




4.0 简介
在机器学习 pipeline 中,数值型数据预处理是模型训练前的核心环节 —— 原始数值数据往往存在量纲差异、分布不合理、缺失 / 异常值等问题,直接输入模型会导致训练不稳定、效果偏差甚至完全失效。本章围绕数值型数据的 “特征变换、异常值处理、缺失值处理” 三大核心方向,拆解 11 个关键操作的原理、方法、适用场景与实践细节,帮助实现数据的 “清洁、规范、增强”,为后续模型训练打好基础。
4.1 特征的缩放
特征缩放是消除不同特征 “量纲差异” 的基础操作,核心目标是让所有特征处于相似的数值范围内,避免模型被数值量级大的特征(如 “房屋面积(平方米,取值 100-200)”)主导,而忽略量级小的关键特征(如 “房间数(取值 1-5)”)。
4.1.1 常见方法
-
Min-Max 归一化(最小 - 最大缩放)
原理:将特征值映射到 [0, 1] 区间,公式为:
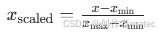
若需映射到其他区间(如 [-1, 1]),可调整公式为:
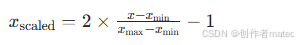
适用场景:特征分布已知、且需要将数据压缩到固定区间的场景(如神经网络输入、聚类算法)。
缺点:对异常值敏感(若存在极大 / 极小异常值,会导致大部分数据被压缩到极小范围)。 -
绝对最大值缩放(本章节不阐述,主要是阐述常用的)
问题描述
将一个数值型特征值缩放(rescale)到两个特定的值之间。
解决方案
用scikit-learn中的MinmaxScale函数来缩放一个特征数组:
import numpy as np
from sklearn import preprocessing
#创建特征
resacle = np.array([[-500.5],[-100.1],[0],[100.1],[900.0]])
#创建缩放器0-1
minmix_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
#缩放特征值
scale_feature = minmix_scale.fit_transform(resacle)
print(scale_feature)
4.1.2 讨论
在机器学习中,缩放是一个很常见的预处理任务。目前所讨论的算法都假设所有的特征在同一取值范围中。最常见的范围是[0,1],['-1,1].
4.2 特征标准化
标准化(也叫 “Z - 分数标准化”)是将特征转换为均值为 0、标准差为 1的分布,核心目标是让特征符合 “正态分布假设”,适配对数据分布敏感的模型。
4.2.1 原理与公式
对特征 x,计算其均值 (\mu) 和标准差 (\sigma),转换公式为:
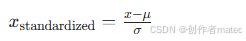
问题描述
对一个特征进行转换,使其平均值为0,标准差为1。
解决方案
scikit-learn的StandardScaler能够同时执行这两个转换。
import numpy as np
from sklearn import preprocessing
#创建特征
resacle = np.array([[-100.1],[-200.2],[500.5],[600.6],[9000.9]])
#创建缩放器
minmax_recale = preprocessing.StandardScaler()
#转换特征
standard_recale = minmax_recale.fit_transform(resacle)
print(standard_recale)
标准化方法是机器学习数据与处理中的常用的缩放方法,从经验来看,它比min-max缩放用的更多。如果在主成分析中标准化方法更有用,而在神经网络中更推荐使用min-man缩放。
注意:如果数据中存在很大的异常值,可能会影响特征的平均值和方差,也会对标准化的效果造成不良影响。在这种情况下,使用中位数和四分位数间距进行缩放会更有效。在scikit-learn中,具体的做法就是调用RobustScaler():
import numpy as np
from sklearn import preprocessing
#创建特征
resacle = np.array([[-100.1],[-200.2],[500.5],[600.6],[9000.9]])
#创建缩放器
robust_scale  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5507
5507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











