






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
摘要
本文研究了在固定和切换有向拓扑下,一般线性多智能体系统的动态事件触发共识问题。为每个智能体引入了两种分布式动态事件触发策略(涉及内部动态变量),以实现渐近共识。与现有的静态触发策略相比,所提出的动态触发策略能够实现更长的执行间隔时间和更少的智能体间通信能耗。此外,在所提出的控制策略中,控制器更新和触发阈值检测均不需要连续通信。同时,证明了在固定和切换有向拓扑下,严格排除了Zeno行为。最后,通过数值仿真验证了理论分析的有效性。
引言
多智能体系统(MASs)的协同控制最初源于自然界中生物群体(如鱼群和鸟群)的集体行为,由于其在众多领域的广泛应用,例如分布式优化[1, 2]、无人机/卫星编队飞行[3, 4]、无线传感器网络[5]、跟踪控制[6, 7]等,近年来受到了越来越多的关注。因此,作为多智能体系统协同控制的一个基本问题,共识问题旨在设计合适的控制策略,使所有智能体的状态达到与某种控制性能相关的共同值,吸引了众多学者在这个高度互联的现代世界中开展大量研究工作(见[8–12]及其参考文献)。
作为多智能体系统共识控制的基础,通信在传统控制策略中通常被假设为连续的,这要求所有智能体都配备足够的通信资源和通信带宽。显然,在实际应用中,维持这样的环境以满足系统长期运行的需求是困难的。为了避免这一缺点,近年来研究了具有间歇通信的分布式控制器。一个常用的策略是[13]中提出的周期性采样。尽管周期性采样策略使智能体之间能够进行间歇通信,但即使在控制目标已经达成后,控制器仍然会周期性更新,这导致了能量的浪费。在这种意义上,大量研究工作旨在减轻连续/周期性通信的要求并降低通信成本,从而促成了事件触发控制方案的出现。在此方案下,只有在某些特定事件被触发时(例如,测量误差超过预设阈值)才会传输信息。此后,许多学者对事件触发共识问题进行了研究,见[14–25]。对于具有单积分器或双积分器动态的多智能体系统,可以在[14, 15]中找到许多相关结果。对于具有无向图[16–18]和有向图[19]的一般线性模型的多智能体系统,分别提出了事件触发共识控制算法。然而,在这些工作中,事件触发函数仍然需要连续访问邻居的状态信息,这与引入事件触发策略以节省通信能耗的初衷背道而驰。为了解决这一问题,考虑到在有向图下的一般线性多智能体系统,[20, 21]的作者分别提出了一种严格的时间依赖和状态依赖的事件触发共识控制协议。此外,作者在[22]中通过基于模型的事件触发方案实现了有限时间共识。关于非线性网络系统的基于事件触发的最新研究可以在[23–26]中找到,这些研究分别关注自适应模型预测控制问题、输出反馈跟踪控制问题、具有未知外部干扰的自适应控制问题以及在识别器-评论家网络框架下的约束最优控制问题。
值得注意的是,上述所有结果都是在静态事件触发控制策略的框架下获得的。然而,[27]中提出了一类新的包含内部动态变量的动态事件触发控制策略,具有显著更大的平均事件间隔时间等优点。因此,近年来动态事件触发策略已被用于解决多智能体系统的共识问题(见[28–33])。[28]的作者研究了单积分器多智能体系统的动态事件触发平均共识问题。在[29]中,研究了二阶多智能体系统的共识问题,并采用集中式动态触发条件。然而,这些工作仅限于积分器类型的动态智能体。对于一般线性多智能体系统,动态触发机制的思想分别应用于[30]中的分布式编队问题和[31, 32]中的自适应共识控制问题。尽管[30–32]被扩展到一般线性多智能体系统以解决动态共识问题,但上述工作均基于无向图。事实上,无向拓扑是双向的,这意味着通信和能耗将是单向链路的两倍。有向交互拓扑在应用中更为现实,它包括无向图作为其特殊情况。此外,对于具有有向图的一般线性多智能体系统,Hu等人在[33]中也在动态触发框架下解决了共识问题。然而,缺点是每个智能体的事件检测仍然需要连续通信,这违背了节省能量的初衷。
鉴于此,这些部分激励我们的工作去研究在有向图下一般线性多智能体系统的动态事件触发共识问题,而无需在控制器更新和触发检测中进行连续通信,这更具意义和实践价值。
在实际应用中,由于许多因素(如链路故障、外部障碍或新连接的创建)的影响,多智能体系统的通信拓扑可能会不可避免地发生变化。因此,多智能体系统在切换拓扑下的事件触发共识控制构成了当前研究的一个非常活跃的领域。[34]的作者解决了一类任意阶多智能体系统在切换拓扑下的共识问题,其中包括多种不一致的拓扑。随后,在[35]中,在固定和切换拓扑下设计了一种使用邻居状态的开环估计的分散式事件触发控制器。[36]的作者引入了一种依赖于模式的驻留时间方法,以解决一般线性多智能体系统在切换拓扑下的事件触发共识问题。然后,通过提出一种基于持续驻留时间的预测器式共识协议,在[37]中实现了具有切换拓扑的多智能体系统的有界平均共识。然而,上述关于切换拓扑下线性多智能体系统的所有工作都集中在静态事件触发策略上。据我们所知,为一般线性多智能体系统在切换拓扑下设计分布式动态事件触发共识策略仍然是一个有待突破的开放性问题。此外,选择合适的切换律并在切换情况下保证动态事件触发问题的可解性并非易事。
受上述观察的启发,本文将讨论通过新颖的分布式动态事件触发策略,在固定和切换有向图下一般线性多智能体系统的分布式共识控制问题。由于更一般的智能体模型和更复杂的通信拓扑,共识稳定性分析和Zeno行为排除面临着更大的挑战。本文的主要贡献总结如下:
• 首先,许多现有工作(包括静态和动态事件触发方案)在触发机制设计中仍然需要连续访问邻居状态(见[14, 16, 19, 27]),而本研究提出的事件触发控制方案不仅避免了控制器更新中的连续通信,还避免了触发检测中的连续通信。
• 其次,与静态事件触发机制(例如[19–21])相比,本文提出的具有内部动态变量的动态事件触发函数能够产生更大的触发间隔,这有助于在实际应用中避免Zeno行为。此外,Dimarogonas等人[14]和Liu等人[21]提出的静态触发机制是本文方法的特例。
• 第三,与大多数主要关注积分器类型动态或无向图的动态事件触发机制的现有工作不同([27–32]),本文提出的结果将分别展示在固定和切换有向拓扑下一般线性多智能体系统的共识。
结论
本文研究了一般线性多智能体系统在固定和切换有向图下的共识问题。对于固定拓扑,提出了一种分布式动态事件触发控制协议以及动态触发函数,其中控制器更新和触发条件检测均利用邻居的离散信息。随后,我们将动态事件触发协议扩展到切换拓扑下的多智能体系统。所提出的结果表明,在这两种拓扑类型下,系统可以从任意初始条件达成共识,并且不存在Zeno行为。将本文的结果扩展到异构智能体网络或联合连通的切换拓扑,并在多智能体系统包含某些不确定性或外部干扰时设计新的策略,是未来研究的有趣方向。
📚2 运行结果
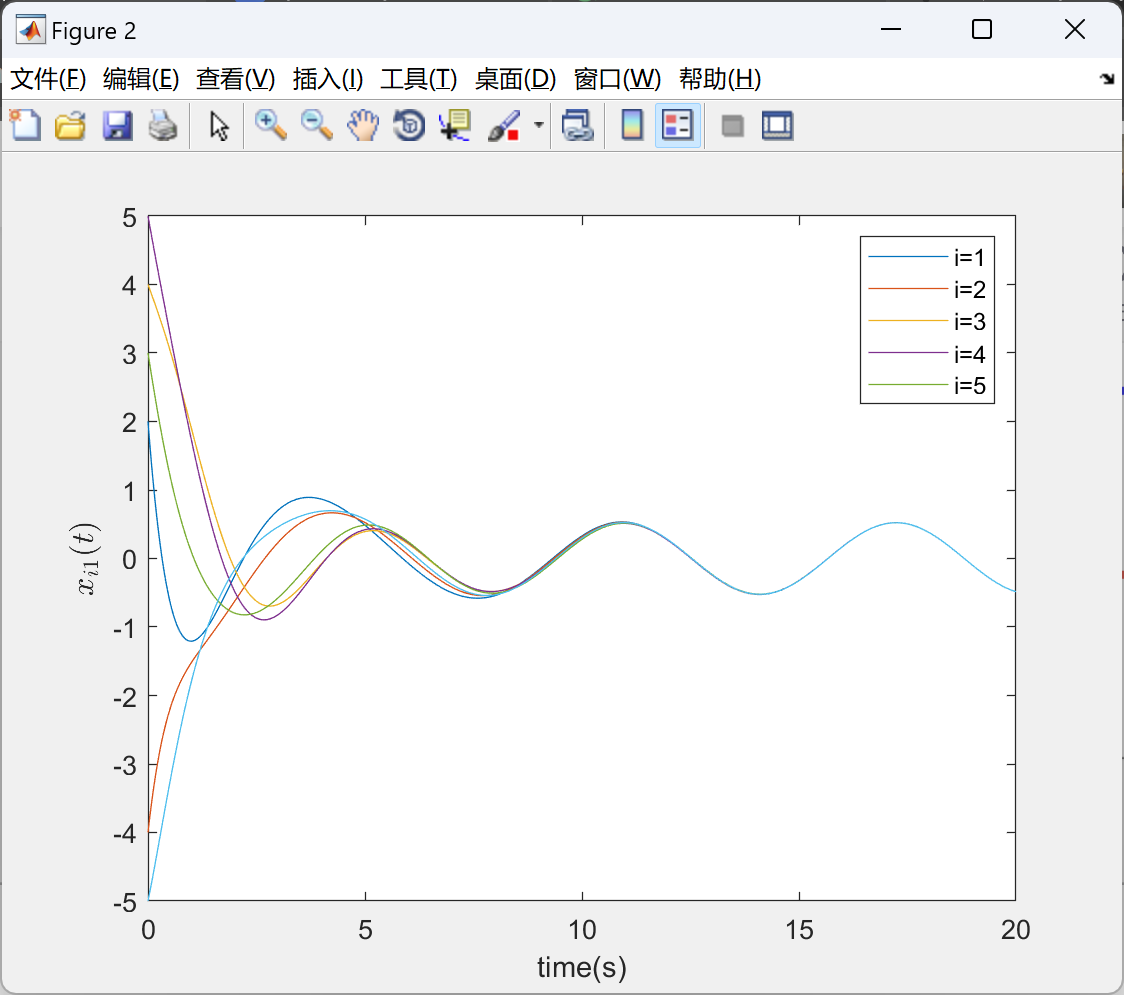
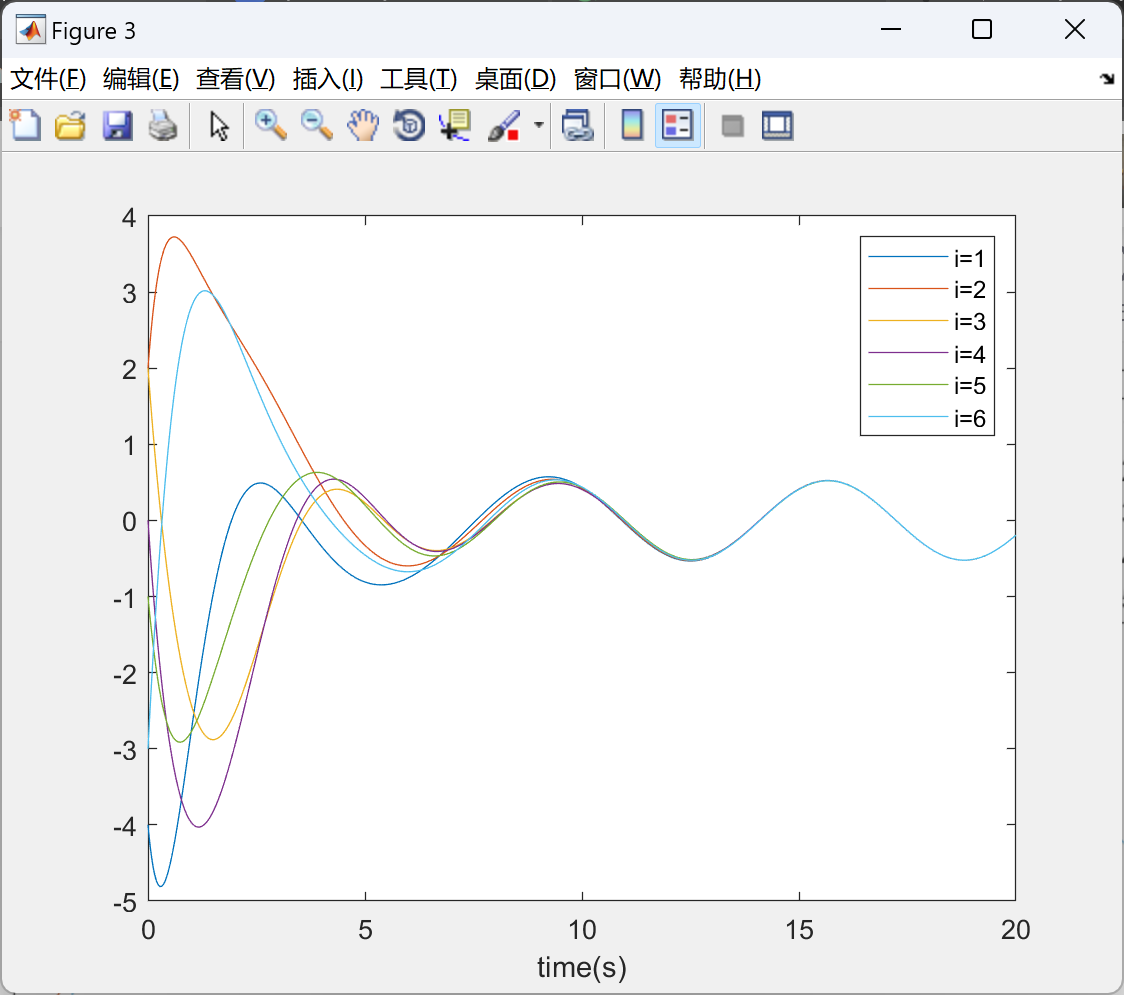

部分代码:
figure%第一个分量的轨迹图
for i=1:6
plot(Ts,x1(2*i-1,:));
hold on
end
xlabel('time(s)');
ylabel('$x_{i1}(t)$','interpreter','latex','FontSize',12);
xp1=legend('i=1','i=2','i=3','i=4','i=5');
figure%第二个分量的轨迹图
for i=1:6
plot(Ts,x1(2*i,:));
hold on
end
xlabel('time(s)');
xp1=legend('i=1','i=2','i=3','i=4','i=5','i=6');
figure%控制输入轨迹图
for i=1:6
plot(Ts,uc(i,:),'LineWidth',1);
hold on
end
xlabel('time(s)');
xp1=legend('i=1','i=2','i=3','i=4','i=5','i=6');
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)

🌈4 Matlab代码、文章讲解
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









