在驻足在节点v上,现在我们需要决定下一步。->边
的转移概率,我们将未归一化的转移概率定义为
,其中:
这里表示的是节点t和x之间的最短路径长度,且
只能在
中选一个。
:return parameter->如果p很大,就不太可能在接下来的两步中再次采样已经经过的节点,如果p小,就会返回
:in-out parameter->如果q很大,就会困在原地,如果q很小,就更倾向于远走高飞
注意:这里和起始节点无关,仅仅由当前节点和上一个节点决定下一个节点去哪儿。

node-embedding->link-embedding
判断两个点之间是否会存在连接

论文链接:














 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









