







论文下载地址:https://arxiv.org/pdf/2208.02019v2.pdf
目录
Occlusion-Aware Repulsion Loss
Occlusion-Aware Attention Network
Normalized Gaussian Wasserstein Distance

提出目的和方法
提出目的
基于深度学习的人脸检测算法取得了显著进展。这些算法大致可以分为两类:一种是两阶段检测器,如 Faster R-CNN;另一种是单阶段检测器,如 YOLO。由于在准确性和速度之间取得了更好的平衡,单阶段检测器已广泛应用于许多实际场景。。
提出方法
提出了一种基于单阶段检测器 YOLOv5 的实时人脸检测器,命名为 YOLO-FaceV2。设计了一个称为 RFE 的感受野增强模块,以增强小人脸的感受野,并使用 NWD Loss 来弥补 IoU 对微小物体位置偏差的敏感性。针对人脸遮挡问题,提出了一个名为 SEAM 的注意力模块,并引入了排斥损失(Repulsion Loss)来解决这一问题。此外,使用一个权重函数 Slide 来解决容易检测样本和难检测样本之间的不平衡,并利用有效感受野的信息来设计锚框。
- 首先,融合了 FPN 的 P2 层信息,以获得更多的像素级信息,并补偿小人脸的特征信息。然而,这样做会导致大中型目标的检测准确性略有下降,因为输出特征图的感受野变小。为改善这种情况,为 P5 层设计了感受野增强(RFE)模块,通过使用膨胀卷积来增加感受野
- 其次,受到 FAN 和 ConvMixer 的启发,重新设计了一个多头注意力网络,以补偿被遮挡人脸响应值的损失。此外,还引入了排斥损失(Repulsion Loss),以提高对同类遮挡物体的召回率。
- 第三,为了挖掘难样本,受到 ATSS 的启发,设计了带有自适应阈值的 Slide 权重函数,使模型在训练过程中更关注难样本。
- 第四,为了使锚框更适合回归,根据有效感受野和人脸的比例重新设计了锚框的大小和比例。
- 最后,借用了归一化的 Wasserstein 距离度量,并将其引入到回归损失函数中,以平衡 IoU 在预测小人脸时的不足。
整体模型架构
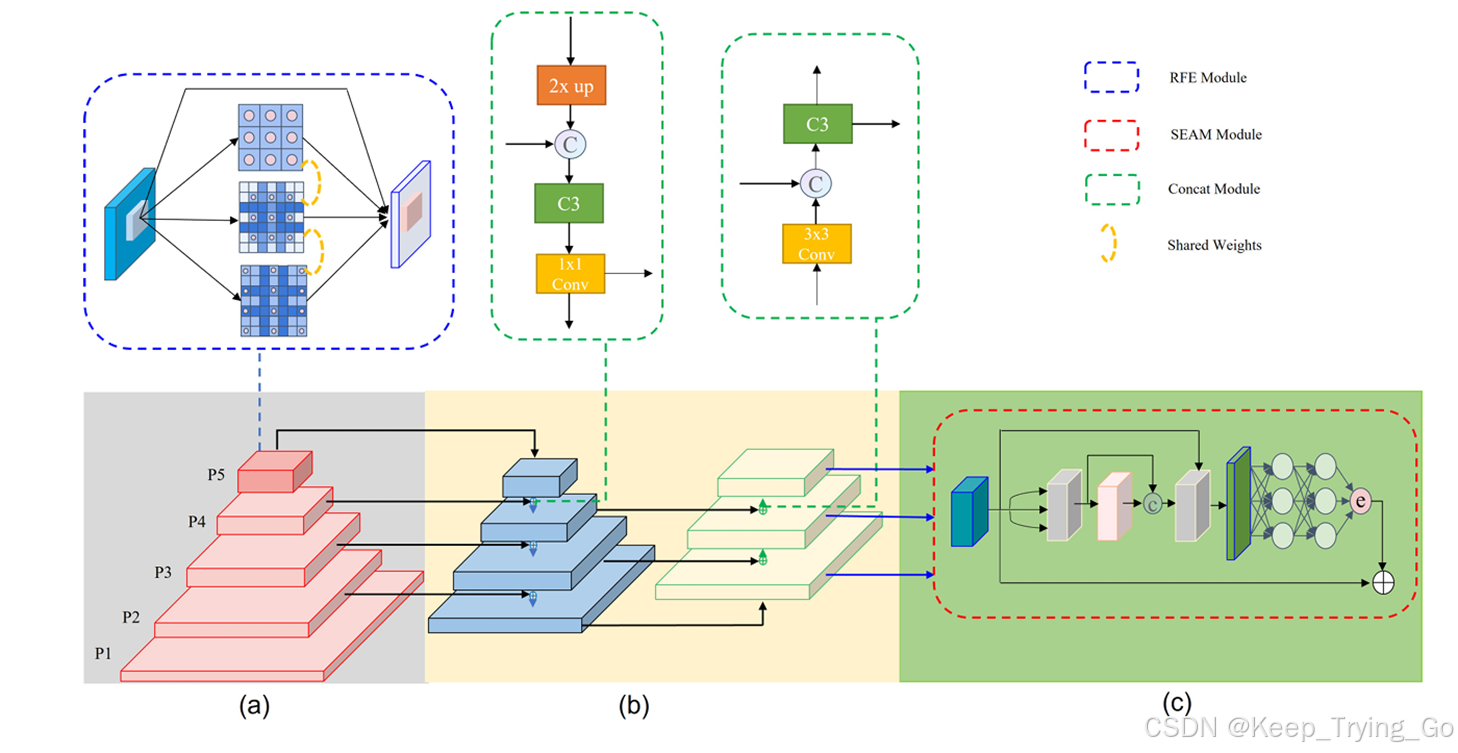
YOLO-FaceV2 检测器的架构如图 1 所示。它由三个部分组成:主干结构、颈部和头部。采用 CSPDarknet53 作为主干,并在 P5 层用 RFE 模块替换了 Bottleneck,以融合多尺度特征。在颈部部分,保持 SPP 和 PAN 的结构。此外,为了提高目标位置感知能力,还将 P2 层集成到 PAN 中。头部用于对目标进行分类和回归。还在头部中增加了一个专门的分支,以增强模型对于遮挡检测的能力。
在图 1 (a) 中,左侧的红色部分是检测器的主干,由 CSP 块和 CBS 块组成。它主要用于提取输入图像的特征。RFE 模块的添加旨在扩展有效感受野并增强 P5 层中多尺度特征的融合能力。在图 1 (b) 中,右侧的蓝色和黄色部分称为neck层,由 SPP 和 PAN 组成。另外融合了 P2 层的特征,以提高更准确的目标定位能力。在图 1 (c) 中,引入了分离与增强注意力模块(SEAM),以在neck层输出之后增强对被遮挡人脸的响应能力。
Scale-Aware RFE Model
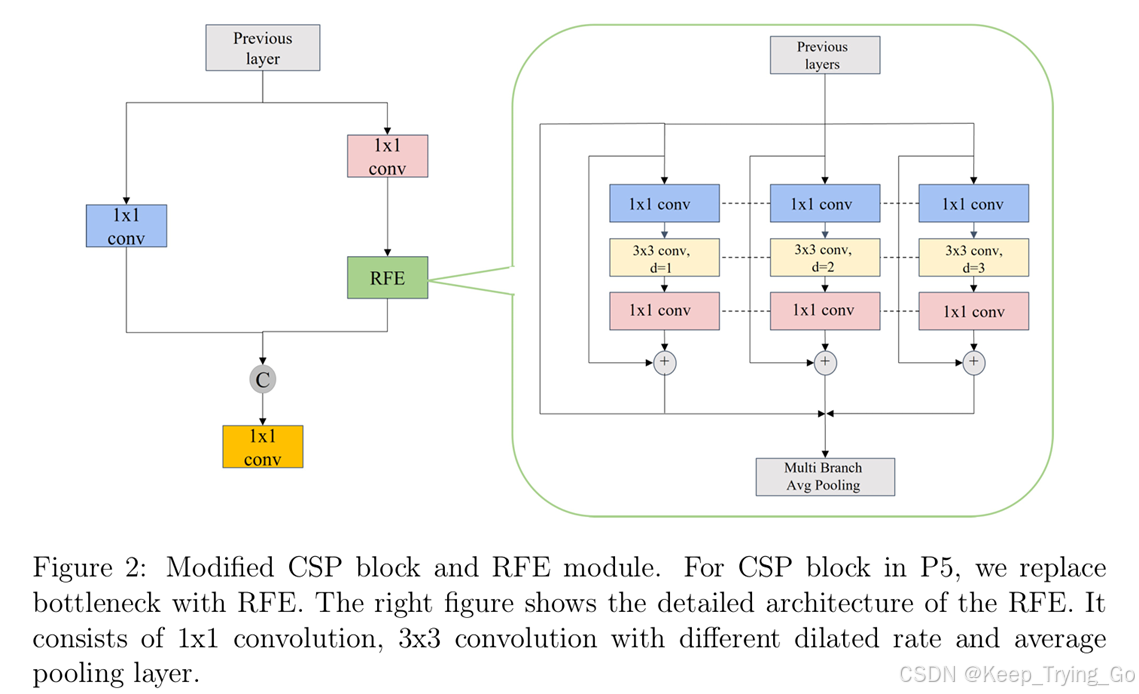
由于不同大小的感受野意味着捕捉长程依赖的能力不同,因此设计了 RFE 模块,充分利用特征图中感受野的优势,通过使用膨胀卷积来实现。受到 TridentNet 的启发,使用四个不同膨胀率的卷积分支来捕捉多尺度信息和不同范围的依赖关系。所有分支共享权重,唯一的区别在于它们各自独特的感受野。一方面,这减少了参数量,从而降低了潜在过拟合的风险;另一方面,它可以充分利用每个样本。提出的 RFE 模块可以分为两个部分:基于膨胀卷积的多分支部分和聚合与加权层,如图所示。
多分支部分分别采用 1、2 和 3 作为不同膨胀卷积的膨胀率,均使用固定的卷积核大小 3x3。进一步地,添加了残差连接,以防止训练过程中的梯度爆炸和消失问题。聚合与加权层用于聚合来自不同分支的信息,并对每个特征分支进行加权。加权操作用于平衡不同分支的表示。用 RFE 模块替换了 YOLOv5 中 C3 模块的瓶颈,以增加特征图的感受野,从而提高多尺度目标检测和识别的精度,如图 2 所示。
Occlusion-Aware Repulsion Loss

代码实现
import torch
import numpy as np
from utils.general import box_iou
# reference: https://github.com/dongdonghy/repulsion_loss_pytorch/blob/master/repulsion_loss.py
def IoG(gt_box, pre_box):
inter_xmin = torch.max(gt_box[:, 0], pre_box[:, 0])
inter_ymin = torch.max(gt_box[:, 1], pre_box[:, 1])
inter_xmax = torch.min(gt_box[:, 2], pre_box[:, 2])
inter_ymax = torch.min(gt_box[:, 3], pre_box[:, 3])
Iw = torch.clamp(inter_xmax - inter_xmin, min=0)
Ih = torch.clamp(inter_ymax - inter_ymin, min=0)
I = Iw * Ih
#TODO 计算得到的交集面积和真实box面积的比值
G = ((gt_box[:, 2] - gt_box[:, 0]) * (gt_box[:, 3] - gt_box[:, 1])).clamp(1e-6)
return I / G
def smooth_ln(x, deta=0.5):
return torch.where(
torch.le(x, deta),
-torch.log(1 - x),
((x - deta) / (1 - deta)) - np.log(1 - deta)
)
# YU 添加了detach,减小了梯度对gpu的占用
def repulsion_loss_torch(pbox, gtbox, deta=0.5, pnms=0.1, gtnms=0.1, x1x2y1y2=False):
repgt_loss = 0.0
repbox_loss = 0.0
pbox = pbox.detach()
gtbox = gtbox.detach()
gtbox_cpu = gtbox.cuda().data.cpu().numpy()
#TODO 计算预测框和gt box之间的IOU
pgiou = box_iou(pbox, gtbox, x1y1x2y2=x1x2y1y2)
pgiou = pgiou.cuda().data.cpu().numpy()
#TODO 计算预测的box之间IOU
ppiou = box_iou(pbox, pbox, x1y1x2y2=x1x2y1y2)
ppiou = ppiou.cuda().data.cpu().numpy()
# t1 = time.time()
len = pgiou.shape[0]
#TODO 遍历每一个组
for j in range(len):
for z in range(j, len):
ppiou[j, z] = 0
#TODO 对于当前的组,判断第j个box和第z个box之间的坐标关系
if ((gtbox_cpu[j][0]==gtbox_cpu[z][0]) and
(gtbox_cpu[j][1]==gtbox_cpu[z][1]) and
(gtbox_cpu[j][2]==gtbox_cpu[z][2]) and
(gtbox_cpu[j][3]==gtbox_cpu[z][3])):
#TODO 如果存在重叠就设将其IOU设置为0
pgiou[j, z] = 0
pgiou[z, j] = 0
ppiou[z, j] = 0
# t2 = time.time()
# print("for cycle cost time is: ", t2 - t1, "s")
pgiou = torch.from_numpy(pgiou).cuda().detach()
ppiou = torch.from_numpy(ppiou).cuda().detach()
# TODO repgt
max_iou, argmax_iou = torch.max(pgiou, 1)
pg_mask = torch.gt(max_iou, gtnms) #TODO 判断过滤之后的IOU是否大于指定的NMS阈值
num_repgt = pg_mask.sum()
if num_repgt > 0:
#TODO 获得预测框和真实框之间IOU
iou_pos = pgiou[pg_mask, :]
#TODO 计算最大IOU
max_iou_sec, argmax_iou_sec = torch.max(iou_pos, 1)
pbox_sec = pbox[pg_mask, :]
gtbox_sec = gtbox[argmax_iou_sec, :]
#TODO 和论文中给定的公式是一一对应的
IOG = IoG(gtbox_sec, pbox_sec)
repgt_loss = smooth_ln(IOG, deta)
repgt_loss = repgt_loss.mean()
# repbox
pp_mask = torch.gt(ppiou, pnms) # 防止nms为0, 因为如果为0,那么上面的for循环就没有意义了 [N x N] error
num_pbox = pp_mask.sum()
if num_pbox > 0:
repbox_loss = smooth_ln(ppiou, deta)
repbox_loss = repbox_loss.mean()
# mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0)
# print(mem)
torch.cuda.empty_cache()
return repgt_loss, repbox_loss
Occlusion-Aware Attention Network
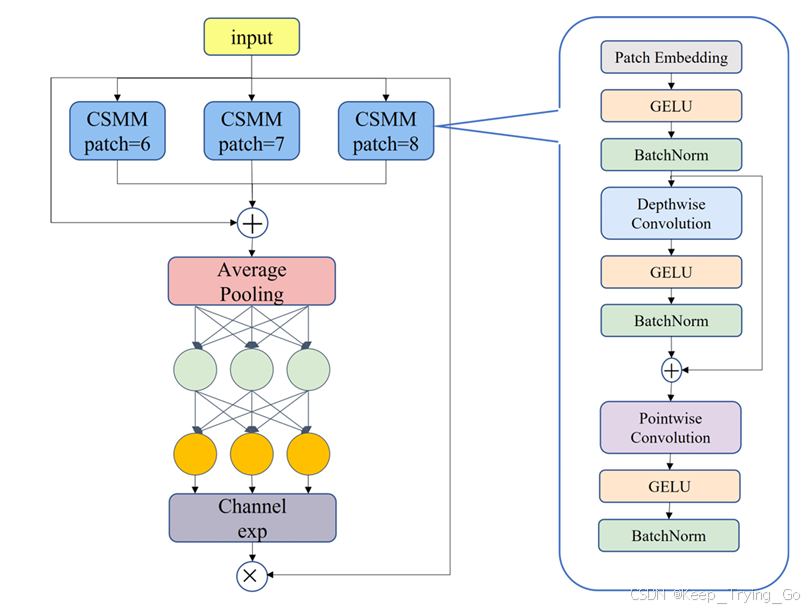
在模型中加入了多头注意力网络,即 SEAM 模块(见图 ),其有三个主要目的:实现多尺度人脸检测,强调图像中的人脸区域,并相应地削弱背景区域。
SEAM 的第一部分是带有残差连接的深度可分离卷积。深度可分离卷积逐层进行,即将卷积按照通道分开进行。虽然深度可分离卷积能够学习不同通道的重要性并减少参数量,但它忽略了通道之间的信息关系。为弥补这一损失,不同深度卷积的输出随即通过逐点(1x1)卷积进行组合。接着,使用两层全连接网络来融合每个通道的信息,以便增强网络中所有通道之间的连接。希望该模型能够通过在上一阶段学习的被遮挡面孔与未被遮挡面孔之间的关系,弥补在遮挡场景下的损失。全连接层学习到的输出 logits 然后通过指数函数处理,将值范围从 [0, 1] 扩展到 [1, e]。这种指数归一化提供了一种单调映射关系,使结果对位置误差更具容忍性。最后,SEAM 模块的输出被用作注意力,乘以原始特征,从而使模型能够更有效地处理人脸遮挡问题。
Sample weighting function
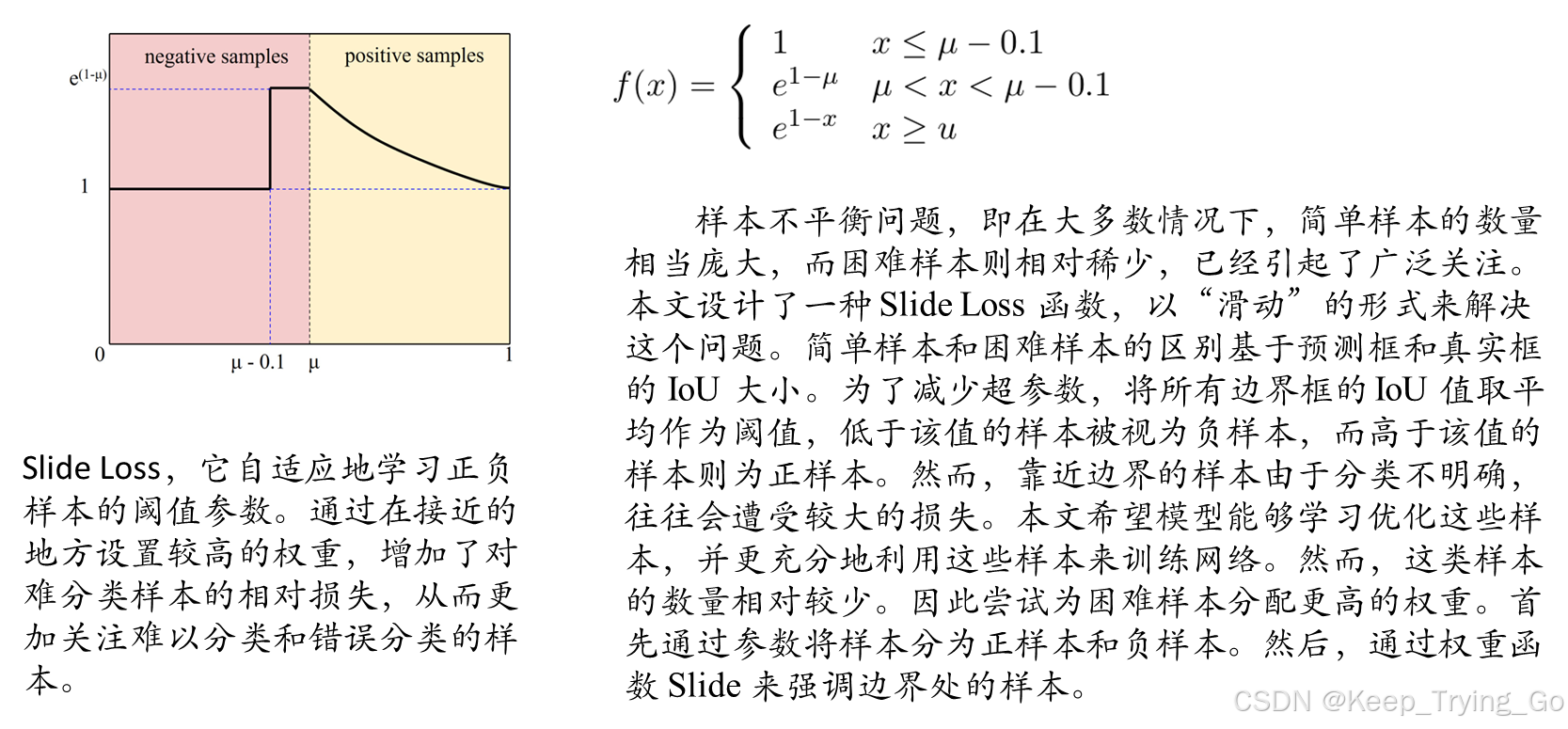
Anchor Design Strategy

Normalized Gaussian Wasserstein Distance

代码实现
def Wasserstein(box1, box2, x1y1x2y2=True):
box2 = box2.T
if x1y1x2y2:
b1_cx, b1_cy = (box1[0] + box1[2]) / 2, (box1[1] + box1[3]) / 2
b1_w, b1_h = box1[2] - box1[0], box1[3] - box1[1]
b2_cx, b2_cy = (box2[0] + box2[0]) / 2, (box2[1] + box2[3]) / 2
b1_w, b1_h = box2[2] - box2[0], box2[3] - box2[1]
else:
b1_cx, b1_cy, b1_w, b1_h = box1[0], box1[1], box1[2], box1[3]
b2_cx, b2_cy, b2_w, b2_h = box2[0], box2[1], box2[2], box2[3]
cx_L2Norm = torch.pow((b1_cx - b2_cx), 2)
cy_L2Norm = torch.pow((b1_cy - b2_cy), 2)
p1 = cx_L2Norm + cy_L2Norm
w_FroNorm = torch.pow((b1_w - b2_w)/2, 2)
h_FroNorm = torch.pow((b1_h - b2_h)/2, 2)
p2 = w_FroNorm + h_FroNorm
return p1 + p2实验部分
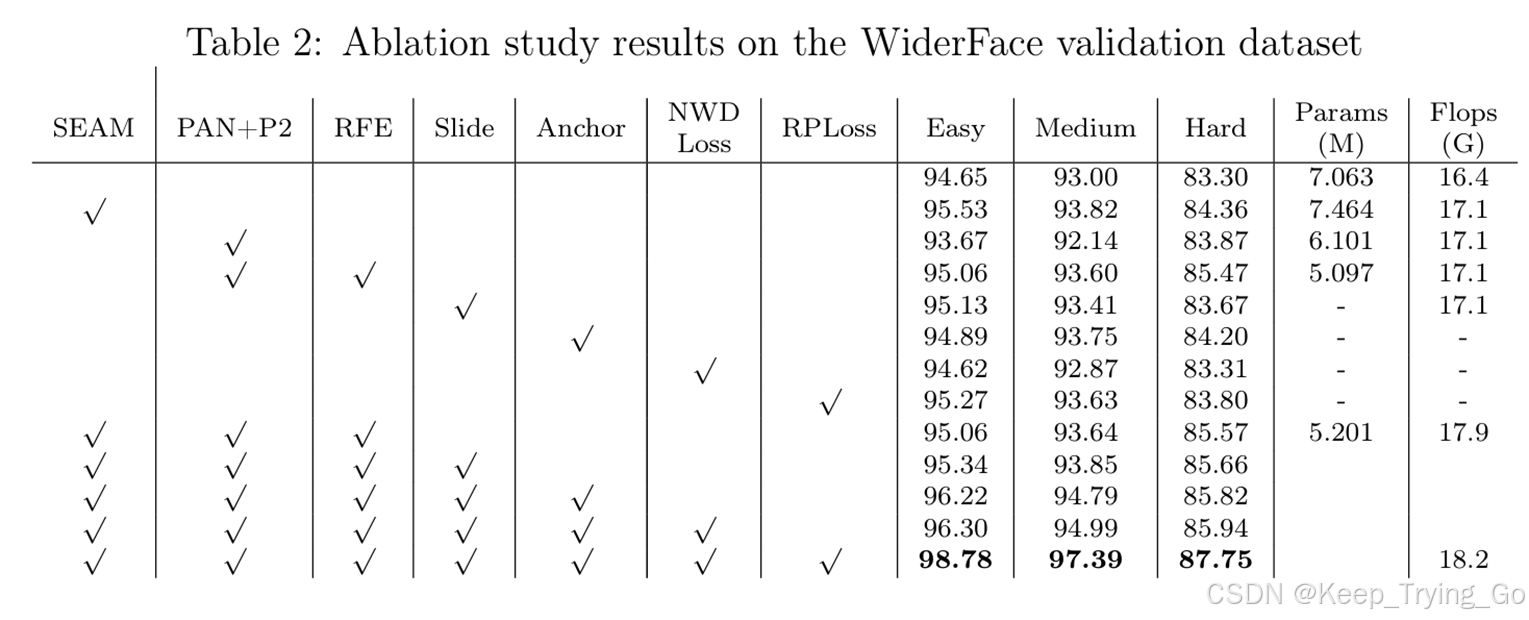

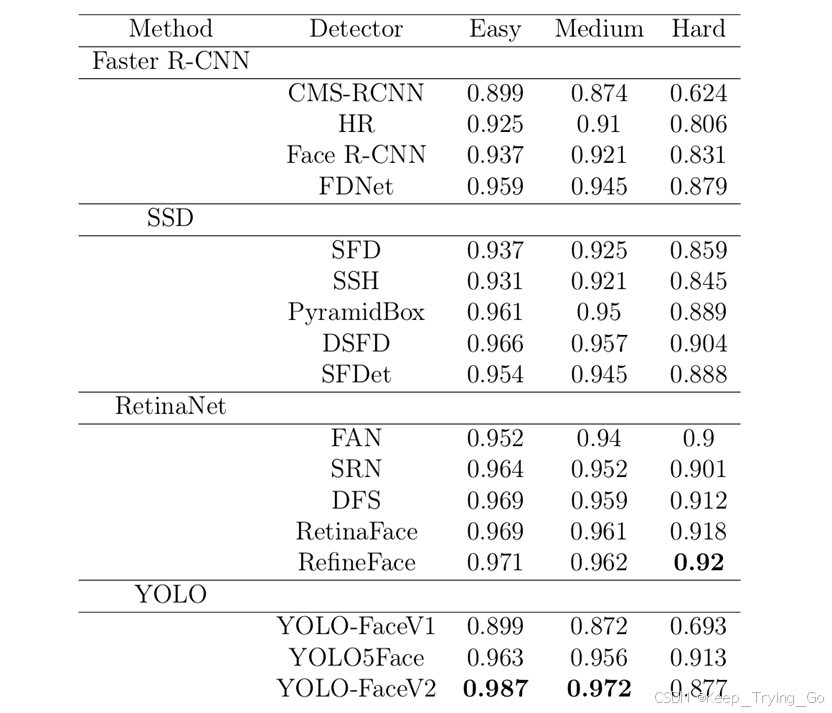
注:和SOTA的比较结果,本文的方法效果是最好的。
训练和测试
通过百度网盘分享的文件:yolo-faceV2链接:
https://pan.baidu.com/s/1qYVuYpxBWaoTMWSEC1cxoA
提取码:m8et
| backbone | 训练集 | 测试集 | MAP | Batch size | 学习率lr | epochs | GPU |
| Yolov5 backbone | WIDER FACE train | WIDER FACE val | 0.75 | 16 | 0.0032 | 55 | RTX 3090 |




















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









