







1 投票法原理
投票法依据的少数服从多数的原则,在理想情况下,投票法集成的结果要优于各个基模型预测的结果。因此在分类器不理想的情况下,可以使用多个弱分类器进行投票集成,这样可以得到一个相对较好的结果。例如,对于一个二分类任务,有一个弱分类器,预测准确率为51%,那么以这个弱分类器为基分类器,集成3个,最终的预测准确率为: A C C = C 3 2 0.5 1 2 × 0.49 + C 3 3 0.5 1 3 = 51.50 % ACC=C_3^2\;0.51^2\times0.49+C_3^3\;0.51^3=51.50\% ACC=C320.512×0.49+C330.513=51.50%可见准确率提升了0.5%,如果基分类器更多,那么提升效果更明显。
投票法既可以用于回归分析,又可以用于分类预测。
- 回归分析:预测结果是所有基模型预测结果的平均值
- 分类任务:预测结果是所有基模型预测结果中最多的结果
\qquad\qquad 分类中的硬投票:预测结果是所有分类类别中投票结果最多的类。
\qquad\qquad 分类中的软投票:预测结果是所有分类类别预测概率结果中加和最大的类。
软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
投票法的局限性在于,它对所有模型的处理是一样的,即所有基模型对预测的贡献是一样的。而当有些模型在某些情况下好,其他情况下较坏时,这样的情况往往是被忽略的。
2 投票法实践
2.1 回归投票法
导入要用到的回归模型,其中线性回归、支持向量回归和k近邻回归是本次要进行投票集成的基模型,其他的决策树、随机森林、极端森林和提升树本身就是集成后的,用于对比。
# load regression model
from sklearn.linear_model import LinearRegression # 线性回归
from sklearn.svm import SVR # 支持向量回归
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.neighbors import KNeighborsRegressor # K近邻回归
from sklearn.tree import DecisionTreeRegressor # 决策树回归
from sklearn.ensemble import RandomForestRegressor # 随机森林回归
from sklearn.ensemble import ExtraTreesRegressor # 极端森林回归
from sklearn.ensemble import GradientBoostingRegressor # 提升树回归
# load used lib
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error # MSE
使用波士顿房价数据集作为本次的数据集
# load dataset
from sklearn import datasets
boston = datasets.load_boston()
X, y = boston.data, boston.target
利用各个模型进行单独的回归分析,并且以解释方差得分(explained_variance_score)和均方误差(mean_squared_error)作为评价指标。
1.线性回归模型
# LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
lin_pred = lin_reg.predict(X)
print("模型得分:",explained_variance_score(y,lin_pred))
print("均方误差:",mean_squared_error(y,lin_pred))
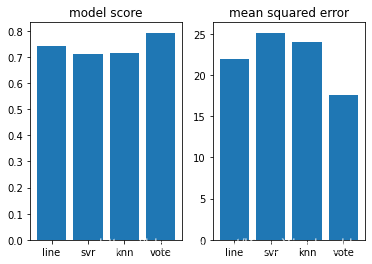
模型得分: 0.7406426641094095
均方误差: 21.894831181729202
2.支持向量回归模型
# SVR
# svr需要预处理,因此用pipline处理一下
svr_reg = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))
svr_reg.fit(X,y)
svr_pred = svr_reg.predict(X)
print("模型得分:",explained_variance_score(y,svr_pred))
print("均方误差:",mean_squared_error(y,svr_pred))
模型得分: 0.7127969161581074
均方误差: 25.118824323248944
3.K近邻回归模型
# KNeighborsRegressor
knn_reg = KNeighborsRegressor()
knn_reg.fit(X,y)
knn_pred = knn_reg.predict(X)
print("模型得分:",explained_variance_score(y,knn_pred))
print("均方误差:",mean_squared_error(y,knn_pred))
模型得分: 0.7164316988806692
均方误差: 23.966862450592888
4.以上三个基模型投票集成结果:
# voting with LinearRegression, svr, KNeighborsRegressor
y_pred = (lin_pred+svr_pred+knn_pred)/3
print("模型得分:",explained_variance_score(y,y_pred))
print("均方误差:",mean_squared_error(y,y_pred))
模型得分: 0.7930042785973932
均方误差: 17.539801460135237
由此可以看出,投票集成对单个基模型的回归预测准确度有一定提升,同时均方误差减小。
有些模型回归模型本身就是基于集成得到的,我们来看一下这些模型的回归预测效果
5.决策树模型
# DecisionTreeRegressor
dec_reg = DecisionTreeRegressor()
dec_reg.fit(X,y)
dec_pred = dec_reg.predict(X)
print("模型得分:",explained_variance_score(y,dec_pred))
print("均方误差:",mean_squared_error(y,dec_pred))
模型得分: 1.0
均方误差: 0.0
6.随机森林
# RandomForestRegressor
ran_reg = RandomForestRegressor()
ran_reg.fit(X,y)
ran_pred = ran_reg.predict(X)
print("模型得分:",explained_variance_score(y,ran_pred))
print("均方误差:",mean_squared_error(y,ran_pred))
模型得分: 0.9833385398396536
均方误差: 1.407009223320158
由此可见集成对回归的提升很大,可以接近完全准确。
2.2 分类投票法
2.2.1 硬投票
首先导入需要的数据模型,本次事件采用K近邻,利用不同K值得模型进行集成。
from sklearn.ensemble import VotingClassifier
import matplotlib.pyplot as plt
## 绘图函数库
import matplotlib.pyplot as plt
然后构建数据集
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
return X,y
利用VotingClassifier进行投票集成
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
为了比较分别利用基本模型和投票集成模型进行预测的结果,因此构建一个字典分别存储三个基模型和投票模型
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
接下来是对数据进行评估,利用十折交叉验证,并且重复三次
# evaluate a give model using cross-validation
from sklearn.model_selection import cross_val_score #Added by ljq
from sklearn.model_selection import RepeatedStratifiedKFold
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
最后实例化,以及进行结果分析
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))
# plot model performance for comparison
plt.boxplot(results, labels=names, showmeans=True)
plt.show()
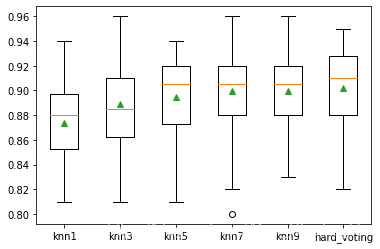
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard_voting 0.902 (0.034)
2.2.2 软投票
只需将VotingClassifier函数中得"vote"参数设置为"soft",即:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='soft')
return ensemble
结果为:
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
soft_voting 0.897 (0.029)
虽然准确率没有明显得提高,但是模型预测得方差得到了改善,同样说明投票集成提升了预测性能,同时其方差小于硬投票得方差,说明预测结果更接近真实结果。














 3114
3114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









