







Unified Structure Generation for Universal Information Extraction
1 研究背景与意义
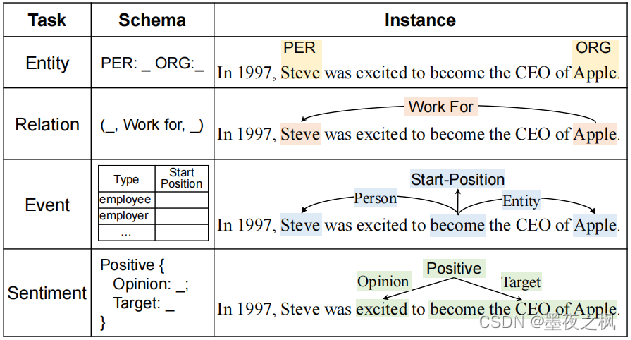
信息抽取(Information extraction, IE)旨在从无结构的自然语言文本中抽取出结构化的信息,但是不同的信息抽取任务都有不同的结构,且差异较大。
左图为信息抽取的四种任务,实体识别任务一般是采用span及其实体类别表示,该示例中抽取了实体Steve其实体类别是Person。关系抽取任务一般采用三元组(triplet)结构表示,Steve和Apple的关系是work for。事件抽取任务一般采用记录(record)表示,触发词become,其类型为Start-Position,Steve和Apple抽取出来的论元,对应的论元角色是雇员和雇主。观点抽取任务采用另一种三元组的形式来表示,观点excited表示成为苹果CEO是一个积极的观点。对于不同的任务,各自拥有不同的结构,不同的模式schema。
事实上,所有的IE任务都可以建模为text-to-structure的转换。本文主要是构建文本到结构的生成框架,它可以普遍地建模不同的IE任务,自适应地生成目标结构。
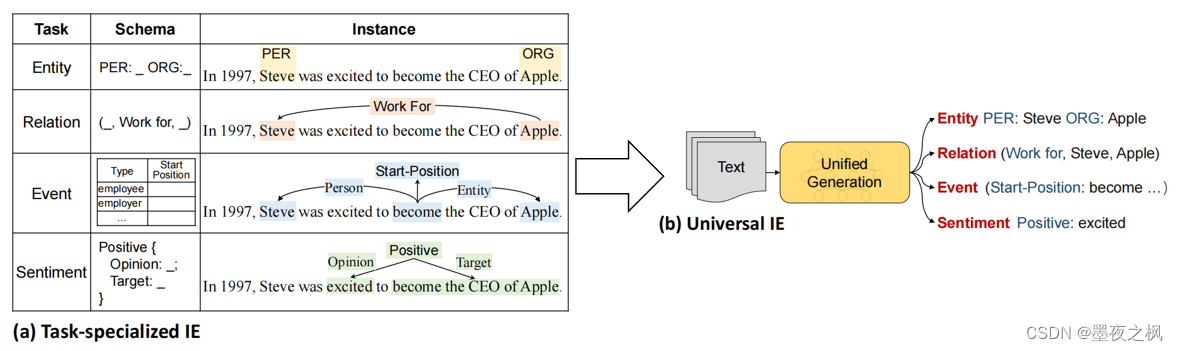
不同的输出结构使得很难对所有信息抽取任务统一化建模,这样就产生了三个问题。
- 第一,为大量的IE任务/设置/场景开发专门的架构是非常复杂的,不同的任务,比如说实体识别、关系抽取、事件抽取、观点抽取,或者不同的设置,像全监督、低资源、少样本、零样本,又或者是不同的作用场景,例如医学、金融等,需要设计大量针对特定情况的模型,极其耗费资源。
- 第二,学习孤立的模型严重限制了相关任务和设置之间的知识共享,不同的任务存在大量可以公用的知识,如关系抽取需要用到命名实体识别的结果,事件抽取中的论元也是实体,而现在存在大量的针对特定任务的模型无法做到共享这些实体知识。
- 第三,构建专门用于不同IE任务的数据集和知识源是非常昂贵和耗时,信息抽取的数据标注是需要耗费大量人力和时间,由于任务之间的独立性,需要分别对每一个任务标注数据。
因此,开发一个通用的IE体系结构,可以统一地建模不同的IE任务,自适应地预测异构结构,并有效地从各种资源中学习,这将是非常有益的。
2 通用信息提取的统一结构生成
如何统一每一个信息抽取任务?
作者主要是使用结构化抽取语言SEL和结构化模式指导器SSI来统一化建模信息抽取任务。其中,SEL可以有效地将不同的IE结构编码为统一的表示,这样各种IE任务就可以在相同的文本到结构的生成框架中普遍建模。为了自适应地为不同的IE任务生成目标结构,提出了SSI,这是一种基于模式的提示机制,它控制着在UIE中发现什么、关联什么以及生成什么。接下来我们详细了解一下SEL和SSI的作用。
2.1 结构化抽取语言(Structural Extraction Language, SEL)
四种信息抽取任务的目标都可以拆解成两个原子操作发现spotting和关联associating。发现是在输入的原句中找到目标信息片段,例如实体识别中某个类型的实体,事件抽取中的触发词,他们都是原句中的片段。关联是找出发现中输出的信息片段之间的关系,比如关系抽取中两个实体之间的关系,或事件抽取中论元和触发词之间的关系。每个信息抽取任务都可以用这两个原子操作去完成,不同的任务只要组合不同的原子操作对应结构就可以统一表示。

这个图是SEL的语法,作者使用三种形式来表示:
- 第一,Spot Name是指目标信息片段的类别,在实体识别中指实体类别,在事件抽取中可以指事件类型和论元角色。
- 第二,Asso Name: 表示在源文本中存在一个特定的信息片段,该信息片段与spotting信息关联;
- 第三,Info Span: 表示spotting和associating定位文本中的具体信息。
接下来简单举几个例子,其中蓝色字体表示发现操作,红色字体表示关联操作,黑色字体表示定位文本具体信息。实体识别中仅使用一层括号表示一个实体和他的类别,其余三种则是采用完整结构表示,虽然结构相同,但是由于是针对不同的任务所以各自表达的含义也是不同的。

2.2 结构化模式指导器(Structural Schema Instructor, SSI)
有了SEL语法,模型统一了不同任务的输出结构。但是当我们输入一个句子后,如何让模型去做我们想要的任务呢?因此作者提出了SSI(Structural Schema Instructor),是一种基于Schema的提示机制。其实可以理解为,当我们输入句子时,在句子前面拼接上对应的Prompt,即可让模型做对应的任务。
对于实体识别,它的Prompt是spot提示符+实体类别。而关系抽取和事件抽取,它是spot提示符+触发词,和associate提示符+关系类别,这种形式可以告诉模型哪些做spotting操作,哪些做associating操作。

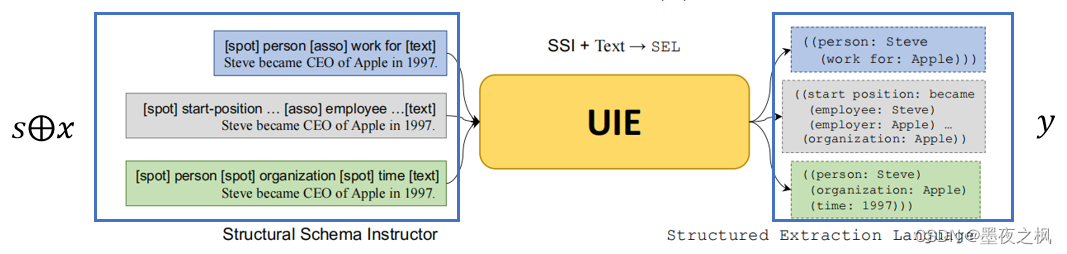
以下完整的UIE模型,可以看到在文本前面添加上这样一个提示机制,将其送入UIE网络中就可以得到相应的结果。
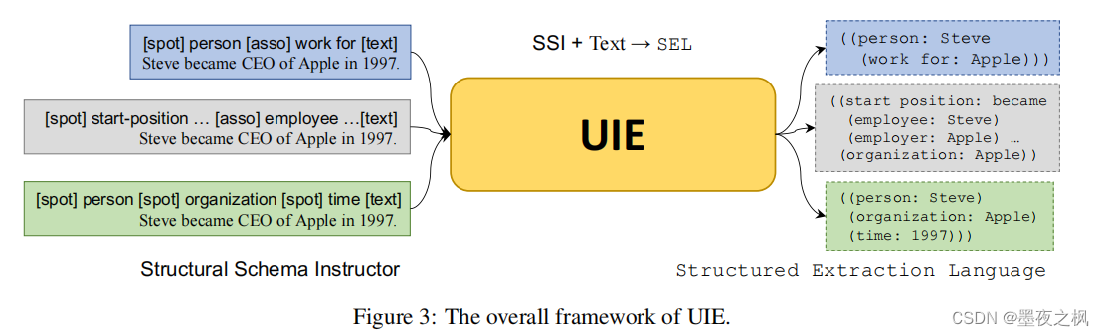
UIE将给定的结构化模式指导器(s)和文本序列(x)作为输入,其中UIE模型是使用transformer来实现的。这个s和x的运算其实就是一个拼接操作。将spot和associate与文本拼接,送入到UIE模型中,输出结构化表示y。这就是完整的输入和输出,以及SEL和SSI的具体作用。

3 预训练与微调
3.1 预训练

预训练数据由三种形式表示,第一种D_pair,是文本到结构的并行数据,直接用于整个文本到结构的预训练中。它同时具有SSI语法表示的s,原始文本x,以及SEL语法的输出y的完整数据。第二种是D_record,具有每个实例的结构化记录的结构数据集,主要是用在预训练的decoder中,将前两部分使用空来填充,最后面SEL的表示y。第三种是D_text,是非结构化的文本数据集,这部分数据主要是实现带掩码的语言模型任务,数据表示为(空,x’是带遮掩的文本,x”是进行遮掩标记的文本)。针对上述三种类型的数据,分别设计了三种预训练任务
针对D_pair,输入数据为SSI+原始文本y,使其生成结构化的数据record,此任务计算的Loss如下:根据x和s条件下得到记录y的概率,再求一个负对数。
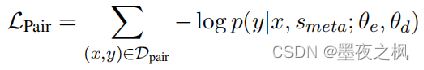
针对D_record,这部分输入只有结构化数据record,输入前面的部分,使其生成剩余部分,并且只训练UIE的decoder部分,使其学会SEL语法,计算的Loss如下:用记录y的前i-1数据生成第i个数据。
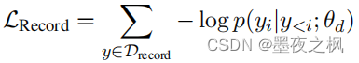
针对D_text,这部分做的是无监督的masked language model任务,类似于T5中的预训练任务,在原始句子中MASK掉15%的tokens,然后生成MASK的部分,计算的Loss如下:这一部分主要是预测带掩码的部分。
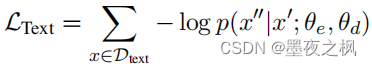
将三个Loss相加作为最终Loss:
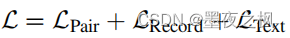
作者并不是分开做这三个预训练任务的,而是将其统一化,全部表示为三元组(s,x,y),其中s是加在输入句子前面的prompt,x是输入的原始句子,y是需要生成的目标句子,在每一个batch中随机抽取每一个任务的数据去训练。D_pair数据表示为(s,x,y),D_record数据表示为(None,None,y),D_text数据表示为(None,x’,x’’),这样无论是哪种任务都是输入一个三元组,即可统一训练。
3.2 微调
微调部分和预训练任务的D_pair类似,数据形式是三元组(s,x,y)的形式,微调的Loss计算方式:
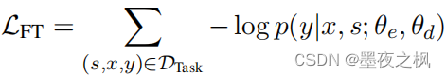
微调部分加入了负样本,如下图所示,表格上部分为输入,下部分为第一行为正样本的输出,第二行为加入了负样本。随机插入一些原标签中没有的信息,即(Spot Name: [NULL])或(Asso Name: [NULL]),图中输入句子中并没有facility的实体,而标签中插入了(facility: [NULL])。将正负样本同时注入,有利于在不同任务中缓解偏差。

4 实验
4.1 全监督实验
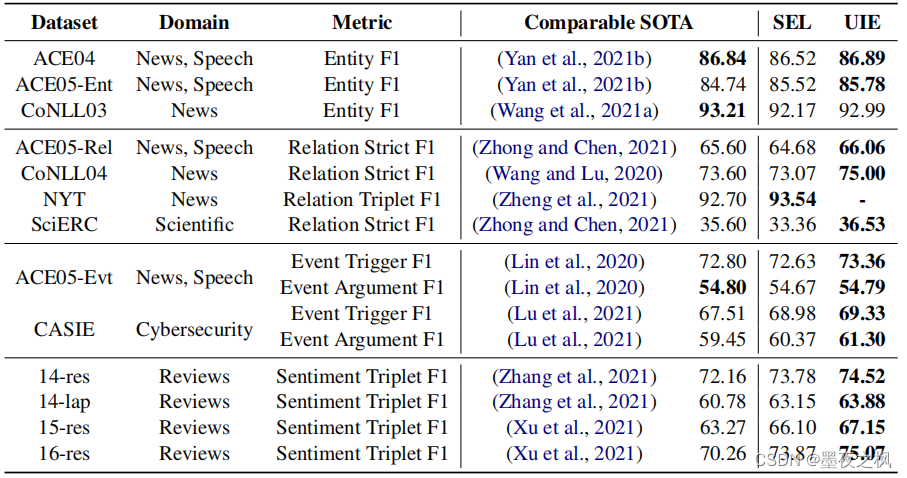
实验结果如图采用了13种数据集在4种任务中的结果展示,最右边的SEL列是指基于T5-v1.1-large进行微调得到的结果,UIE是指构建的UIE-large模型进行微调的结果,可以看到几乎在全部数据集上都取得了SOTA(最优)的结果,但是通过对比SEL和UIE发现预训练部分对结果的提升并不大,通过这个可以看出作者设计的SEL语法和SSI还是很强大的,另一方面也说明T5本身的生成能力就很强大。
4.2 低资源(Low-resource)实验
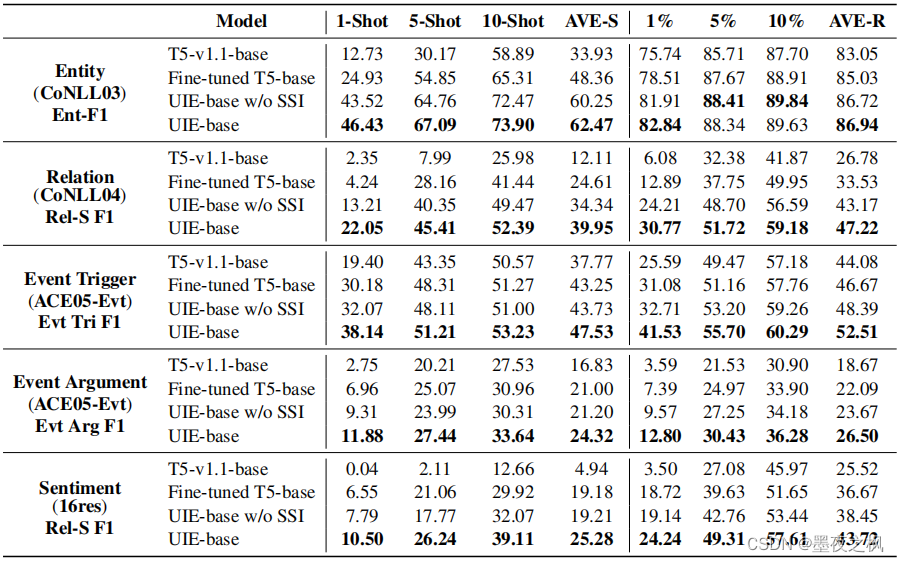
这部分是在6种设置下做的:1/5/10-shot和1/5/10% ratio。因为少样本情况下随机性很大,所以作者在每一个设置下都采样了10次,报告10次结果的平均,结果如图所示,从这个结果中可以看出,UIE真正强大的地方是小样本情况下,泛化能力非常强,远超基于T5的微调结果,在全监督设置下预训练部分的能力没有体现出来,但在低资源下针对性的预训练可以非常好的提升泛化能力。同样,全部任务下都取得了最优结果。
5 总结
提出了一个统一的text-to-structure的生成框架UIE。设计了结构化抽取语言SEL和结构化模式指导器SSI指导模型对不同的任务生成不同的结构。UIE在监督环境和低资源环境下都取得了非常具有竞争力的性能。















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











