







 《Unified Structure Generation for Universal Information Extraction》论文阅读笔记问题与挑战 :这篇文章出现之前,我们进行信息抽取时会遇到抽取目标多样、复杂异构结构、领域需求多变等问题难以解决。本文贡献:提出了一个统一的文本到结构生成框架,即UIE。它可以通用地建模不同的IE任务,自适应地生成目标结构,并从不同的知识源协作学习通用的IE能力。具体方法:UIE通过结构化提取语言对不同的提取结构进行统一编码,通过基于模式的提示机制(结构模式提示器)
《Unified Structure Generation for Universal Information Extraction》论文阅读笔记问题与挑战 :这篇文章出现之前,我们进行信息抽取时会遇到抽取目标多样、复杂异构结构、领域需求多变等问题难以解决。本文贡献:提出了一个统一的文本到结构生成框架,即UIE。它可以通用地建模不同的IE任务,自适应地生成目标结构,并从不同的知识源协作学习通用的IE能力。具体方法:UIE通过结构化提取语言对不同的提取结构进行统一编码,通过基于模式的提示机制(结构模式提示器)
《Unified Structure Generation for Universal Information Extraction》论文阅读笔记
信息抽取大一统
原文链接:https://arxiv.org/pdf/2203.12277.pdf
参考文章:https://zhuanlan.zhihu.com/p/495600185
文章目录
摘要
问题与挑战 :这篇文章出现之前,我们进行信息抽取时会遇到抽取目标多样、复杂异构结构、领域需求多变等问题难以解决。
本文贡献:提出了一个统一的文本到结构生成框架,即UIE。它可以通用地建模不同的IE任务,自适应地生成目标结构,并从不同的知识源协作学习通用的IE能力。
具体方法:UIE通过结构化提取语言对不同的提取结构进行统一编码,通过基于模式的提示机制(结构模式提示器)自适应生成目标提取(通俗讲就是把任务的schema拼接在文本前面作为提示,比如要做NER的话,就把实体的种类放在文本前面作为提示),并通过大规模预训练的文本到结构模型获得常见的IE能力。
实验结果及分析:在4个IE任务、13个数据集以及所有有监督、低资源和小样本学习数据集上都取得了最先进的性能,对于实体、关系、事件和情感提取任务及这些任务的统一都效果很好。
1. 介绍
本小节介绍了IE的短板和作者新提出的UIE解决现有问题的可行性与大概思路。
1.1 IE面临的挑战
- 信息抽取(IE)旨在从非结构化文本中识别和构造用户指定的信息。
- IE的多样化:
| targets | heterogeneous structure | demand-specific schemas |
|---|---|---|
| entity, relation, event, sentiment, etc. | spans, triplets, records, etc | 金融、体育赛事等 |
- 如上表所示,可以看到,传统方法由于IE的多样性面临多种限制,targets多样难以实现高效架构开发,复杂的多样化结构限制了有效知识共享,demand-specific schemas限制了快速跨域适配,IE面临的挑战亟待一个更好的方法。
1.2 UIE应运而生
原文作者在图1向读者整体描述了从(a)任务专用IE:不同的任务、不同的结构、不同的模式到(b)通用IE:通过结构生成进行统一建模
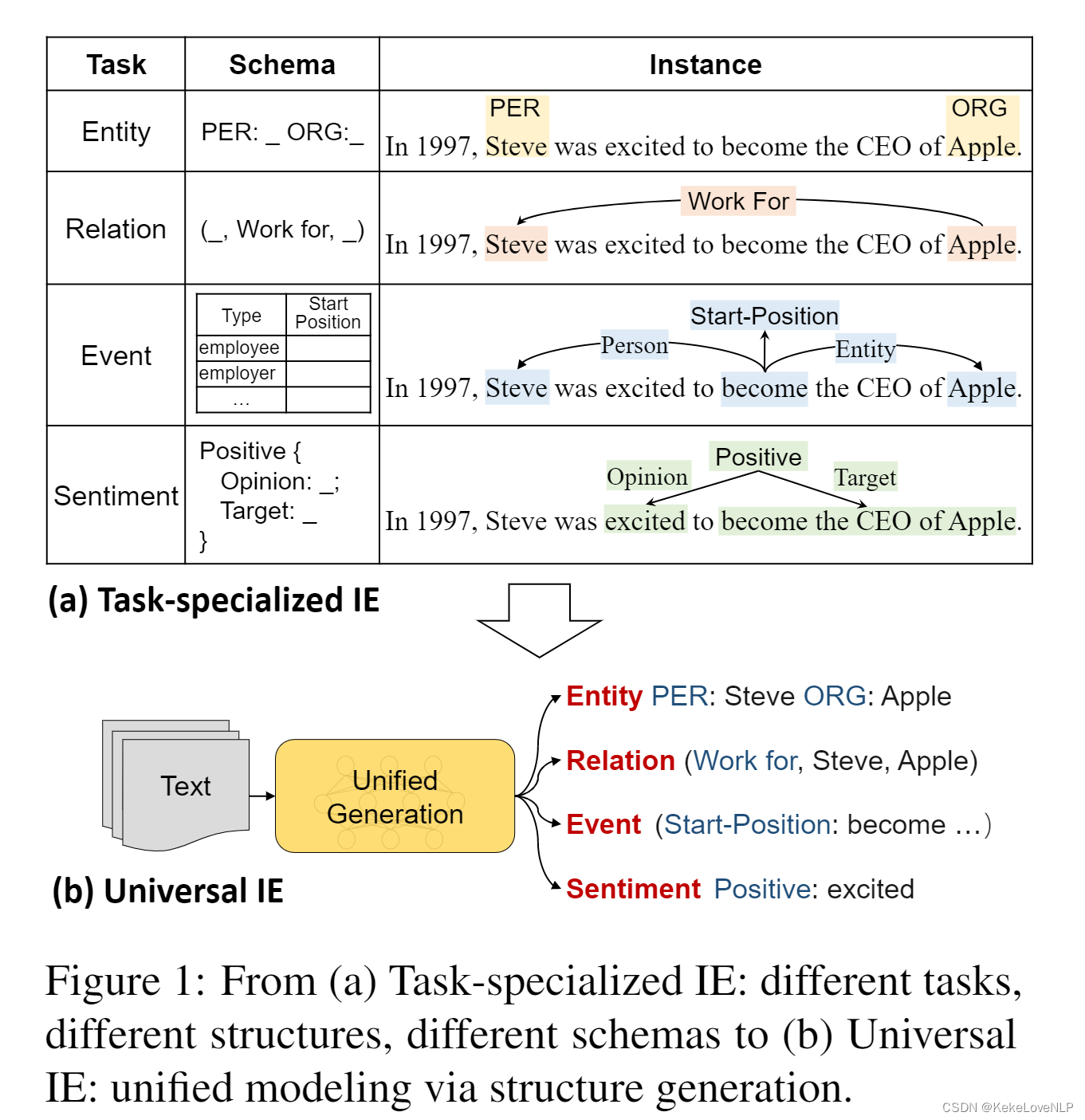
-
对于图一,作者是这样解释的:从根本上讲,所有IE任务都可以建模为文本到结构的转换,不同的任务对应不同的结构,例如,“an entity is a named span structure, an event is a schema-defined record structure”.
-
IE中的这些文本到结构的转换可以进一步分解为几个原子转换操作:
1.第一步是做定位,定位那些想要的span的位置。例如在给定Entity PER的时候,要定位到“Steve”定位,给定sentiment expression要定位到“exc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









