






经过昇思MindSpore社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.3版本,其中动态图开发支持算子直调提升API性能,静态图开发支持O(n)多级编译提升调试调优能力,在大模型训练方面,支持大模型场景计算与通信掩盖的极致优化,并新增接口FlopsUtilizationCollector,提供算力利用率统计能力,在大模型推理方面,推出针对LLM的推理优化方案提升推理性能,MindSpore Transformers提升推理性能与易用性,在科学计算套件方面,MindSpore Flow新增偏微分方程基础模型PDEformer和谱神经算子SNO,下面就带大家详细了解下昇思2.3版本的关键特性。
基础框架演进
01 动态图支持算子直调,提升API性能
在昇思MindSpore框架中,大部分的API使用了小算子进行拼接,因此会有额外的Python和算子launch开销。而昇思MindSpore之前版本动态图单算子执行时,使用了单算子子图进行执行,需要进行单算子子图构图,编译优化,算子选择,算子编译等一系列操作,首轮性能较差。针对这两点进行性能优化,昇思MindSpore2.3版本提出了算子直调的方式,即正向算子执行直接调用到底层算子接口,减少整体流程和数据结构转换开销。不同API,性能提升0.5~4倍,SD文生图训练端到端性能提升2倍+。
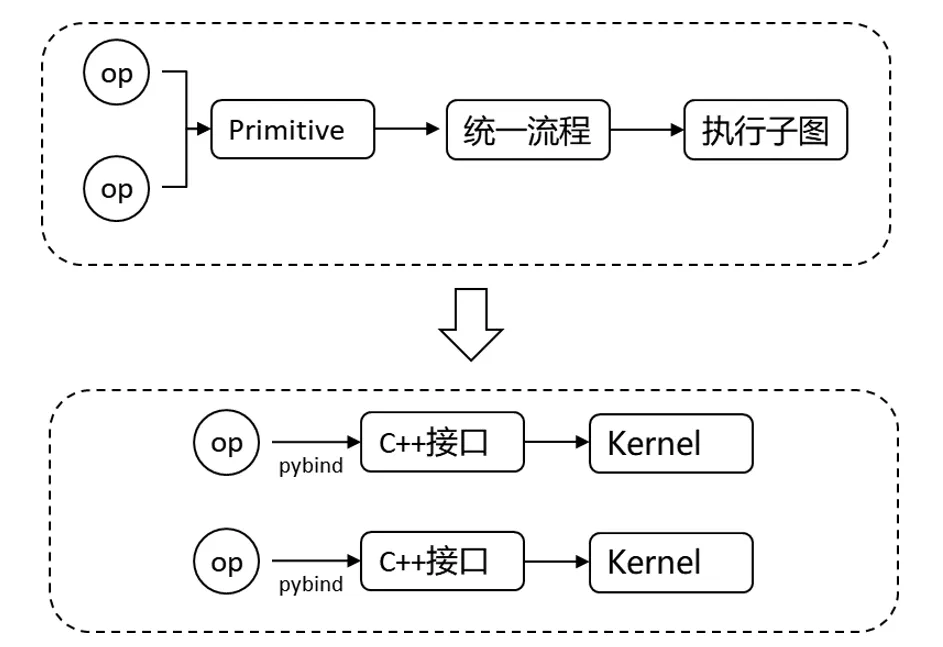
此外,提供了基础分布式能力接口
硬件相关接口(设备管理、流管理、事件管理与内存管理的接口:
https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore.hal.html
重计算接口:
https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.recompute.html
通信基础接口:
https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore.communication.comm_func.html
02 静态图支持O(n)多级编译,默认使用O0模式,提升静态图调试调优能力
整图下沉执行性能最优,但随着大模型的规模和参数量发展得更为庞大,整图下沉执行方式在整图编译过程中耗时较长,为解决上述问题,昇思MindSpore2.3版本提供了多级编译技术,O0原生构图不优化、O1增加自动算子融合优化、O2整图下沉执行优化。
在O0的编译选项下,发挥原生图编译优势,大部分模型编译性能相比O2提升50%+,同时也支持了DryRun功能,用户可以直接在离线的情况进行内存瓶颈分析和并行策略调优,结合这两大技术可以使得大模型调试效率倍增;在内存复用方面,使能了SOMAS/LazyInline/控制流Inline来提升内存复用率,同时落地了虚拟内存碎片整理技术,大大解决了内存碎片导致训练OOM问题;在执行性能方面,使能了计算通信多流并行/运行时流水异步调度技术,同时在O1编译选项下落地了算子融合技术,大大提升执行性能。
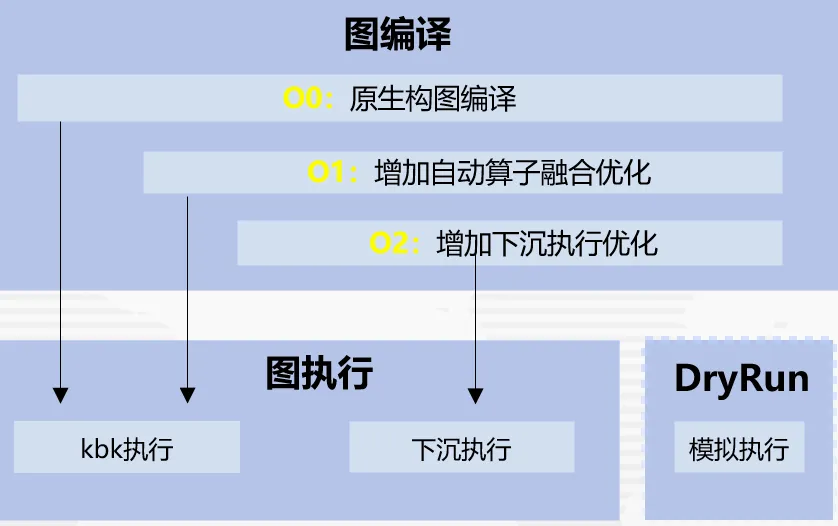
为了体现静态图默认的较好调试调优能力,昇思MindSpore2.3版本中主流训练产品的静态图默认编译选项为O0。
参考链接:
https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.set_context.html?highlight=jit_level
大模型训推能力全面提升
03 大模型计算与通信掩盖极致优化
在过去的版本,针对Tensor并行的通信,昇思MindSpore提出了多副本并行以及反向梯度计算与反向过程Tensor并行的通信掩盖两个技术,大幅面掩盖了Tensor并行的通信,但是在模型规模更大的场景,会针对短序列并行下的AllGather通信进行重计算,这一部分重计算的通信往往无法有效的再被MatMul掩盖。针对这一部分通信,昇思MindSpore2.3版本通过有效调整执行时机,使其与FlashAttention的反向算子进行相互掩盖,达成计算与通信的极致掩盖。
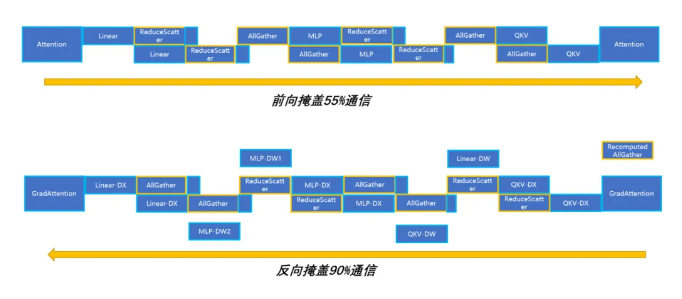
04 新增接口 FlopsUtilizationCollector,提供算力利用率统计能力
在进行大模型训练时,算力利用率通常作为大模型训练框架的性能指标,显卡资源的利用率会直接影响训练大模型的成本。业界普遍使用 MFU(Model FLOPS Utilization)模型算力利用率和HFU(Hardware FLOPS Utilization)硬件算力利用率指标来评估显卡设备的算力利用率。昇思MindSpore2.3版本新增callback接口FlopsUtilizationCollector,方便用户在每个epoch结束时获取MFU和HFU信息。
详情参考:
https://www.mindspore.cn/docs/zh-CN/master/api_python/train/mindspore.train.FlopsUtilizationCollector.html
05 针对大模型推理的算法及算子优化,提升推理性能
昇思MindSpore 2.3版本推出针对LLM的推理优化方案,除在框架层面使用静态图编译模式优化计算图、通过kernel by kernel调度方式降低模型编译耗时外,还结合了金箍棒的量化模型压缩算法、业界主流Flash Attention、Paged Attention算法、算子融合等加速技术,降低显存同时提升大模型推理性能。
5.1 金箍棒模型压缩算法助力LLM推理降本增效
LLM推理过程中对于显存有巨大的需求,金箍棒新支持RoundToNearest权重量化算法,通过将网络中线性层的权重从浮点域量化到整型域,在计算时再反量化到浮点域进行计算,能够显著节省LLM推理的显存开销,同时能缓解LLM增量推理阶段的Memory Bound问题,从而带来一定的性能提升。RoundToNearest权重量化算法是一种training-free和data-free的量化算法,同时由于LLM的权重相对规整(相较于激活而言),较易量化,是一种使用成本较低的无损量化技术,同时能带来显存和性能的收益。
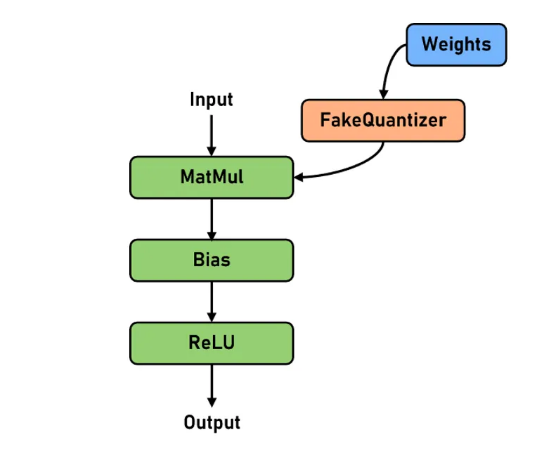
我们对Llama2系列网络进行了测试,网络参数普遍压缩40%以上,精度几乎无损,推理性能提升最高可达15%。
详情参考:https://www.mindspore.cn/golden_stick/docs/zh-CN/master/ptq/round_to_nearest.html
5.2 昇腾高性能融合算子实现LLM推理极致性能
昇思MindSpore2.3支持主流Transformer优化算法及跨边界算子融合技术,并充分利用昇腾芯片的矩阵/向量计算单元(简称Cube/Vector)、多层级缓冲区等硬件架构,开发昇腾硬件亲和的后端计算实现,以满足LLM推理场景对低时延、高吞吐的性能需求:
(1)Attention融合优化:在FlashAttention、PagedAttention优化算法配合KVCache缓存机制的基础上,针对昇腾芯片特性重新设计Tiled Attention算法:最大化利用Cube/Vector间缓冲区高带宽,减少数据搬移量与向量运算量;通过构建多级流水大幅降低核间等待时间,实现流水并行最大化;在分组查询注意力机制(Grouped Query Attention)下对query进行重组计算,进一步提高算子性能。
(2)旋转位置编码:Rotary Position Embedding(简称为RoPE),结合绝对位置编码与相对位置编码的思想,通过乘以旋转矩阵为token赋予位置信息,并能更好地利用上下文token信息。MindSpore在此版本,通过简化计算逻辑、优化位置编码的数据排布方式,提供高性能的RoPE融合算子,并在算子实现中最大化昇腾芯片Unified Buffer利用率。
(3)矩阵乘与向量计算融合优化:LLM中存在大量矩阵乘计算,昇思MindSpore2.3在编译阶段进行图上融合优化,配合高性能的算子实现,达到矩阵乘性能极致提升。算子内充分考虑流水线并行优化,减少等待气泡,使计算时间尽可能被数据搬运时间掩盖;对于矩阵乘数据访问通过Swizzle方式进行调度重排,提升数据Cache命中率并提高整体访存效率;利用昇腾Cube/Vector并行特性,支持若干矩阵乘的后向融合计算,节约向量部分计算耗时。除矩阵乘外,昇思MindSpore将LLM模型中相邻的Element-wise、Normalization、Reshape类算子进行融合,能够降低数据搬运的内存开销、简化运行时流水,加速推理计算。另外,此版本在算子优化上,探索了基于张量语言模型的调优技术,实现算子内切分等关键配置自动寻优,构建高性能切分数据库,提升LLM融合算子性能。
06 MindSpore Transformers:提升推理性能与易用性,支持超长序列训练
MindSpore Transformers(后简称MindFormers)发布1.2.0正式版本,新增支持多个业界主流大模型,进一步提升套件易用性。
6.1 带框架推理和服务化部署:提升大模型推理易用性和性能,满足服务化需求
MindFormers 1.2.0版本支持昇思MindSpore带框架推理,目前已支持LLaMA2、LLaMA3、GLM3、Mixtral、Baichuan2、InternLM2等主流大模型的高效推理,最大序列长度可达32k。统一训推并行策略接口、封装推理加速接口,实现从训练到高性能推理的平滑迁移,整体部署周期下降到天级。
MindFormers 1.2.0版本全面对接MindIE服务化部署框架,套件中的主流LLM均已支持服务化推理。通过MindIE提供的标准昇腾服务化接口,兼容Triton/OpenAI/TGI/vLLM等第三方框架接口请求方式;通过Continuous Batching等调度策略,尽可能消除冗余计算,确保算力不闲置,提升大模型推理吞吐性能;支持重计算/Swap功能在保证在在大并发、长序列场景服务不中断。
6.2 支持超长序列训练:助力便捷高效地训练超长上下文
从生成性AI到科研模型,长序列训练正在变得非常重要。现有的数据、张量和流水线等并行方法无法在序列维度进行切分。当序列维度(S)增长时,训练内存开销会以O(
![]()
)的速度增长。因此需要针对长序列场景进行特定的优化解决长训练场景的训练需求,昇思提供了一种显存高效的序列并行方法和attention mask压缩特性,极大地降低了输入序列长度限制,能够有效地支持超长序列的训练。
并行方法在序列维度进行切分,每台设备只负责1/CP的Q和KV进行自注意力值计算,不再需要单个设备来保存整个序列。注意力矩阵与序列长度由平方关系,变成线性关系。有效降低每台计算设备显存压力。同时,该方法与大多数现有的并行技术兼容(例如:数据并行、流水线并行和张量并行)。
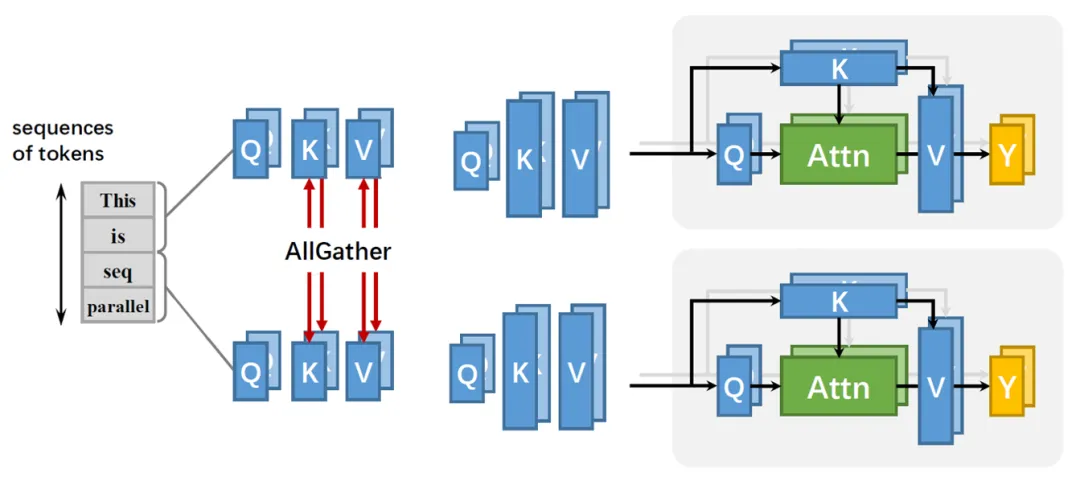
attention_mask压缩是对Self-Attention中的Score矩阵进行掩码操作,它的内存大小跟
![]()
呈正比。例如在32k序列下,单个uint8类型的attention_mask矩阵会占用1GB的显存,使能后传入的attention_mask为优化后的压缩下三角矩阵(2048*2048)。除内存收益外,有些网络会在device上生成attention_mask矩阵,attention_mask压缩能够有效地避免生成超大矩阵带来的性能开销。
科学计算套件增强
07 MindSpore Flow:新增偏微分方程基础模型PDEformer和谱神经算子SNO
7.1 偏微分方程基础模型PDEformer
PDEformer是一种可以接受任意PDE形式作为直接输入的神经算子模型,通过生成 PDE 计算图、编码图数据、解码求解的技术路线以达到快速、精准求解大多数一维 PDE 的目的。PDEformer-1 经过在大规模一维 PDE 数据上进行的预训练,在训练数据分布内 Zero-shot 预测精度高于针对某一种方程专门进行训练的专家模型(如 FNO、DeepONet)。针对训练集以外的数据分布,PDEformer-1 还表现出了出色的小样本学习(few-shot learning)能力,能通过少量的样本迅速泛化到新的下游任务。与此同时,PDEformer-1 还可以作为正问题算子的代理模型直接运用到反问题中。
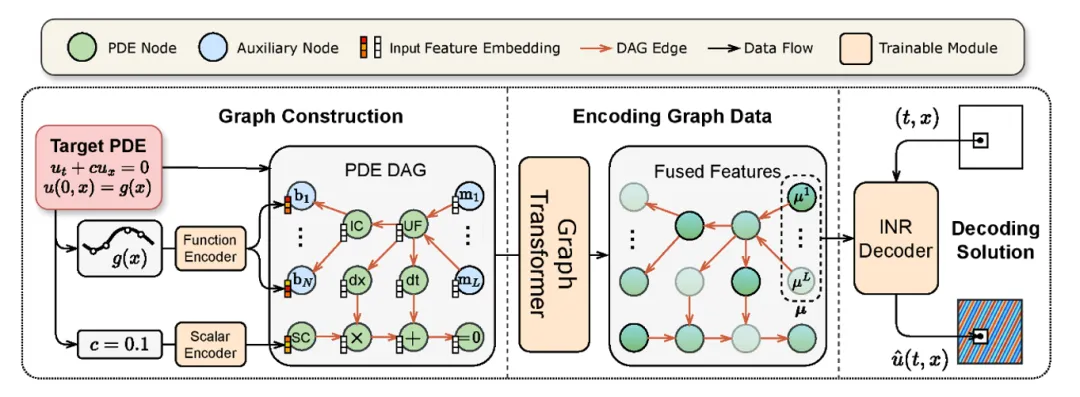
详情参考:https://gitee.com/mindspore/mindscience/tree/master/MindFlow/applications/pdeformer1d
7.2 谱神经算子SNO
谱神经算子(Spectral Neural Operator,SNO)是利用多项式将计算变换到频谱空间(Chebyshev, Legendre等)的类似FNO的架构。与FNO相比,SNO的特点是由混淆误差引起的系统偏差较小。其中最重要的好处之一是SNO的基的选择更为宽泛,因此可以在其中找到一组最方便表示的多项式。此外,当输入定义在在非结构化网格上时,基于正交多项式的神经算子相比其他算子更有竞争力。
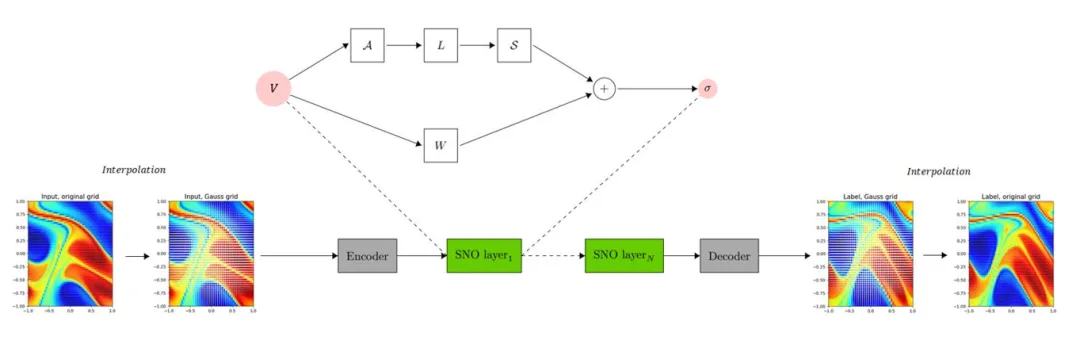
详情参考:https://gitee.com/mindspore/mindscience/blob/master/MindFlow/mindflow/cell/neural_operators/sno.py















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









